
JPEG 형식에 있는 motion blur image는 motion blur 와 JPEG artifacts를 모두 가지고 있다.
그래서 blurred되었으면서 JPEG-compressed된 이미지는 복원하기가 어렵다.

JPEG artifacts 예시. 노이즈같은게 보인다
이 문제를 해결하기 위해 두가지 방법을 제안
1.
wide receptive field and channel attention network : WRCAN
: 큰 receptive field를 사용하고, 피쳐맵 채널간의 interdependencies( 상호 관계 ) 를 고려한다
2.
JPEG auto-encoder loss
: WRCAN이 JPEG compression artifacts 의 prior knowledge를 배울 수 있도록 해준다. 그로인해 WRCAN이 JPEG-compressed images로부터 original image를 효과적으로 복원할 수 있도록 해준다
제안된 방법은 Image Deblurring Track 2 JPEG 아티팩트에 대한 NTIRE 2021 워크숍 챌린지에 참여하여 JPEG-compressed REDS dataset에서 평가됩니다. 제안된 손실로 훈련된 WRCAN은 REDS 테스트 세트에서 29.60dB의 출력으로 3위를 차지했으며, 이는 제안된 방법이 최첨단 결과를 제공한다는 것을 나타냅니다.
전체적인 구조
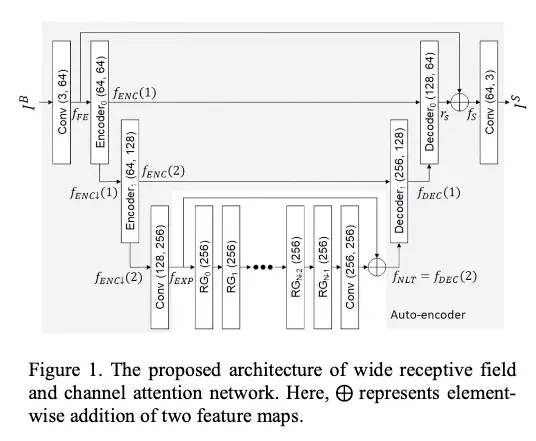
pixel shuffle?
3.1. WRCAN
전체적인 구조
Unet구조를 베이스로 따른다
따라서 pooling operation 덕분에 감소된 연산수로 상당한 수의 파라미터를 다룬다
게다가 WRCAN은 output image를 skip connection을 통해 높은 해상도의 input이미지의 context를 포착해 정확히 localize 한다.
...
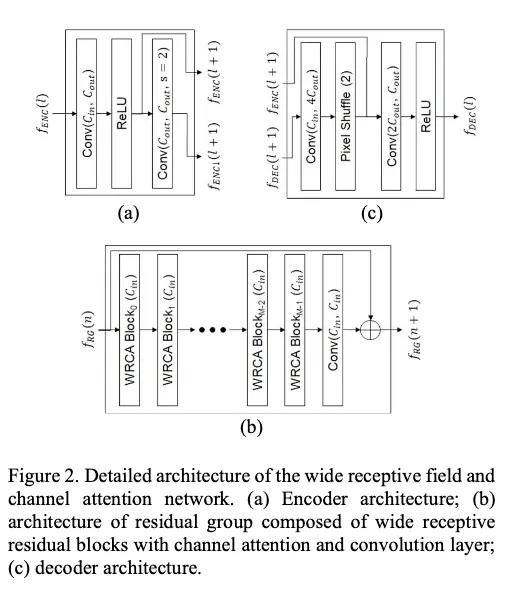
Wide receptive residual block with channel attention (WRCA)
WRCAN의 RG(Residual Group)를 구성하는 basic block인 WRCA에 대해 다룸
WRCA의 목적은 WRCAN이 큰 receptive field에서 피쳐를 뽑고, 그렇게 추출된 피쳐에서 중요한 채널을 강조하도록 하기 위한 것이다
•
평행의 atrous convolution이 있는 residual block은 다양한 receptive field에서 feature를 추출하는데에 효과적이라고 알려져있다
•
channel attention mechanism은 피쳐맵의 중요한 채널들을 강조한다고 알려져있다
두 아키텍쳐의 장점을 사용하기 위해, residual block with parallel atrous convolution + channel attention mechanism 두가지가 WRCA로 결합됐다
그 결과로, 각 RG블럭 안의 일련의 WRCA들은 큰 이미지 영역에서 중요한 피쳐들을 뽑아낸다
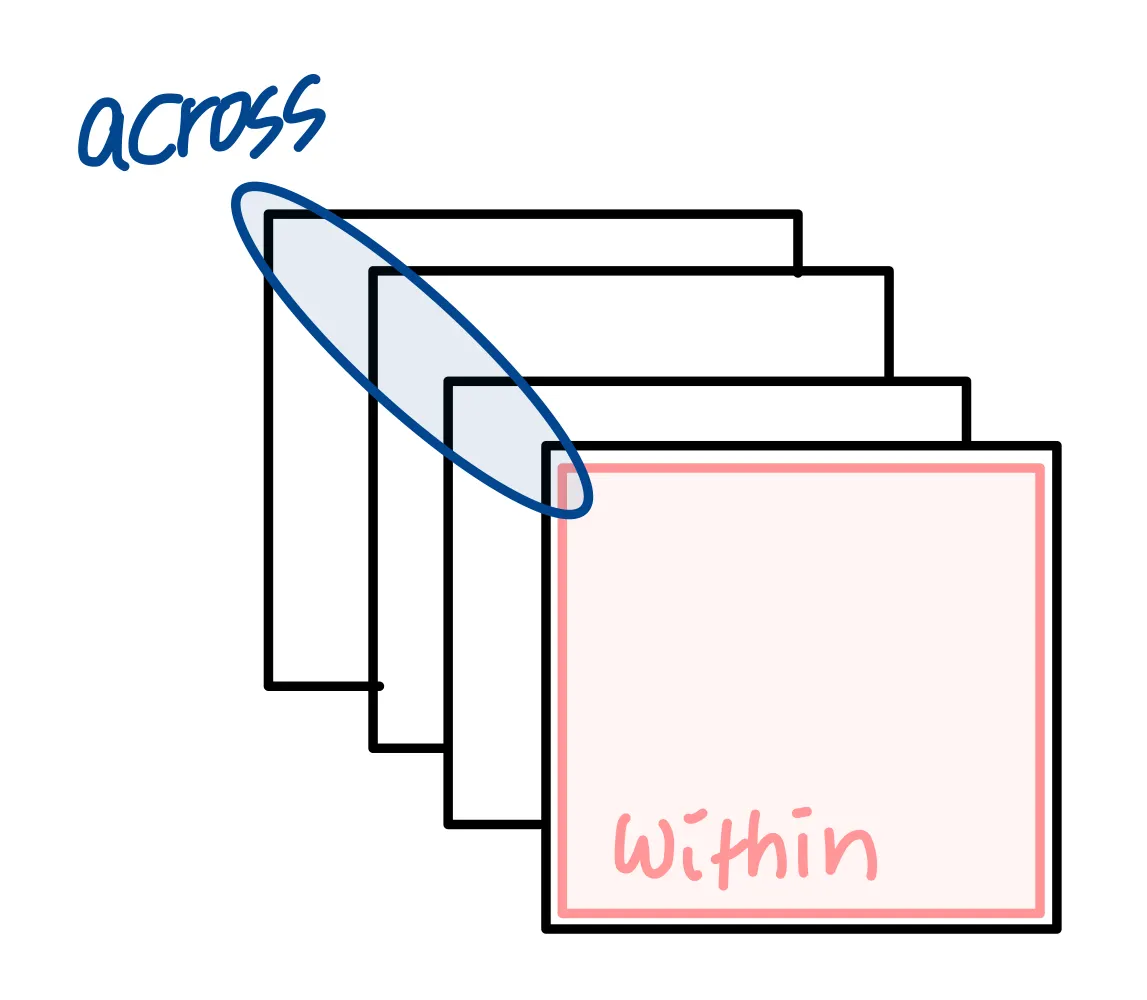
다른말로, WRCAN은 피쳐맵을 피쳐맵채널 across로도 사용하고, within으로도 사용한다
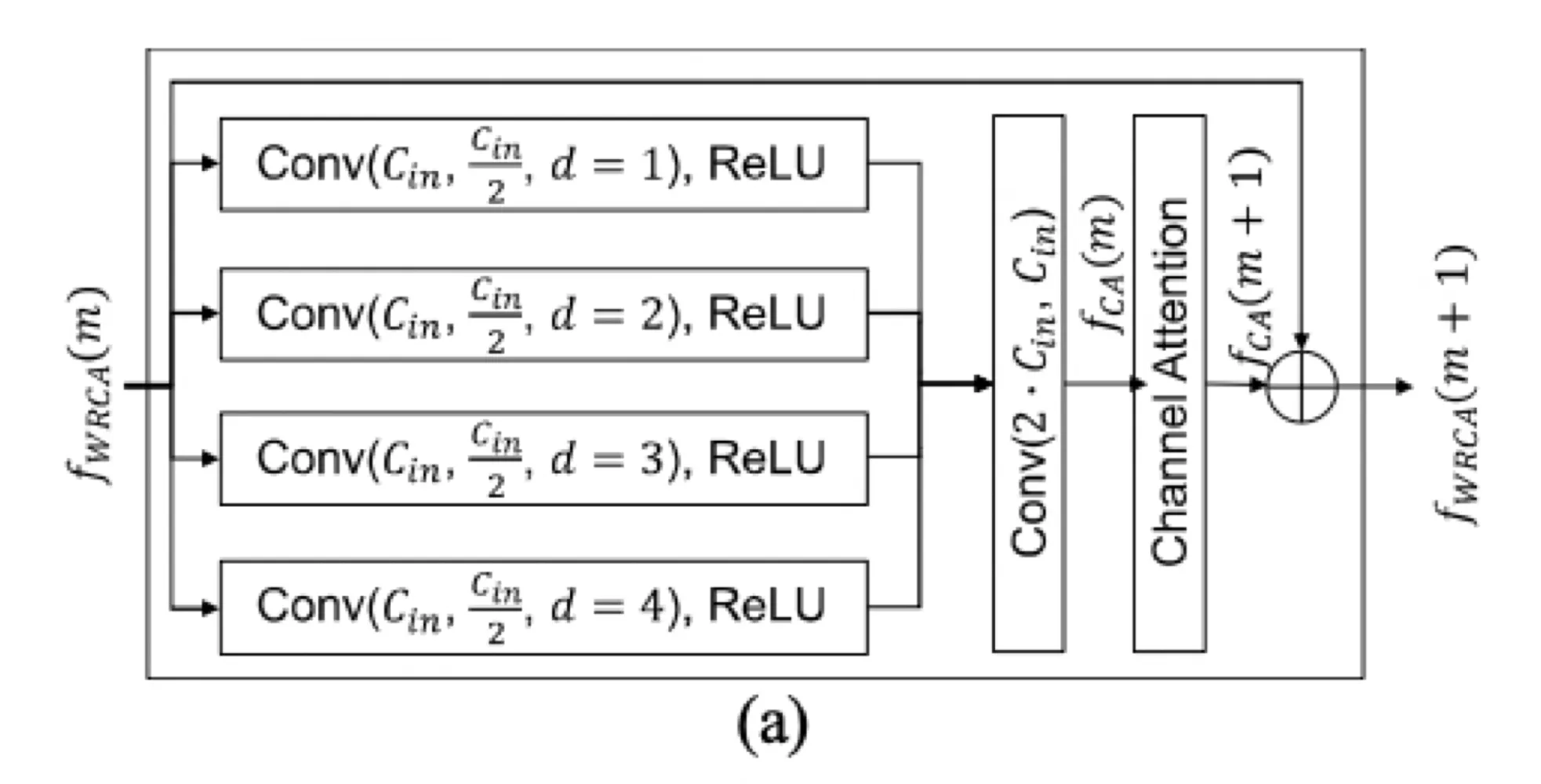
WRCA구조
[ 전체적인 구조 정리 ]
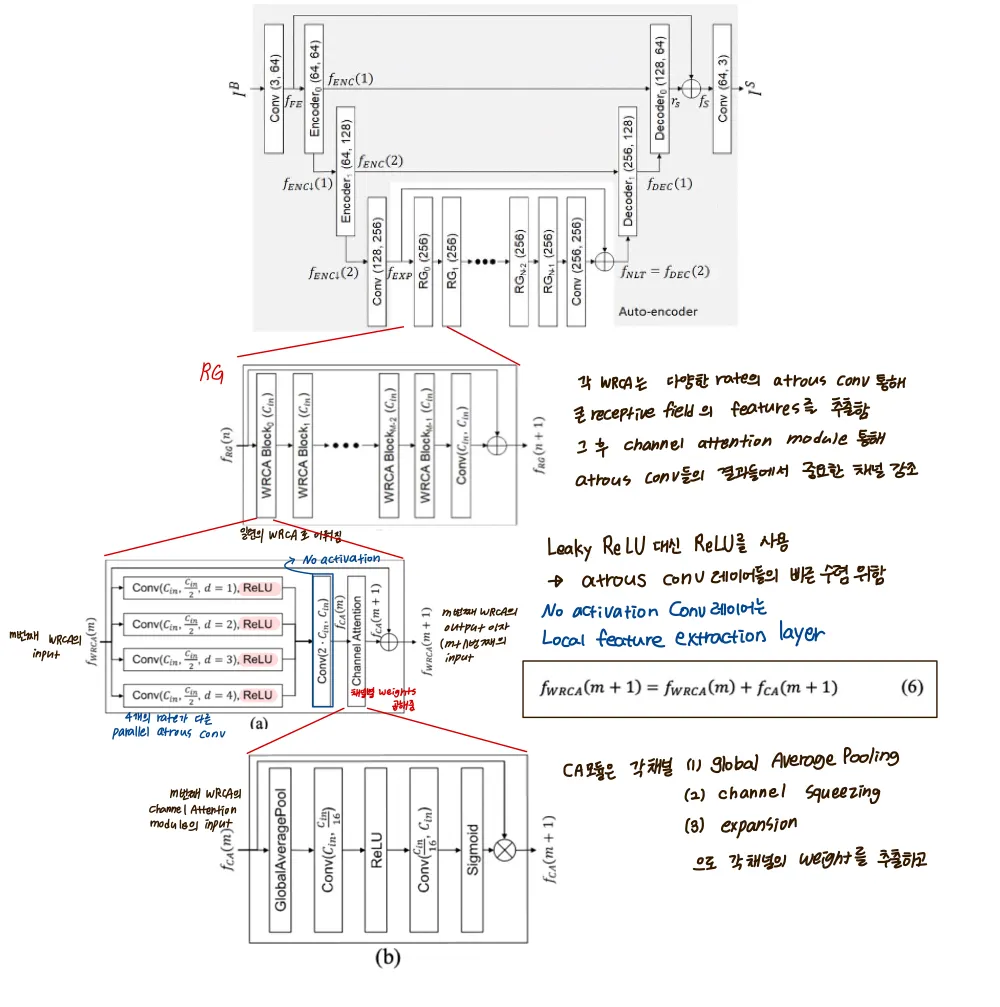
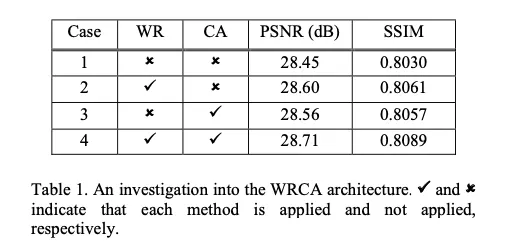
Table 1은 WRCA아키텍쳐의 연구를 보여준다, [REDS Dataset의 validation set에서 PSNR과 SSIM 측정]
Case 1: residual block of [40], RG수가 1, 300 ep 학습, L1 Loss
Case 2 : residual block에 WR과 CA 중 WR만 사용
Case 3 : WR과 CA 중 CA만 사용
Case 4: WR, CA 둘 다 사용 - 2와 3보다 성능이 높은 것을 확인할 수 있다.
RCA-ASPP의 목적과는 다르다고 언급 [41]논문
RCA-ASPP : depth maps와 color guidance images의 misalignment를 해결하기 위함
Training Details
REDS Dataset
여러 data augmentation
•
random horizontal flips
•
rotations
•
과 의 RGB 채널 랜덤하게 0.5확률로 permute
•
표준편차 2의 가우시안 랜덤 노이즈가 0.5확률로 적용
•
augmentation 이후 [0,1]로 normalization
•
batch size : 16
•
patchsize (256, 256)으로 400epoch
•
or
•
patchsize (320, 320)으로 375 epoch
•
patch는 한 이미지에서 랜덤하게 짤리며 1epoch에 24000쌍(blur, target)의 patch가 생성
•
initial lr : 1e-4, 100, 200, 250, 300, 350 ep 에서 반으로 줄어듬
•
weight decau 1e-8(when is applied)
•
Adam optimizer
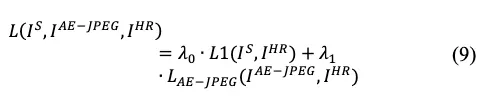
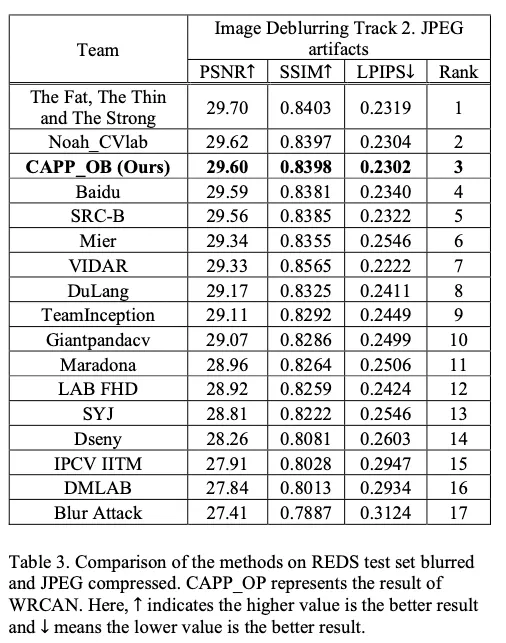
3등. 1등은 HINet
2등은 transformer 계열
WAB Block 코드
class WABBlock(nn.Module):
def __init__(
self, conv=nn.Conv2d,
n_feats=256, kernel_size=3, dilates=4, stride=1,
bias=True, bn=False, act=nn.LeakyReLU(negative_slope=0.2, inplace=True),
channel_attention=False, reduction=16,
res_scale=1.0):
super(WABBlock, self).__init__()
self.dilates = dilates
self.stride = stride
self.res_scale = res_scale
m_dilated_parallel = []
for i in range(dilates):
m = []
dilation = i+1
padding = ((kernel_size-1)*dilation+1)//2
m.append(conv(n_feats, n_feats//2, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, bias=bias))
if bn:
m.append(nn.BatchNorm2d(n_feats))
m.append(act)
m_dilated_parallel.append(nn.Sequential(*m))
m_shrink = [conv((n_feats//2)*dilates, n_feats, kernel_size=kernel_size, padding=kernel_size//2)]
m_channel_attention = [CALayer(n_feats, reduction, act) if channel_attention else nn.Identity()]
self.dilated_parallel = nn.ModuleList(m_dilated_parallel)
self.shrink = nn.Sequential(*m_shrink)
self.channel_attention = nn.Sequential(*m_channel_attention)
def forward(self, x):
res = []
for i in range(self.dilates):
res.append(self.dilated_parallel[i](x))
res_cat = torch.cat(tuple(res), dim=1)
res_cat = self.shrink(res_cat)
res_cat = self.channel_attention(res_cat)
res_cat = self.res_scale*res_cat ## residual_scaling
if self.stride == 1:
x = res_cat + x
else:
x = res_cat + F.avg_pool2d(x, 3, self.stride, padding=1)
return x
Python
복사
