
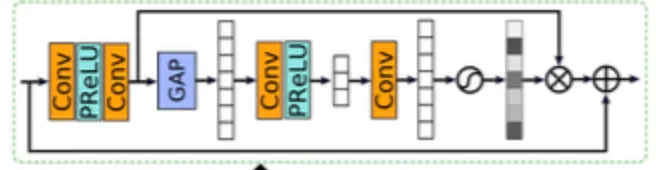
MPRNet의 CAB 구조에 보이는 PReLU
딥러닝 네트워크에서 activation function으로 필수적으로 사용되어온 ReLU
이를 개선한 것 중 하나이다
•
ReLU
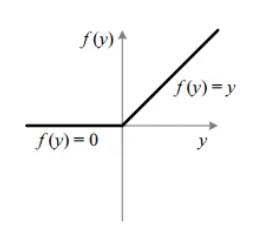
음수의 값을 모두 0으로 만듬
양수에서의 gradient 1, 음수에서의 gradient 0
•
Leaky ReLU
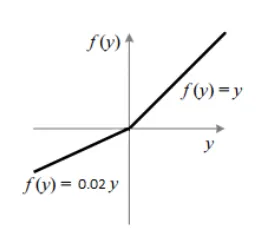
음수에서도 작은 값의 gradient 발생(그림에선 0.02)
ReLU보다는 음의 값에 대해서도 작은 값의 gradient가 발생할 수 있도록 해줌
•
PReLU
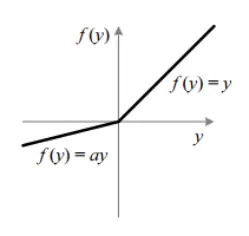
음수에 대한 gradient를 a라는 변수 로 두어 ‘학습'을 통해 ‘업데이트' 시키는 것이다
pytorch에서는 nn.PReLU로 사용 가능하다
def __init__(self):
super(Net, self).__init__()
self.conv1_1 = nn.Conv2d(1, 32, kernel_size=5, padding=2)
self.prelu1_1 = nn.PReLU()
Python
복사
