pytorch에서 embedding을 위해 사용하는 nn.Embedding 레이어입니다.
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
Python
복사
이 임베딩 레이어는 처음부터 training data로부터 학습시킬 수도 있고, pre-trained word embedding들을 가져와 사용할 수도 있습니다.
Embedding → Embed → ‘끼워넣다’ → 다양한 길이와 문자들로 구성되어있는 단어들을 어떠한 틀에 끼워넣다. 로 생각하면 쉬울 것 같습니다.

자연어를 ‘수치화’ 하여 머신러닝 / 딥러닝 기법에 사용하기 위해 자연어를 vectorization (벡터화) 하는 것이고, 이를 word embedding이라 할 수 있다.
임베딩 레이어의 작동 방식
임베딩레이어를 통해 임베딩을 수행하기 위해서는 입력 sequence의 각 단어들은 정수로 encoding되어 있어야 한다.
•
vocaburary를 생성해 특정 단어를 특정 정수로 매핑을 해두고 사용한다.

단어 → 단어에 해당하는 정수값 → embedding 층 통과 → dense vector
sparse vector와 dense vector
임베딩 레이어의 작동은 다음 그림과 같이 나타낼 수 있다.
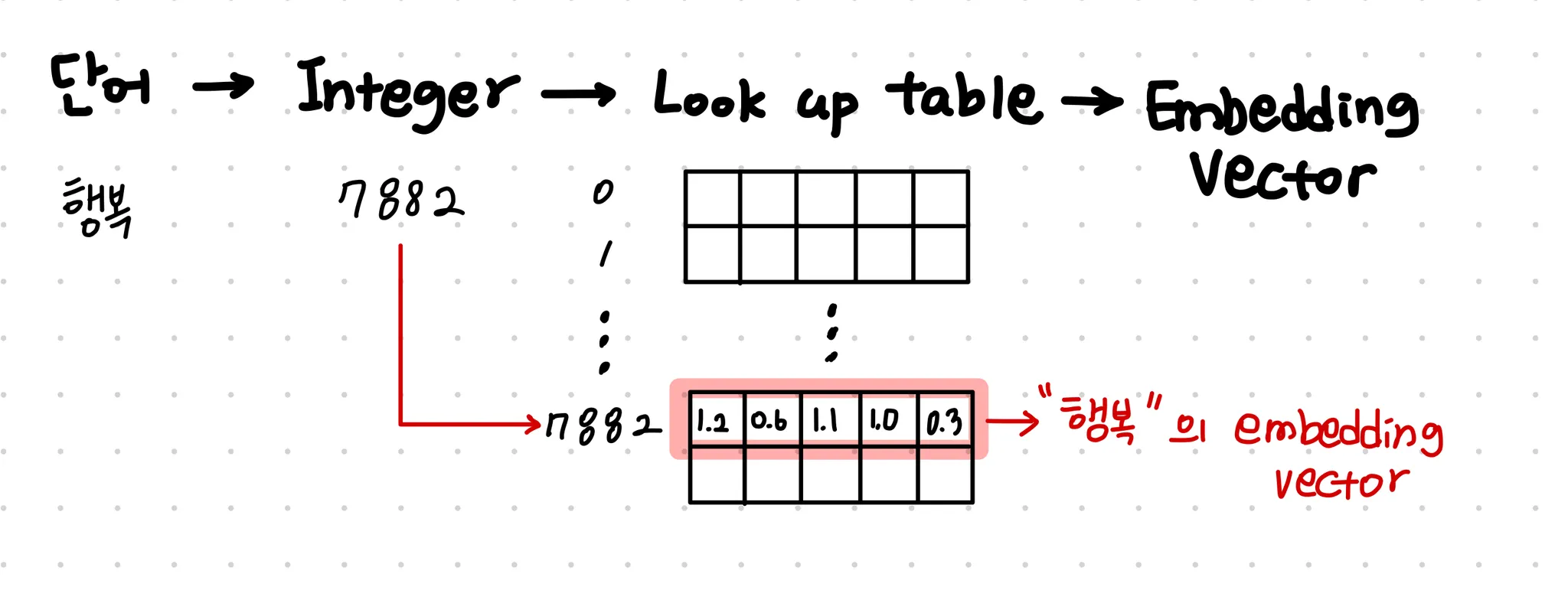
위 그림에서는 임베딩 차원은 5로 설정되어 잇다.
nn.Embedding은 위의 그림과 같이, integer로 들어온 입력을 one hot으로 바꾸어 어떠한 처리를 더 하는게 아니라 룩업테이블에서 임베딩 값을 가져옵니다.
실제 코드를 실행해 살펴보겠습니다.
1.
간단한 문장으로 token(단어) key들과 그에 해당하는 정수값 values로 이뤄진 vocaburary 생성
import torch
import torch.nn as nn
sentence = "내 이름은 채영"
word_set = set(sentence.split())
vocab = {token: i+2 for i, token in enumerate(word_set)}
vocab['<unk>'] = 0
vocab['<pad>'] = 1
print(vocab)
# {'이름은': 2, '채영': 3, '내': 4, '<unk>': 0, '<pad>': 1}
Python
복사
2.
embedding 레이어 생성하기
embedding_layer = nn.Embedding(num_embeddings=len(vocab),#단어개수
embedding_dim=5, # 임베딩 차원
padding_idx=1 # padding token의 인덱스
)
Python
복사
3.
embedding레이어에 임의의 input 넣어보기
embedding_vector = embedding_layer(torch.IntTensor([vocab['이름은'], vocab['채영']]))
print(embedding_vector)
# tensor([[ 0.5128, 0.9567, 0.0118, 0.4421, 0.0889],
# [ 1.1769, -0.2754, 0.6291, -1.0031, 0.4686]],
# grad_fn=<EmbeddingBackward0>)
Python
복사
4.
embedding레이어의 instance 변수 weight를 출력해 비교해보기
print(embedding_layer.weight)
Python
복사
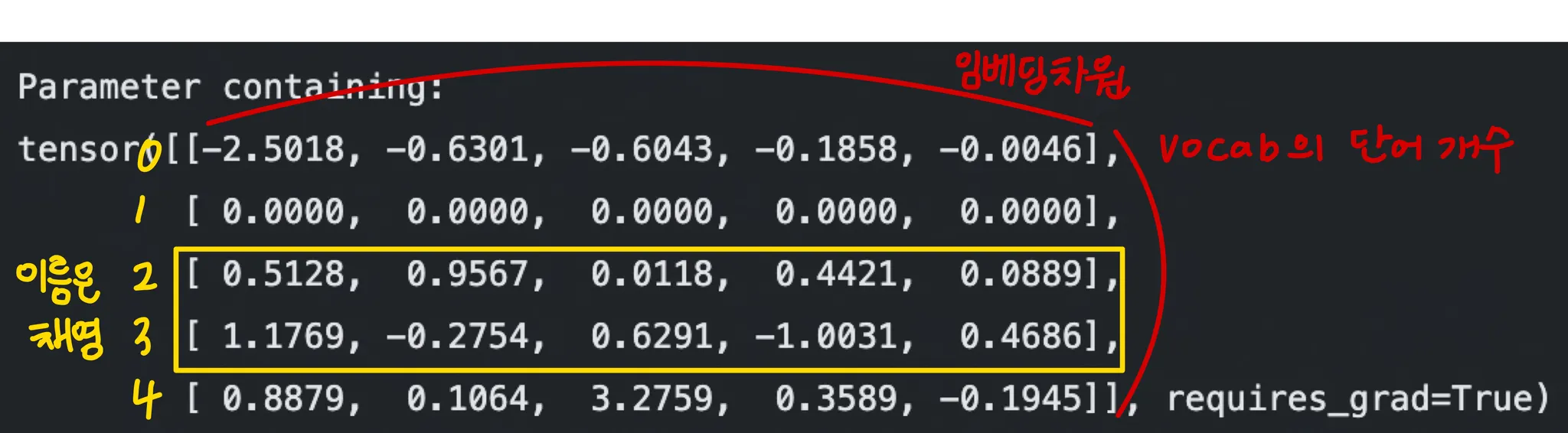
이러한 look up table을 사용한다는 것을 알 수 있었다.
nn.Embedding의 학습
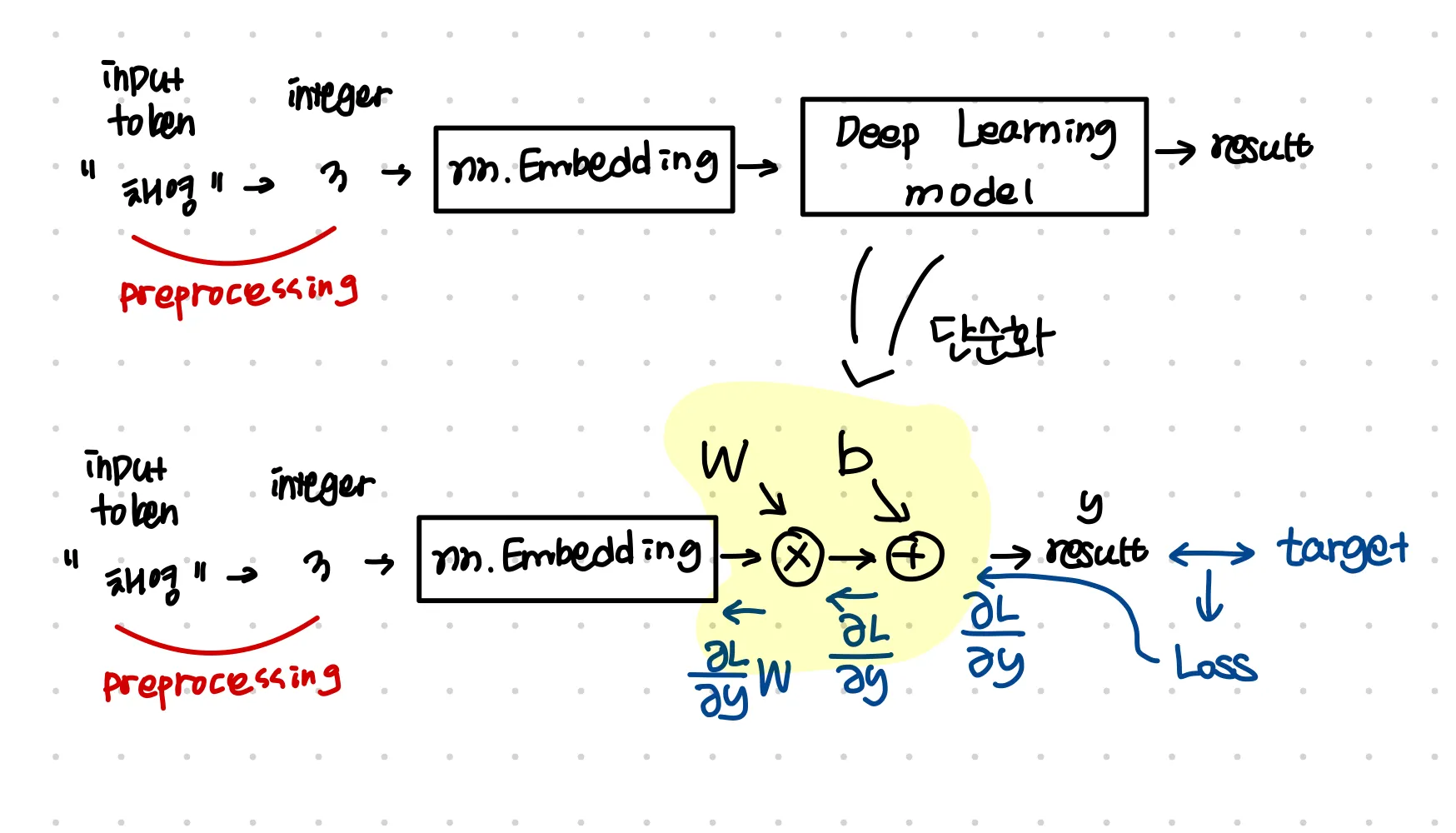
이 임베딩 레이어의 학습은 다음과 같이 일반 weight를 update하는 방식처럼 gradient descent를 통해 업데이트가 된다.
