
Introduction
CLIP은 OpenAI에서 개발한 image와 text의 joint embedding space를 학습하는 모델이다. DALL-E 서비스에 사용된 것으로 알려져있다.
DALL-E
CLIP은 이미지와 텍스트의 의미 있고 robust한 표현을 shared embedding space에서 학습하도록 설계되었다.
⇒ 이미지와 텍스트의 joint embedding을 학습.
즉 비슷한 개념을 담고있는 이미지와 텍스트는 embedding space 내에서 가깝다는 것이다.
AI 모델의 자연어와 이미지 이해의 차이를 해결해주었다.
CLIP은 natural language로 image representation을 supervision하는 supervised learning이라고 할 수 있다.
이러한 시도는 처음 있는 것이 아니다.
•
ConVIRT
◦
CLIP 에서 사용한 방식
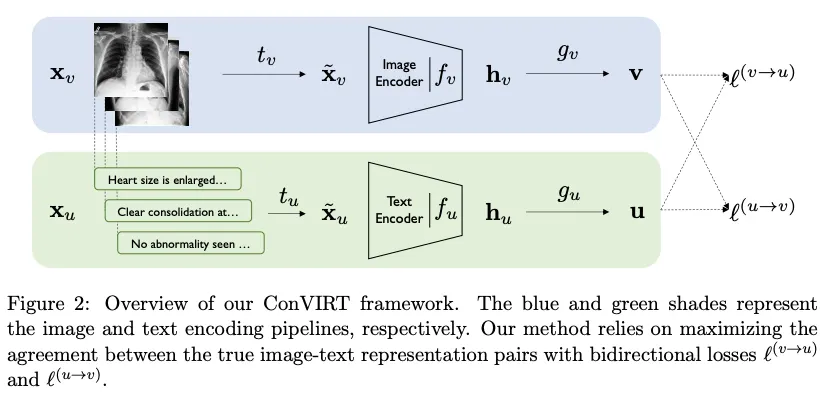
g_v는 non-linear projection
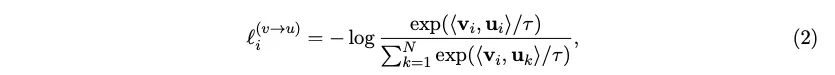
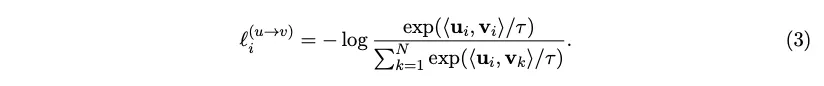
•
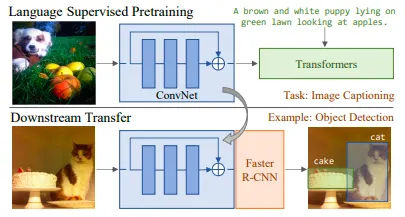
VirTex
◦
language supervised pretraining, downstream trasfer 두 단계로 이루어짐
◦
language supervised pretraining : image captioning
◦
downstream task : object detection
•
ICMLM
◦
naver labs europe
◦
ECCV 2020
◦
일반적인 masked language model을 기반으로 이미지의 conv net features를 결합하여 학습
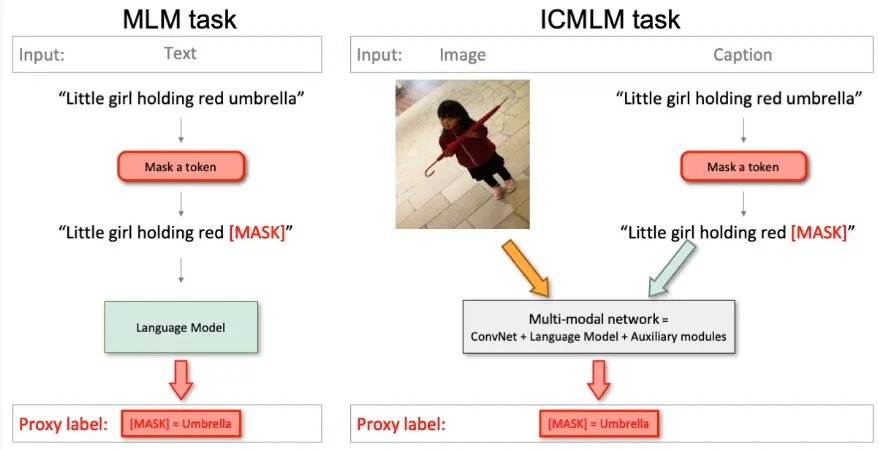
Figure 2: Illustration of the masked language modeling (MLM) and image-conditioned masked language modeling (ICMLM) tasks. Our work builds on MLM - which has become standard in natural language processing - to extend it to the visual domain, enabling the creation of strong and generic visual representations.
그러나 성능이 잘 나오지 않았고, 오히려 weak supervision (대부분의 self-supervision 방식을 말하는 듯 하다) 방식이 좋은 성능을 보였다고 한다.
•
ex. 인스타그램 이미지들의 관련 해쉬태그 예측을 pretraining task로 사용한 후 (단, ImageNet 데이터와 관련이 있는 것들만) ImageNet에 대해 fine-tuning
논문에서는 이러한 방식은 제한된 좋은 labeled data로 학습하는 것과 방대한 양의 raw texts로 학습하는 것의 중간 즈음의 방법이라고 하면서, 더 넓은 visual concepts를 자연어의 generality를 이용해 학습시킬 수 있다고 했다.
이 말처럼, CLIP은 매우 큰 dataset을 새로 구축하여 simplified ConVIRT로 좋은 성능의 joint embedding space의 학습을 성공했다.
CLIP
Large pretraining dataset
natural language supervision이 주된 동기는 인터넷에 사용 가능한 image-text pairs가 매우 많이 존재한다는 점이다. ⇒ 풍부한 데이터로 기존 labeled data의 한계를 넘어설 수 있다!
따라서 기존 dataset만을 사용하는 것은 이 가능성을 충족시키지 못하기 때문에 새로운 400 milion의 image-text pairs를 새로 구축하였다.
결과적으로 GPT-2를 학습시킬 때 사용한 WebTeXt dataset과 비슷한 수의 total words를 구축할 수 있었다고 하며 WIT(WebImageText) 라고 명명했다.
Efficient Pre-training
앞에서 말했듯이 이러한 연구가 처음 이루어진 것이 아니기 때문에 다양한 기존 연구들을 비교해보았다고 한다.
가장 중요했던 것은 연산량이었다. 매우매우 많은 데이터에 대해 학습을 수행해야 하기 때문이다. 그러나 대부분의 방식이 이러한 문제가 있었다.
1.
연산량이 너무 많다.
2.
특정 단어를 예측하는 방식으로 학습이 된다.
⇒ 이러한 방식으로 학습을 하면 이미지와 짝지어진 설명의 매우 넓은 다양성 때문에 학습이 잘 되지 않을 수 있다. 저자들은 whole text를 가지고 학습하는 방식을 찾고 싶어 했다.
1번 관점의 비교를 위해서 Fig.2에서 bag-of-words prediction과 여기서 prediction을 위한 objective를 contrastive objective로 교체한 bag-of-words contrastive의 효율성을 비교했다.

contrastive objective를 사용한 것이 zero-shot transfer to ImageNet에서 4배 이상의 효율성을 보여줬다.
CLIP은 이를 이용해 simplified ConVIRT 방식으로 pretraining을 수행했다.
[CLIP의 pretraining method]


W_i와 W_t가 각각 이미지와 텍스트의 linear projection 을 위한 weight이다.
•
N 개의 pairs로 이루어진 mini-batch가 주어진다.
•
image → image encoder → image linear layer → image embedding
text → text encoder → text linear layer → text embedding
•
image embedding과 text embedding을 L2 normalize 한 후 dot product를 통해 cosine similarity를 연산한다.⇒ 이것이 logit값이 된다. NxN의 형태를 가진다
•
logit값은 temperature (pseudo code에선 t)로 scaling되는데, 이는 softmax값의 범위를 조정하는 효과이며, hyper-parameter 추가를 피하기 위해 학습되는 log-parameterized multiplicative scalar로 지정했다.
•
이 logit값들에 대해 symmetric cross entropy loss, 즉 이미지 기준, 텍스트 기준으로 axis만 다르게 하여 cross entropy를 연산하여 그를 minimize하는 방향으로 학습한다.
[ConVIRT와의 차이]
ConVIRT에 대해서 간단히 살펴보면서 CLIP은 어떻게 변형시켰는지 살펴본다.
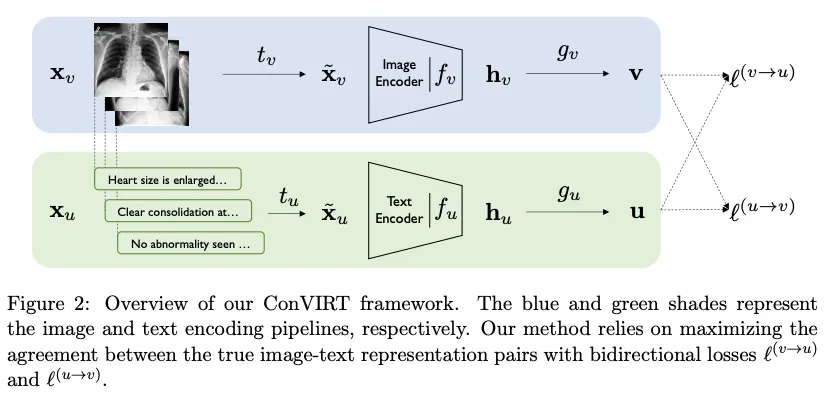
g_v는 non-linear projection
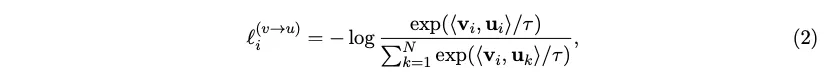
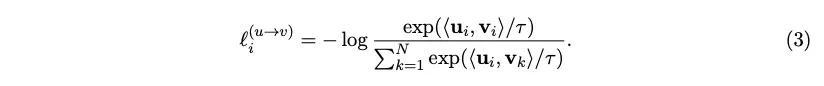
•
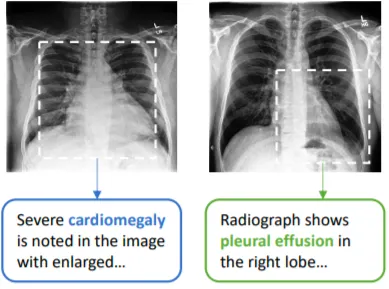
ConVIRT는 메디컬 이미지를 사용한 논문이기 때문에 데이터가 매우 작은 경우에 대한 연구이다.
•
medical image(X-ray, CT)등에 짝이 되는 text report가 있다는 가정하에 진행된다.
•
의료 이미지의 라벨링은 비용이 많이 들거나 정확도가 떨어지는 문제가 있기 때문에, text를 사용해서 unlabeled image data를 유용하게 사용하고자 했다.
•
위 그림과 같이 이미지 상에서는 유사해보여도 text 상에서는 차이가 있기 때문에 pairing을 잘 하면 좋은 데이터로 사용할 수 있다. ⇒ 풍부한 text 데이터 이용
•
InfoNCE Loss로 학습하기 때문에 positive 인 text-image pair는 높은 similarity를 보일 것이다.
추가로 bidirectional 로 학습하기 때문에 image→text loss 뿐 아니라 text→ image loss도 학습된다.
•
라벨이 적은 경우 (10%라벨만 사용해 실험) ImageNet pretrained weights로 fine-tune한 것 보다 좋은 성능을 보였다 ⇒ good data efficiency
ConVIRT → CLIP
•
ImageNet pretrained weight에서 fine-tune → train from scratch
•
non-linear projection → linear projection
•
small dataset → large dataset
•
InfoNCE Loss → Cross entropy loss
•
image transformation function and text transformation function → 사용하지 않음
•
다양한 augmentation → augmentation 거의 수행하지 않음
CLIP은 매우 큰 dataset을 사용해 overfitting을 거의 걱정하지 않아도 되었기 때문에 학습 방식을 매우 단순화 시켰다고 한다.
Zero-shot transfer
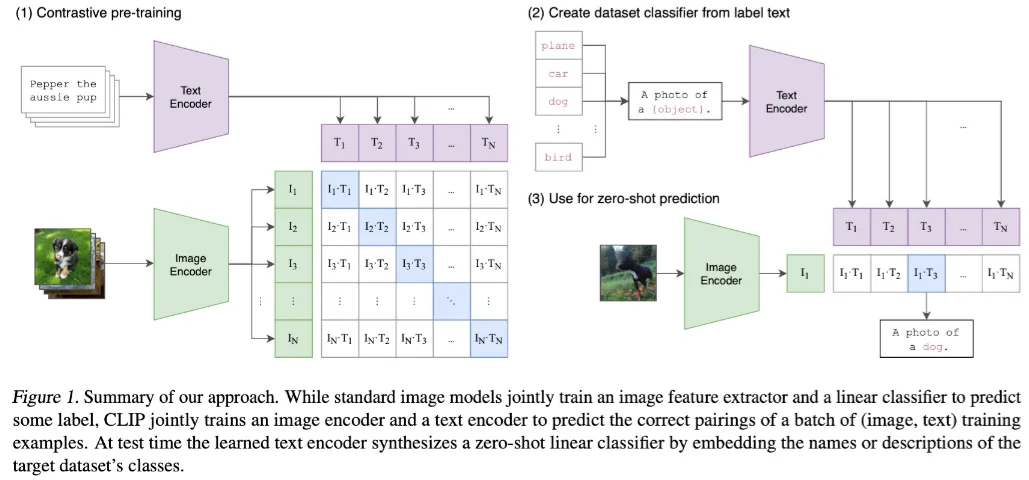
CLIP은 그림과 같이 학습이 끝난 후 zero-shot prediction을 수행했다.
이는 다른 dataset에 대한 finetuning이 필요 없다는 것을 의미하며, prompt engineering을 통해 가능했다.
prompt engineering이란…
•
위 그림과 같이 task에 맞추어 완성한 문장을 text input으로 넣어주는 방식이다.
•
그림에서는 image classification이 목적이기 때문에 “A photo of {object}” 라는 prompt template를 사용했다. (ImageNet dataset에서 1.3%의 성능 향상 효과를 가져옴)
•
Oxford-IIIT Pets라는 데이터셋에서는 “A photo of a {object}, a type of pet”
•
Sallite image classification datasets 에서는 “a satellite photo of a {label}”
•
OCR datasets에서는 인식할 텍스트나 숫자 주변에 quotes(인용문)을 배치하면 성능이 향상되었다고 한다.
prompt engineering을 사용하지 않으면…
1.
다의어로 인한 문제 발생
•
단순히 클래스 명만 text로 주어진다면, text가 가지는 다의성에 의한 문제가 발생할 수 있다.
•
crane : 학 혹은 크레인을 의미 (ImageNet에 존재하는 예시)
2.
train set의 대부분의 text가 full sentence로 이루어져 성능이 하락함
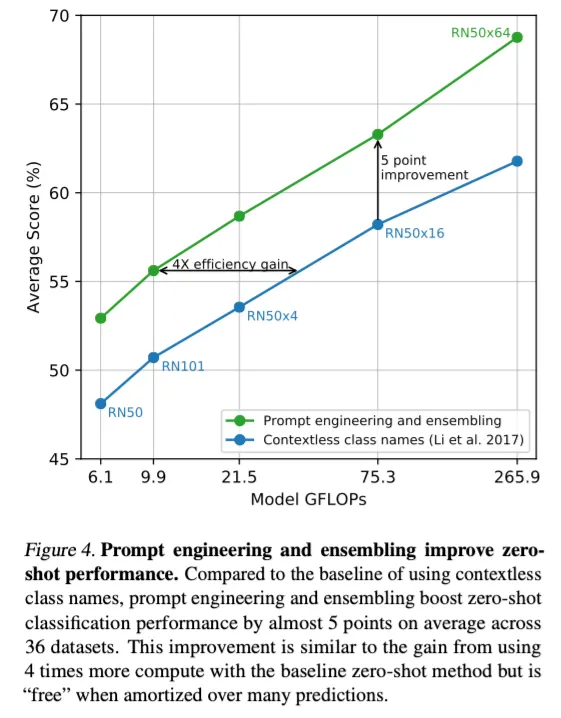
다양한 zero-shot classifier을 앙상블하는 방식도 가능하다

위 그림처럼 다른 context의 prompt들에 대한 embedding들을 앙상블해서 예측에 사용한다.
probability가 아닌 embedding space에서의 앙상블이라는 것이 핵심이다.
ImageNet에서 80개의 다른 context들을 앙상블했을 떄 하나의 프롬프트를 사용했을 때보다 3.5% 성능 향상이 있었다고 한다.
아래 표는 prompt engineering과 ensemble로 인한 성능 향상을 시각화한 표이다.
Experimental results
•
Implementation details
◦
image encoder : 5 ResNets 3ViTs (조금의 변형 추가)
◦
text encoder : Transformer with modifications described in [Radford et al, 2019] (Sparse Transformer)
◦
mini-batch size : 32,768
◦
mixed precision 등의 memory와 시간을 줄이기 위한 노력들을 했음
◦
가장 큰 ResNet model (RN50x64)이 592개의 V100 GPU들에서 18일 걸렸다.
◦
ViT-L/14가 가장 성능이 좋아서 모든 실험의 backbone으로 사용했다.
zero-shot vs few shot

Fig. 6은 zero-shot 과 few-shot의 성능 차이를 나타내는데, linear probe이라 함은 output을 출력하는 top layer (FC layer)만 fine-tuning함을 뜻한다. 즉 16-shot이라면 16쌍의 데이터만 가지고 FC 레이어 외의 weights는 freeze하고 학습을 시킨 것이라고 할 수 있다.
CLIP 외의 다른 모델들은 해당 모델의 features를 기반으로 few-shot logistic regression을 수행한 성능이다.
이 떄 4-shot일 때와 zero-shot CLIP의 성능이 유사하고 shot의 수가 높아질 수록 성능이 향상된다.
직관적으로 생각했을 떄 zero-shot이 one-shot보다 성능이 낮아야 할 것 같은데 그렇지 않다. 이는 아마도 zero-shot과 few-shot의 접근의 중요한 차이 때문일 것이라고 한다.
•
CLIP의 zero-shot classifier는 시각적 개념들을 직접적으로 명시할 수 있는 자연어를 통해 학습됐다. 그러나 few-shot (CLIP + linear probe + few-shot)의 경우 training examples로부터 간접적으로 visual concepts가 학습되기 때문이다.
◦
일반 supervised learning 은 training examples를 통해 visual concepts를 간접적으로 암시한다.
◦
이러한 context-less example-based learning은 많은 다른 hypothesis들이 데이터와 일치할 수 있다는 단점이 있다. (특히 one-shot의 경우)
◦
single image는 보통 많은 다른 visual concepts를 담고 있다. 그래서 모델이 어떤 객체를 주요 객체라고 가정하더라도 그것의 정확성은 보장되지 않는다.
Robustness to natural distribution shift

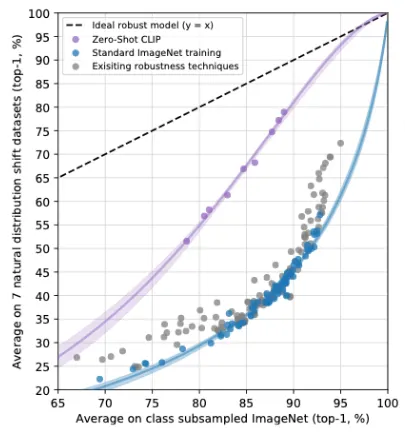
distribution shift : train 데이터와 test 데이터 간의 분포 차이로 인해 test 성능이 낮게 기록되는 현상
여러 데이터셋에 대한 zero-shot CLIP의 성능을 측정함으로써 distribution shift에 매우 robust함을 알 수 있었다. 매우 다르게 생긴 바나나들에 대해서 예측을 잘 해낸다.
사실 zero-shot performance가 높다는 것 자체가 natural distribution shift에 영향을 크게 받지 않는 것을 의미한다.
