Abstract
ImageNet : computer vision 모델들의 성능을 평가하는데에 중요한 데이터셋
ImageNet
보통 모델 각각 맞춤형의 training scheme을 사용하고 전문가에 의해 디자인/조정하는 것이 일반적이다
이 논문에서는 어떠한 backbone이든 ImageNet에서 학습하는 통합된 방법을 제안, USI라고 이름지었다
USI는 knowledge distillation과 modern tricks에 기반하며 다른 모델 사이 조정이나 하이퍼파라미터 튜닝이 필요하지 않다. 또한 training time면에서도 효율적이다
USI를 CNN, Transformers, Mobile-oriented and MLP-only까지 다양한 모델에 적용해보았고 모든 모델 테스트에서 USI가 기존 SOTA결과를 넘어섰다.
USI는 어떠한 backbone이던지 적용이 가능하고 top result를 가져오도록 학습하기 때문에 methodical comparison을 가능하게하고 speed-accuracy Pareto curve를 따라 가장 효율적인 backbone식별이 가능하다
Introduction
왜 ImageNet이냐
ImageNet은 현대 딥러닝의 발전의 중심으로, 컴퓨터비전 모델 학습의 메인 데이터셋이다.
ImageNet에서의 accuracy를 측정하는 것이 실제 다양한 downtream task에서의 성능을 예측할 수 있다는 것이 밝혀져있다.
그렇지만 training on ImageNet : ongoing problem
학습을 잘 시키기 위한 방법들
시대의 획을 긋는, 영향력이 큰, 연구인 AlexNet이후로 결과를 개선하기 위한 새로운 training tricks, regularizations, enhancements 들이 계속해서 제안되어옴
•
One-cycle learning rate scheduling [33];
•
Stronger augmentations based on AutoAugment [5] and RandAugment [6];
•
Scaling learning rate with batch size [43];
•
Exponential-moving average (EMA) of model weights [19];
•
Improved weights initializations [13, 15];
•
Image-based regularizations such as Cutout [7], Cutmix [46] and Mixup [48];
•
Architecture regularizations like drop-path [4] and drop-block [9];
•
Label- smoothing [27];
•
Different train-test resolutions [39];
•
More training epochs [42];
•
Progressive image resizing during training [35];
•
True weight decay [26];
•
Dedicated optimizer for large batch size [44], and more.
아키텍쳐별 맞춤 학습 방법
거의 모든 제안되는 새로운 아키텍처에는 전용 training cheme이 수반된다.
이 scheme들은 서로 많이 다를 수 있고, 한 모델에 맞춰져 있는 학습 방식은 대부분 다른 모델들에서 성능이 좋지 않다
예를 들어 ResNet50에 맞춰진 방법이 EfficientNetv2모델에 적용된다면 EfficientNetv2에 맞춰진 학습방법보다 3.3%의 더 낮은 accuracy를 보인다.
대체로 컴퓨터비전을 위한 딥러닝 backbone들은 크게 4가지 카테고리로 나뉜다
1.
ResNet-like ( e.g. TResNet, SEResNet, ResNet-D ) 다양한 학습방법에서 잘 작동하지만 이를 위한 top-performance training scheme은 [42]에서 제안되었고 standard for this type of models가 되었다.
[42]
2.
Mobile-oriented : depth-wise convolution과 효과적인 CPU-oriented design에 아주 많이 의존한다.
이들을 위한 맞춤 학습방법은 보통 RMSProp optimizer와 waterfall learning rate schedulibg, EMA를 포함한다
3.
Transformer
4.
MLP only
: 부족한 inductive bias 때문에 vision을 위한 Transformer와 MLP-only는 학습하기가 어렵고 덜 안정적이다. 이들을 위한 맞춤 학습방법은 [38]에 제안되었고 더 긴 학습과 ( 1000 epochs) 강한 cutmix-mixup그리고 drop-path regularization, 큰 weight-decay, 반복되는 argumentations 를 포함한다[1].
Knowledge Distillation ( KD )
KD는 [16]에서 제안되었으며, target network(student model이라고도 함) 를 가이드해주기 위해 학습동안의 teacher model을 제안했다
[16] Distilling the knowledge in a neural network
student는 각 이미지에 대한 GT label과 teacher의 예측 둘 다에서 supervision을 받음
KL-divergence 는 teacher-student 사이의 extra loss를 측정한다(CE Loss외에 teacher-student 분포의 차이를 측정하는 추가 loss)
[38]은 ImageNet에서 Transformer-based models를 학습시키기 위한 맞춤 KD scheme을 제안했고 이는 특별한 distillation token과 hard-label thresholding and long training 에 의존한다.
[3]은 super network로부터 KD를 사용해 neural architecture search process동안 subnetworks를 학습시킨다.
[22]는 KD를 사용하였을 때 ResNet50 model의 marginal improvement를 보여준다
[40]은 data augmentation으로부터 KD suppressed noise를 제안했다 그러므로 더 강한 augmentation을 사용할 수 있게 했다
[47]은 teacher의 spatial prediction layer를 잘라냄으로써 variant of KD를 제안했다
하지만 KD는 ImageNet training에 일반적으로 사용되지 않는다
최상의 결과를 얻기 위해 더 자주 쓰이는 방법은 ImageNet-21K 데이터셋같은 더 큰 데이터셋에 pretraining하고 ImageNet-1K에 fine-tuning하는 것이다
당연히 이 대안은 더 긴 학습을 요구하고 더 큰 computational budget을 요구한다
ImageNet- 1K 이미지만 사용하여 얻은 결과와 ImageNet-21K 사전 훈련과 같은 추가 데이터를 사용하여 얻은 결과 는 분리하는 것이 일반적인 관행이다.
논문의 제안
USI (Unified Scheme for ImageNet)라는 ImageNet에 대한 통합된 학습방법을 제안
hyper parameter tuning 혹은 tailor-made tricks없이 USI는 어떤 backbone이든 SOTA 결과로 학습 가능
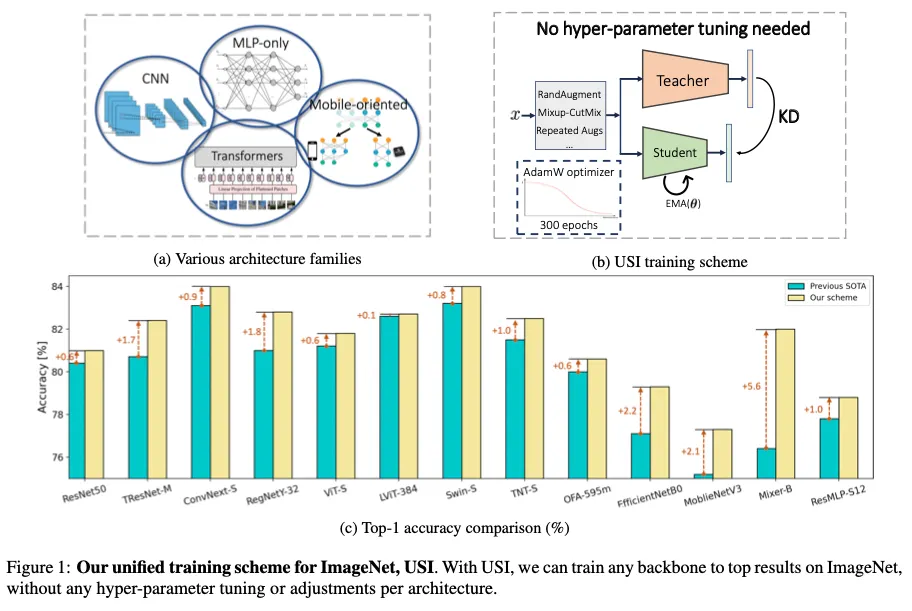
Fig1이 USI의 그림이고
이 방법은 teacher와 student 사이의 추가적인 KL-divergence를 부과하는 vanilla KD가 어떠한 backbone에서도 잘 작동한다는 관찰을 기반으로 한다
KD의 효과적인 이유는 원래의 GT라벨에 존재하지 않는 추가 정보의 도입이다.
이미지당 teacher의 예측은 class 간의 상관관계와 유사성을 설명하며, 여러 objects로 더 나은 사진들을 처리하며, 심지어 GT mistakes를 보상한다.
KD는 또한 더 나은 augmentation을 처리하고 label smoothing의 필요성을 제거한다.
이러한 모든 요소는 더 강력하고 효과적인 최적화 프로세스로 이어지며, 이는 더 적은 훈련 트릭과 정규화를 필요로 합니다.
우리는 ResNet-like, Mobile- oriented, Transformer-based and MLP models을 포함한 다양한 현대 딥 러닝 모델에서 USI를 철저히 테스트합니다. 테스트된 모든 모델에서 USI는 모델당 전용 계획으로 얻은 이전에 보고된 SOTA 결과를 능가한다. USI는 또한 효율적이며, 300epoch의 훈련만 필요하다.
제안된 방법은 지속적으로 top-result로 이어지기 때문에, speed-accuracy trades-offs을 공정하게 비교할 수 있다.
We benchmark various models on GPU and CPU, and identify leading models that provide the best speed-accuracy trade-off along the Pareto curve.
[contribution] summary
•
하이퍼 파라미터 튜닝이 필요하지 않은 ImageNet 데이터셋에서의 USI라는 통합되고 효율적인 훈련 체계를 소개
정확히 같은 레시피가 모든 백본에 적용된다.
따라서 ImageNet 교육은 전문가 중심의 작업에서 automatic seamless 절차로 변환됩니다.
•
ResNet-like, Mobile-oriented, Transformer-based and MLP-only models
을 포함한 다양한 딥 러닝 모델에서 USI를 테스트합니다. 우리는 모델당 tailor-made schemes에 비해 일관되고 안정적으로 최첨단 결과를 달성한다는 것을 보여줍니다.
•
USI를 현대 딥러닝 모델들의 methodological speed-accuracy comparison을 수행하고 Pareto curve를 통해 효과적인 backbones를 식별하기 위해 USI를 사용하였다
2. Methods
•
어떻게 classification에 KD를 적용하였느냐 리뷰
•
왜 KD가 ImageNet 학습에 필요한가
•
KD-based training방법인 USI 설명
2.1. KD for Classification
어떤 input image이던지 classification network의 output은 logit vector
K = class 수
softened prediction vector : ,
는 softmax activation fuction을 적용해 주어짐.
: temperature scaling parameter
즉 temperature scalining을 더한 softmax 함수식. 를 1보다 높게 설정하면 더 부드러운 확률분포 생성

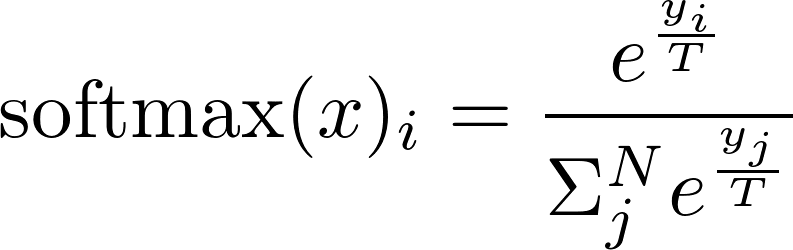
: student model의 softened prediction vectors
: teacher model의 softened prediction vectors
student model학습을 위한 objective function : student의 예측과 GT vector인 y의 CE Loss와 KL divergence의 결합
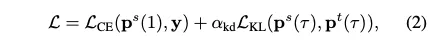
는 KD loss의 상대적 중요성을 조정하는 하이퍼파라미터
CE Loss
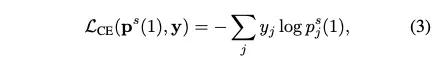
KL divergence loss
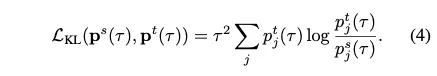
teacher의 예측값의 분포와 student의 예측값의 분포의 차이를 계산하는 것으로 볼 수 있다.
KL divergence loss
결국 KL divergence loss에 실제 분포 자리(True)에 teacher의 분포를 넣어주는 것이기 때문에 teacher의 분포에 가깝게 학습시키는 것. 따라서 Teacher의 성능과 유사한 성능이 나올 수 밖에 없는 것 같다
2.2. Why Do We Need KD in ImageNet Tranining?
ImageNet데이터셋은 train from scratch 해야한다
•
train from scratch
◦
일반적으로 더 힘들다
◦
더 큰 learning rate를 요구
◦
더 강한 regularization과 training epochs가 요구됨
◦
하이퍼파라미터, 아키텍쳐의 변화에 민감
KD 의 영향력에 대한 인사이트/motivation을 보여주기 위한 Fig2

teacher model의 예측 (빨간색이 GT라벨)
•
(a) 는 큰 현저하게 나타나는(salient) nails들을 포함.(GT또한 nail) 그러나 teacher는 99.9로 예측하고 두번째, 세번째로 크게 예측한 것은 나사와 관련이 있는 screw와 hammer. 그러나 무시 가능한 확률
•
(b)는 airliner를 포함. 1등으로 예측됨. 그러나 wing을 무시할 수 없는 확률로 예측. 실수가 아니다. airliner는 wing을 가지고 있으니까. teacher는 GT라벨이 상호 배타적이지 않은 경우(not mutually-exclusive)를 완화하고 이미지의 내용에 대해 더 정확한 정보를 제공한다.
•
(c)는 hen(암탉)을 포함하고 있지만 hen이 매우 크고 현저하게 나타나지 않는다. teacher의 예측은 높지 않은 hen의 확률로 그것을 반영한다. 또한 teacher는 cock에 대해 무시할 수 없는 확률을 제공한다. 이는 teacher의 실수이다. 그러나 논리적이다. hen과 cock은 매우 유사하기 때문이다
•
(d)는 GT를 무시한다. (ice lolly가 GT라벨) top prediction이 English setter이다. teacher는 맞았다. dog가 사진에서 더 명확하게 나타나기 때문이다!
위의 예시들로부터 teacher의 prediction들이 plain GT인 single label보다 더 많은 정보를 포함하고 있다. 라는 것을 알 수 있었음.
teacher가 제공하는 풍부한 예측은 클래스간의 유사성과 상관성을 설명한다
그것들 ( teacher가 제공하는 풍부한 예측 )은 여러 개체를 포함하는 사진을 더 잘 다루고, 심지어 GT실수를 보상한다! ((d)의 경우 )
KD 예측들은 또한 더 강한 augmentation들을 다루고, 그로 인해 그들은 augment된 이미지들에서 더 정확한 content를 표현한다 → augmentation 된 이미지들은 hard label 과 정보가 다를 수 있다. 이를 KD예측이 보완할 수 있다는 이야기 같다
그들은 또한 label smoothing의 필요성을 제거한다. 왜냐하면 teacher가 본질적으로 soft predictions를 내보내기 때문이다
이러한 요소들 떄문에, teacher로 학습하는 것은
•
better supervision을 제공하고,
•
더 효과적이고 robust한 optimization process로 이어집니다 (hard-labels만으로 학습할 때보다 )
2.3. The proposed Training scheme
USI는 기본적으로 KD를 응용하는 것에 기반함
KD로 ImageNet에 학습할 때 우리는 학습 process가 하이퍼파라미터 선택에 있어서 매우 더 robust함을 확인했다. 그리고 더 적은 training tricks와 regularization을 필요로 한다는 것을 확인했다. ( 실험적 결과 )
또한 백본에 따른 맞춤 tricks도 제거되었다. 오직 하나의 unified scheme이 어떤 backbone이든 top result로 학습이 가능하다.
training configuration

(KD temperature=1이라는건 그냥 soft softmax 말고 그냥 softmax 썼다는 것)
Some observation and insights into the proposed scheme
1.
Batch Size selection
backbone별 허용되는 maximal batch size는 매우 다르다

그래서 모든 backbone에 대해 고정된 batchsize를 사용하는 것은 항상 가능한 것은 아니었다.
배치사이즈를 가능한 크게 사용하는 것은 beneficial 하므로 GPU cores를 전부 사용할 수 있게 해 training speed를 높였다.
이전 방법들은 더 큰 배치사이즈는 더 큰 learning rate 혹은 맞춤 optimizer를 요구한다고 했다
KD based 학습방법인 USI는 AdamW optimizer를 사용했고 이는 더 배치사이즈와 learning rate에 robust하다. 우리는 섹션 3.2에서 동일한 learning rate로 USI가 다양한 배치 크기에 대해 지속적으로 최고의 결과를 제공한다는 것을 보여줄 것입니다. → AdamW optimizer의 사용이 필수적으로 보인다
그러므로 Table 1에 배치사이즈의 범위를 언급
이 범위 내의 어떤 값이든 선택이 가능하다. 학습속도를 최적화하기 위해 가능한 maximal batchsize의 0.8~0.9정도를 사용하는 것을 추천한다고 한다
2.
which teacher to choose
USI의 주요 요구 사항은 KD의 일반적인 요구 사항인 student을 능가하는 teacher를 선택하는 것입니다 [16].
이 제한 내에서, 우리는 teacher model을 좋은 speed-accuracy trade off를 갖는 모델을 사용하는 것을 제안
USI가 student와 teacher의 type에 robust함을 3.3에서 보여줄 것이다.
비슷한 accuracy를 가진 teachers는 학생을 비슷한 accuracy를 가지도록 학습시킨다. 그들의 타입에 상관없이(CNN이건 Transformer건)
3.
KD impact on training speed
KD supervision을 추가하는 것은 추가적인 overhead를 가져와 학습 속도를 감소시킨다
그렇지만 추가된 overhead는 보통 작다.
student network가 forward pass를 하고, intermediate maps를 저장하고, backward pass를 하고 weights를 업데이트 해야하는 반면 teacher는 오직 forward pass만이 필요하기 때문
추가적으로
teacher모델은 고정되어있기 떄문에 우리는 batch-norm fusion 이나 channels-last, jit같은 다양한 optimization을 추가할 수 있다.
KD의 상대적 overhead가 배치사이즈를 늘릴수록 줄어든다는 것을 발견했다. 이것이 큰 배치사이즈를 선호하는 또 다른 이유이다
TResNet-L teacher model( 83.9% accuracy)에 대해 KD의 추가 오버헤드는 훈련 속도를 10%-20% 감소시킨다.
3. Results
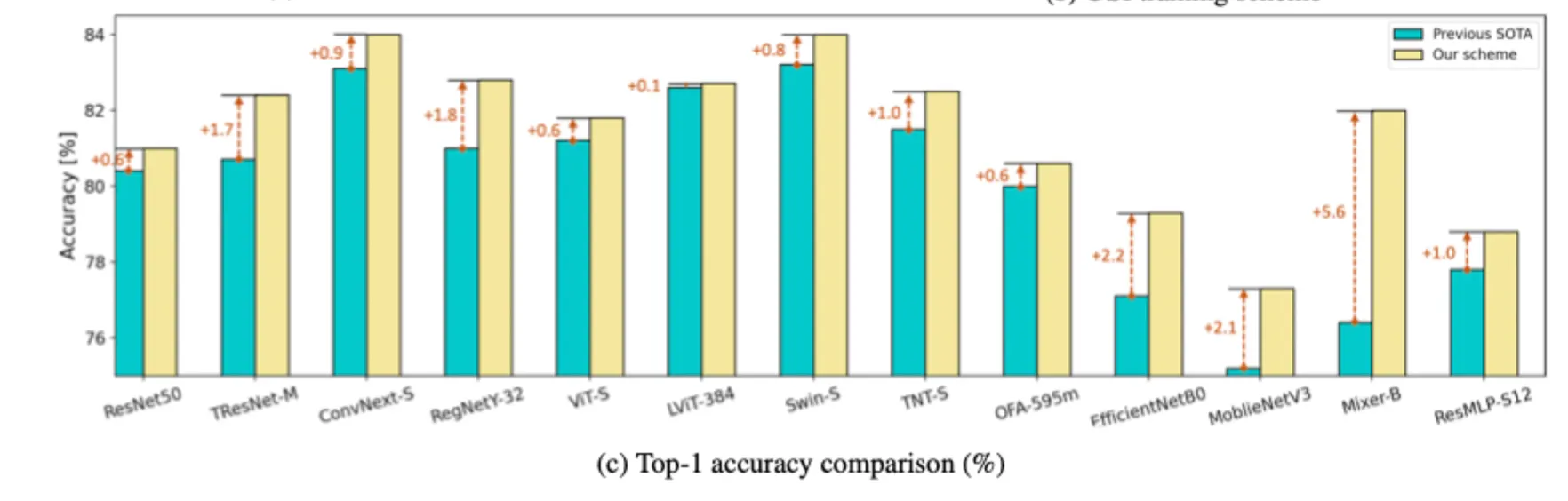
3.1. Comparison to Previous Schemes
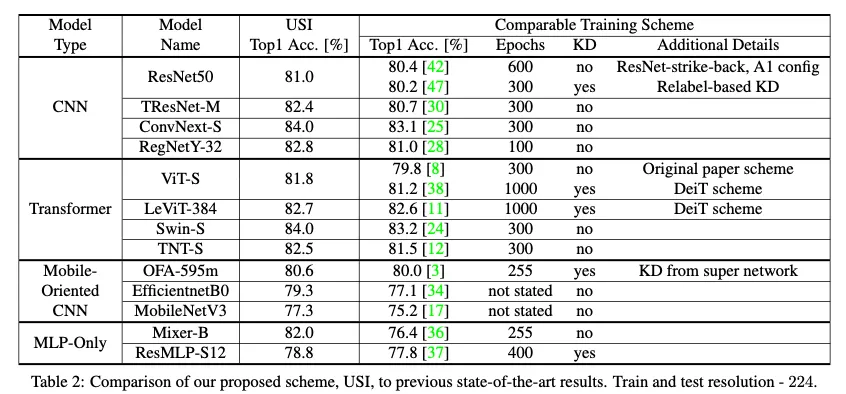
Table2에서 기존 방법과 USI사용 방법에서의 ImageNet top-1 accuracy 비교
모든 모델이 기존 방법보다 USI 방법을 사용한 경우가 더 높았다.
결과적으로 모든 모델 하이퍼파라미터 튜닝 없이 테스트 결과 USI가 SOTA를 찍었다
이것이 fair comparison이라고 믿으며 USI가 ImageNet에서의 학습에서 high quality training으로 변환시켜줄수 있다는 것을 입증한다고 생각한다. 자동적인 루틴으로, 최적화된 전문가와 성가신 튜닝작업없이
3.2. Robustness to batch size
큰 배치사이즈 → 빠른 학습속도
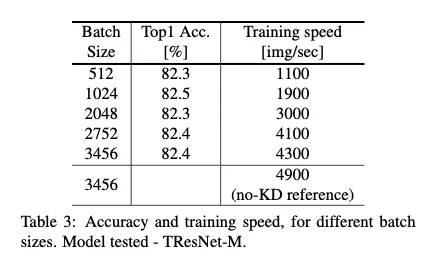
Table 3에서
•
고정된 learning rate,
•
다른 batchsize에서
USI의 robustness를 테스트함
TResNet-M model 사용 : 이 모델은 inplace-activated-batchnorm을 사용해 큰 배치사이즈가 가능
그러나 배치사이즈가 작아져도 성능 비슷
다양한 배치 크기인 512-3456에서 정확도는 거의 동일하게 유지됩니다. 이것은 USI가 fixed learning rate로 잘 작동한다는 것을 나타냅니다.
[실험 환경] 8개의 V100 을 사용 , TResNet-M student, and TResNet-L teacher
(배치사이즈에 대한 민감도는 모델마다 다를 수 있기 때문에 한 모델만의 실험으로는 부족하지 않을까 라는 생각이 들었다)
3.3. Robustness to Teacher Type
Table2는 TResNet-L teacher로부터 얻어진 것
이 모델을 teacher로 선택한 것은 이것이 높은 정확성과 좋은 speed-accuracy trade-off를 보여주었기 때문이다
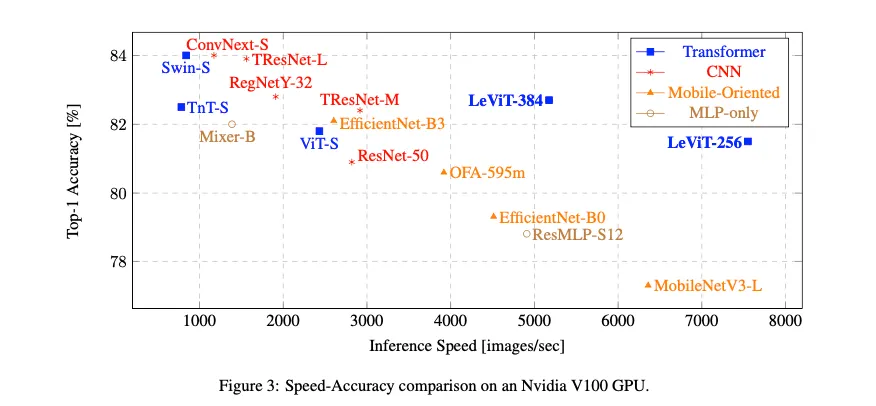
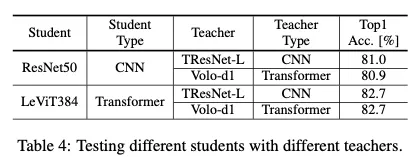
Table4는 CNN과 Transformer student 둘다 CNN/Transformer teacher와 잘 작동했다는 것을 보여줌. teacher type의 선택에 유연성이 있다는 것을 암시한다.
3.4. Number of Traning Epochs
USI default configuration 은 KD training 300 epoch이다
하지만 최대 가능 accuracy 도달 위해서는 300 epoch는 부족하다 더 긴 training이 accuracy를 더 높게 할 수 있다.
이러한 현상, KD에서 student model이 긴 training 에서 benefits을 얻는 것. → patient teacher라고 부른다
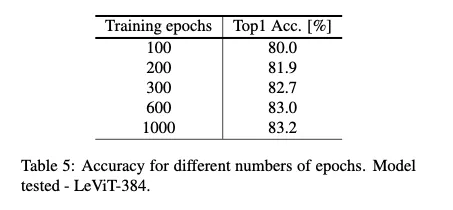
Table 5에서 우리는 다양한 training 길이에서 얻어진 accuracy를 보여준다
학습 epoch가 많아질수록 accuracy가 높아짐.
CNN이라는게 사실 학습을 오래한다고 해서 무조건 성능이 좋아지는 것은 아닌데, teacher가 있기 때문에 이러하다 라는 것을 보여주는 것 같다
300 epoch라는 default값은 training time과 good result의 좋은 타협이다 ( default 값을 300으로 정한 이유 ) → 1-3일걸린다 (모델에 따라 조금씩 다르고, 8개의 v100환경에서)
그 결과는 이제 Fig1의 (c)
하지만 학습시간이 제한되지 않았다면 epoch수를 늘리는 것을 추천
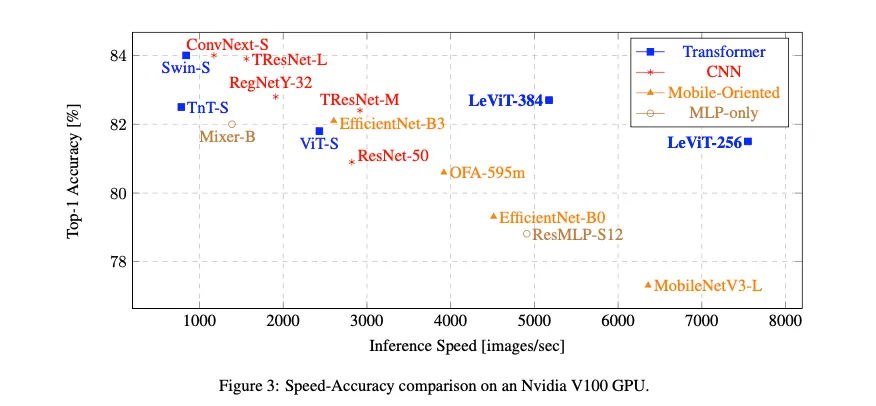
3.5. Speed-Accuracy Measurements
하이퍼파라미터 튜닝과 컴퓨팅파워 및 다른 요소에 의존하는 백본마다의 맞춤 학습 방법을 썼을 때,
다른 모델들과 비교하는 것은 확실히 어렵다
USI와 함께라면 어떤 백본이든 top result를 가져오고 ImageNet에서 speed-accuracy trade off에 대한 methodological & reproducible & reliable 비교가 가능하다
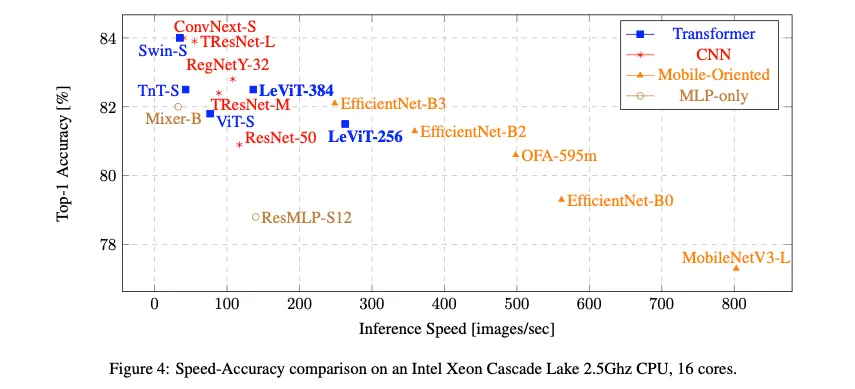
Implementation details
GPU에서는 처리량이 pytorch engine에서 테스트되었는데, (FP16, batchsize 256)
CPU에서는 Intel Open-VINO Inference Engine에서 측정됨. ( FP16, batchsize 1, 16streams(eqivalent to the number of CPU cores) )
모든 측정들은 모델이 batchnorm fusion에 의해 inference하기에 최적화된 이후 측정됨
batchnorm fusion은 significantly accelerates batchnorm 사용한 models(ResNet50, TResNet and LeViT)
batchnorm fusion
GPU inference analysis
•
for low-to-medium accuracies, the most efficient models are LeViT
•
for high accuracies, TResNet-L 이 가장 좋은 trade off 제공(test 시)
 LeViT외에 다른 트랜스포머 모델들 Swin, TnT, ViT같은거는 낮은 전통적 CNN보다 trade- off 보였음을 알아야함 또한 다양한 Small이라고 이름붙은 현대 아키텍쳐들( ConvNext-S, Swin-S, TnT-S )은 사실 resource-intensive하다는 것을 알아야함 그들의 inference speed는 일반 ResNet50 에 비해 거의 3배 느리다
LeViT외에 다른 트랜스포머 모델들 Swin, TnT, ViT같은거는 낮은 전통적 CNN보다 trade- off 보였음을 알아야함 또한 다양한 Small이라고 이름붙은 현대 아키텍쳐들( ConvNext-S, Swin-S, TnT-S )은 사실 resource-intensive하다는 것을 알아야함 그들의 inference speed는 일반 ResNet50 에 비해 거의 3배 느리다CPU inference analysis
CPU에서는 mobile oriented models( OFA, MobileNet, EfficientNet )가 가장 좋은 speed-accuracy trade-off를 제공함
LeViT모델은 GPU inference를 가속함 CPU에서는 효과적이지 않음
3.6. Additional Ablations
추가적 ablations와 테스트
3.6.1 KD teacher relative weight
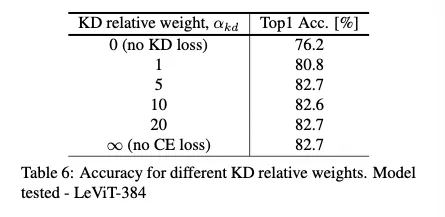
KD Loss와 supervision loss 사이의 상대적 weight의 영향 ( )에 대한 테스트결과의 테이블이다
KD 없이는 매우 낮음! 76.2
그리고 CE Loss 없이 KD Loss만 사용시에 가장 높은 것이 의외의 결과임
즉 hard label supervision 없이 오직 teacher에만 의존한 결과가 가장 좋다
KD in ImageNet training의 효과적임을 더욱 입증
3.6.2. KD Temperature
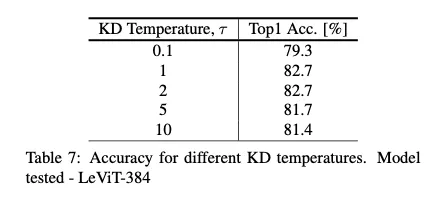
τ < 1 (sharpening the teacher predictions) and τ > 1 (softening the teacher predictions) → 둘다 성능 떨어짐
Utilizing vanilla softmax probabilities leads to the best results.
그냥 1로, 일반 softmax로 하는게 성능이 젤좋다~
3.6.3. Mixup-Cutmix vs Cutout

Cutout, Cutmix, Mixup 모두 성능향상을 가져옴
Cutout은 입력 이미지만 증강하지만, Cutmix와 Mixup은 라벨도 변경합니다.
cutout은 CNN과 Mobile-oriented models[17, 15]을 훈련할 때 더 널리 퍼져 있으며, [41]에서 제안된 믹스업과 컷믹스의 결합은 트랜스포머 기반 모델[11, 38] 훈련에 인기가 있다.
표 8에서 우리는 통합 체계에서 Cutout을 사용하여 Mixup-Cutmix를 비교합니다.
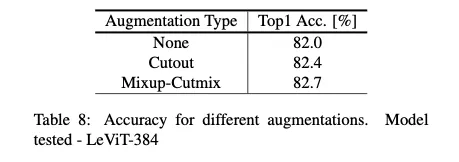
둘다 성능향상이 있으나, mixup-cutmix 가 좀더 높다
3.6.4. Architecture-based regularizations
주로 트랜스포머계열 모델 학습할 때 architecture-based regularization을 적용하는것이 일반적(drop-path, drop-black같은)
이 regularizations는 항상 다른 아키텍쳐에 적용가능한건 아니다 그리고 그들의 적용은 모델마다 다르다
그러므로 그것을 사용하는 것을 피했다
테이블9는 drop-path를 추가하는 것을 실험( transformer based model에 )
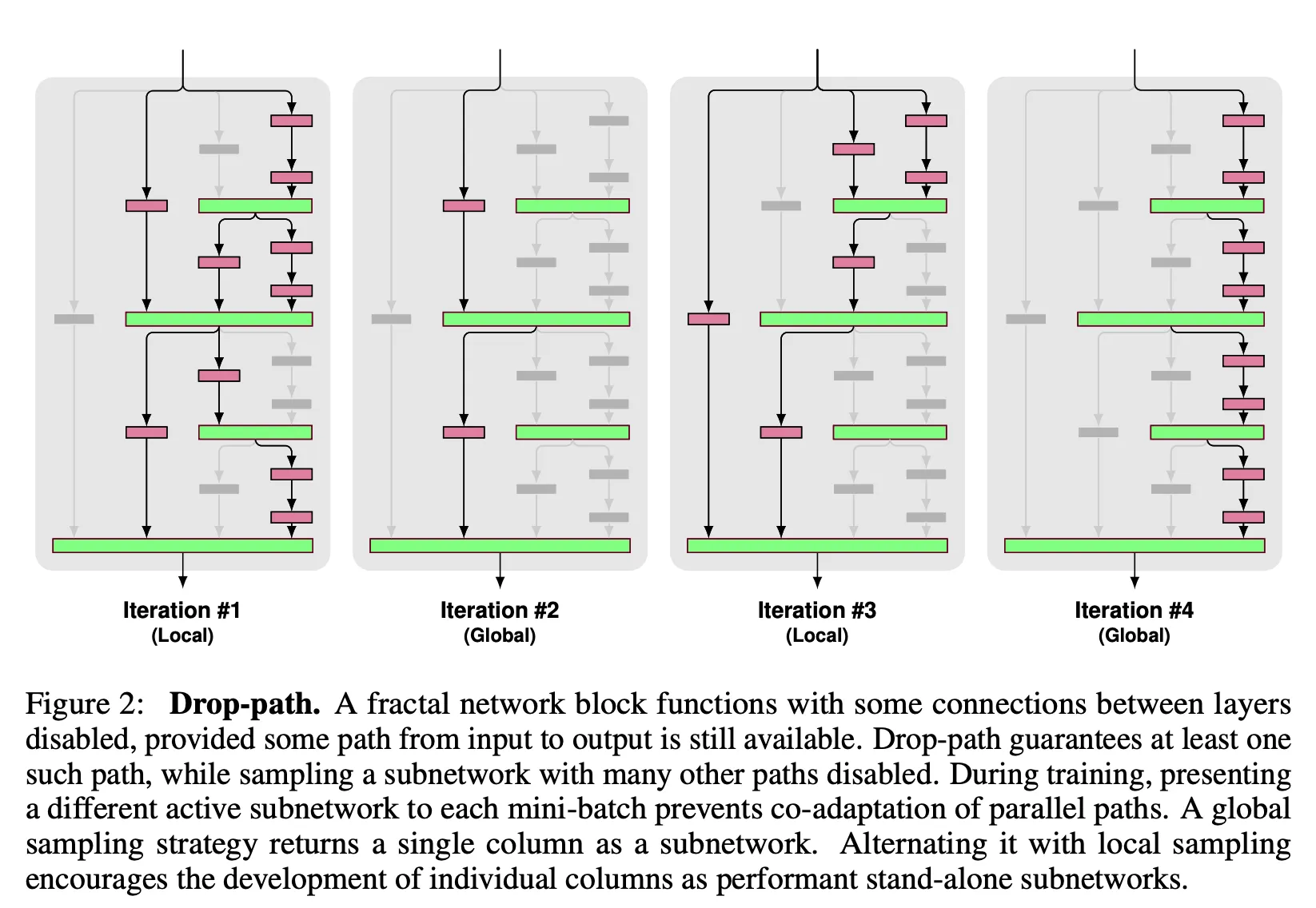
drop path

사용하는 것이 더 낮은 성능을 보임
3.6.5 Repository
구현 세부 사항 및 기타 요인으로 인해 특정 repository의 training는 때때로 다른 저장소에서 사용할 때 성능이 저조합니다. 우리는 내부 개인 저장소에서 USI를 개발했다.
유효성에 대한 신뢰를 높이기 위해, 우리는 공개적으로 이용 가능한 저장소인 timm [41]에서 그것을 다시 구현했습니다.
우리는 개인 저장소에서 얻은 모든 결과를 timm으로 재현할 수 있었다.
우리는 팀 기반 구현을 공유할 것이다.
4. Discussion and Conclusions
이 논문에서, 우리는 USI라고 불리는 ImageNet 교육을 위한 통합 계획을 도입했다. KD와 현대적인 훈련 트릭을 활용하는 USI는 다른 모델 간의 하이퍼 파라미터 튜닝이 필요하지 않으며, backbone를 최상의 결과로 훈련시킬 수 있습니다. 따라서 ImageNet에 대한 교육을 전문가 중심의 작업에서 자동 절차로 변환합니다. USI를 통해, 우리는 또한 체계적인 speed-accuracy 비교를 수행하고 효율적인 컴퓨터 비전 백본을 식별할 수 있습니다.
Applicability to other classification datasets
ImageNet의 경우, 우리는 모델을 처음부터 훈련시키고 있습니다. 이것은 높은 학습 속도, 강력한 정규화, 그리고 더 많은 epoch 사용한다.
따라서, 우리의 ImageNet 전용 USI 체계는 일반적으로 transfer learning을 사용하는 다른 분류 데이터 세트에 직접 적용되지 않습니다.
그러나, KD는 이전 학습 사례에도 매우 효과적인 기술로 남아있다. 그것은 점수 향상에 기여할 뿐만 아니라, 하이퍼 파라미터 튜닝에 덜 민감한 더 강력한 훈련 절차로 이어진다.
우리는 다양한 AutoML scheme이 KD 사용의 혜택을 받을 것이라고 믿으며, 향후 작업에서 이를 입증할 계획입니다.
읽으면서, 결국에는 teacher와 비슷한 성능을 갖도록 학습시키는 방식인데, 그럼 teacher 모델을 그냥 쓰면되지않나? 라는 생각을 했는데,
내가 쓰고싶은 것은 작은모델일 수 있고, 성능 좋은 큰 모델로 작은 모델의 성능이 좋도록 학습시켜줄 수 있다는 면에서 좋은 방법인 것 같다 + AutoML에서의 사용성
그렇지만 teacher 이상의 성능을 내기는 어렵다는 것이 한계인듯!
