구현 :  DCGAN_pytorch
DCGAN_pytorch
Deep Convolutional Generative Adversarial Nets (DCGAN)
기존 GAN의 한계
1.
결과가 불안정
2.
Black box method
NN의 한계라고 볼 수 있음. 결정 변수/주요 변수를 알 수 있는 다양한 머신러닝 기법과 달리 NN은 그 과정을 알 수 없음
3.
Generative Model의 성능 평가
결과물이 새롭게 만들어진 샘플이기 때문에 기존의 GAN으로 만들어진 샘플과 비교해 얼마나 뛰어난지 평가할 수 있는 정량적인 기준이 없다.
DCGAN목표
1.
Generator가 단순 기억으로 생성하지 않는 다는 것을 보여줌
2.
z의 미세한 변화에 따른 생성결과도 연속적으로 나타나야 한다(작은 z의 변화 → 결과의 작은 변화, 큰 z의 변화→결과의 큰 변화) : walking in the latent space
GAN과 DCGAN의 전체적인 구조는 유사하지만 D와 G의 세부적인 구조가 다르다
광범위한 모델 탐색 후, 우리는 다양한 데이터 세트에 걸쳐 안정적인 학습의 결과를 내고 higher resolution and deeper generative models을 학습시킬 수 있는 family of architecctures을 식별했다. ⇒ 엄청나게 많은 실험을 통해 아키텍쳐를 결정(노가다..)
기존의 GAN : FC layer로의 구성( fully connected로 연결)
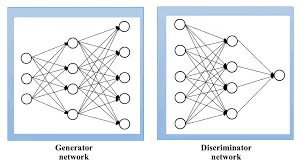
DCGAN : conv 레이어, pooling, padding등을 활용
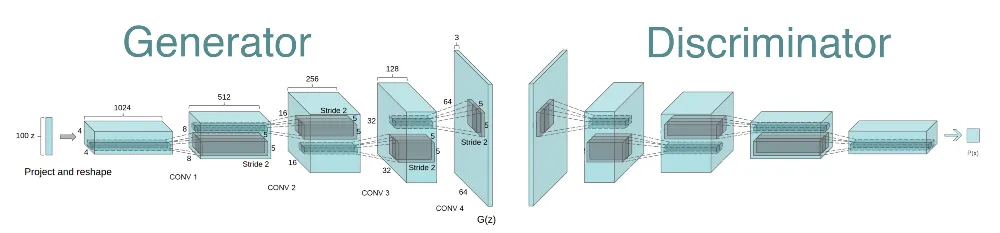
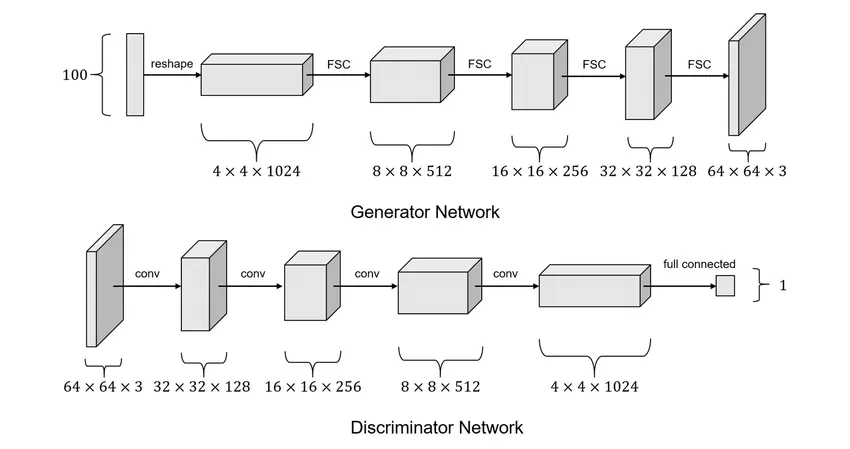

논문에 나와있는 안정적인 DCGAN학습을 위한 가이드라인이다
1.
D에서는 모든 pooling레이어들은 strided conv레이어로 바꿔라. G에서는 fractional-strided conv(Transposed Conv) 레이어로 바꿔라
2.
G와 D에 batchnorm을 사용해라.
: 이것은 deep generator들의 초반의 실패를 막는다고 한다. 그러나 모든 레이어에 적용하면 sample oscillation과 model instability의 문제가 발생하기 때문에 G의 output레이어와 D의 input레이어에는 적용 X
3.
deeper architecture에서는 fully connected hidden layer들은 삭제해라
4.
G에서 ReLU activation을 사용해라(output레이어는 tanh사용)
5.
D에서는 LeakyReLU activation을 사용해라(모든 레이어 대해)

fractionally-strided convolution = transposed convolution
https://chang-aistory.tistory.com/48?category=933534
Batch Normalization
https://chang-aistory.tistory.com/58?category=933534
Loss

결과
LSUN, ImageNet-1k, Face dataset으로 학습, 전처리x, 영상값은 [-1,1]범위로 scaling해서 사용


walking in the latent space 구현


D의 마지막 conv레이어로부터 얻은 6개의 학습된 convolutional features의 maximal axis-aligned responses들의 guided backpropagation 시각화
→ black box라는 한계를 어느정도 극복ㅁ
Applying arithmetic in the input space

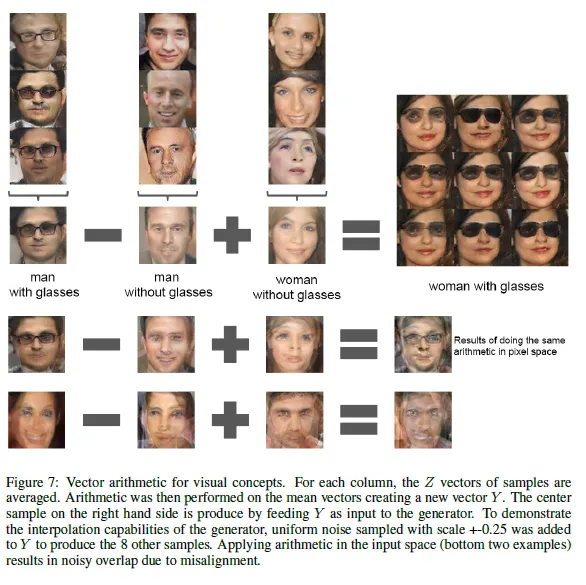
Distributed Representation of Words and Phrases and their Compositionality →단어들에 대한 representation을 벡터공간에 매핑시 linear arithmetic가능
비슷한 실험을 진행
vec(안경낀남자)-vec(안경끼지않은남자)+vec(안경끼지않은여자)⇒안경낀여자
== 학습을 제대로 수행하면 z값은 의미없는 값이 아닌 각 영상의 representation을 제대로 나타내게 된다.

