

•
분류/회귀분석에 사용 가능한 머신러닝 지도학습 모델
•
Decision Boundary를 정의하는 모델이다 : 분류를 위한 기준 선을 정의. 이를 기준으로 새로운 데이터가 등장하면 경계의 어느 쪽에 속하는지 확인해 분류한다
[예시]
2차원
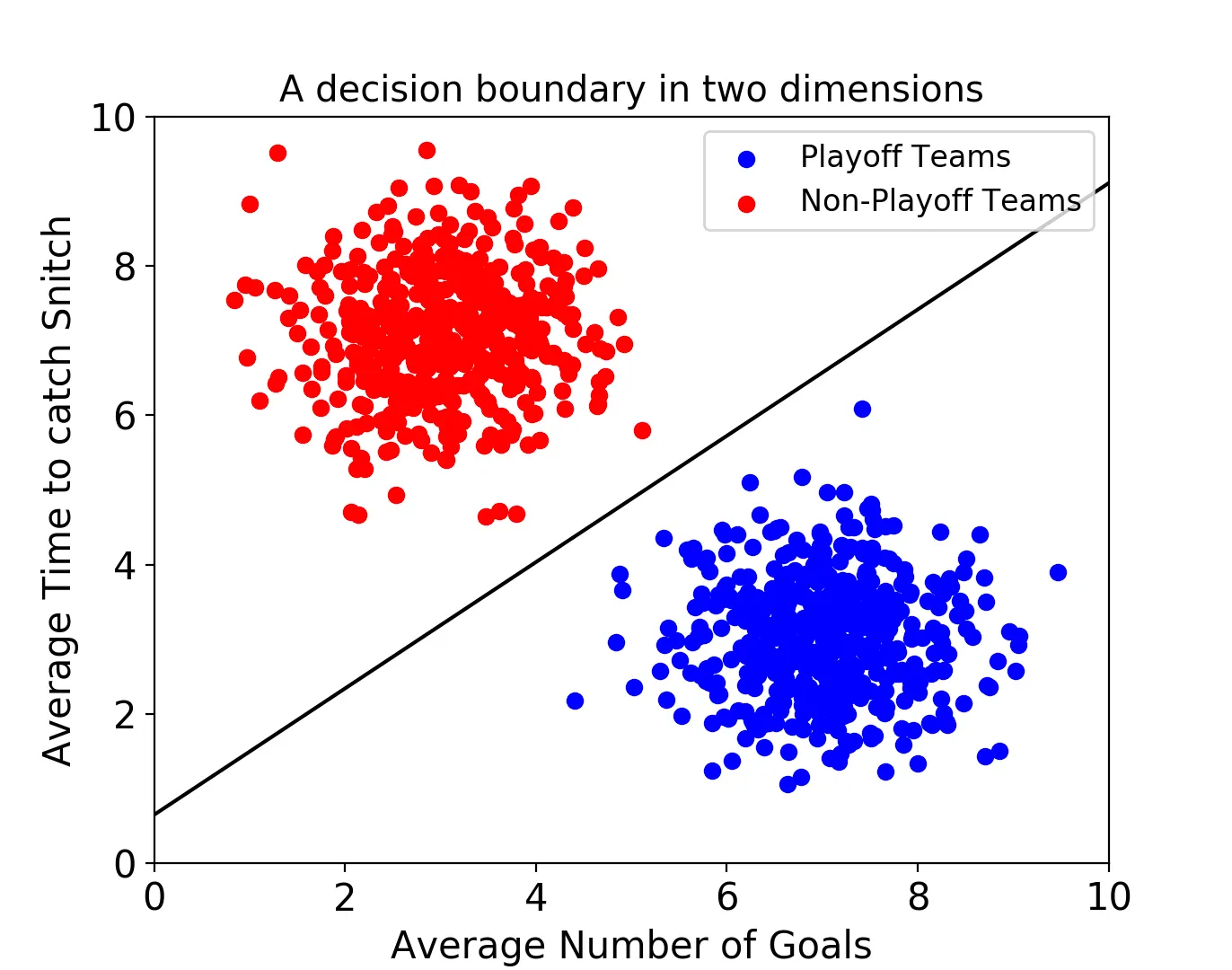
3차원
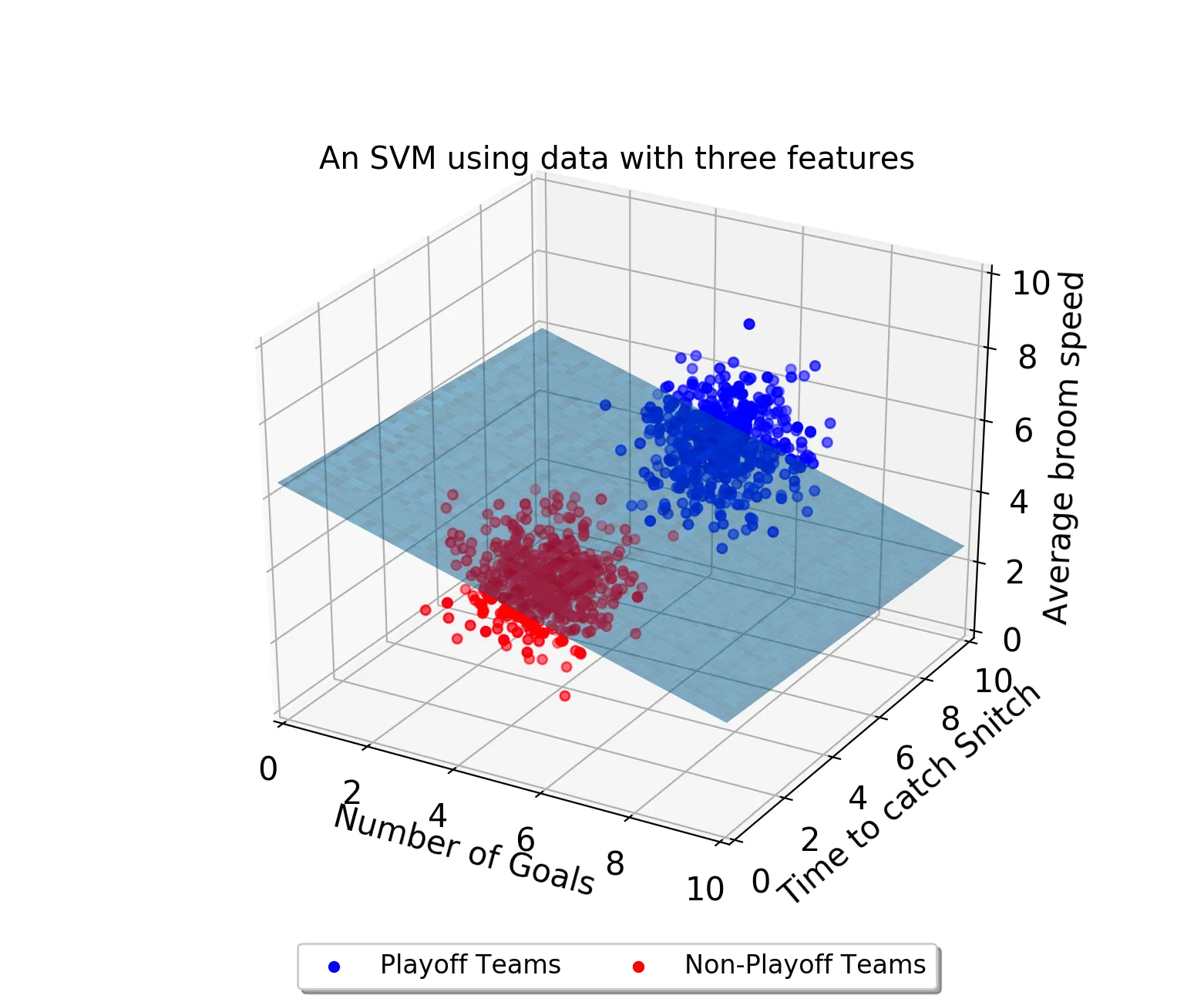
우리가 보통 다루는 데이터들은 매우 고차원인 초평면(hyperplane)이다
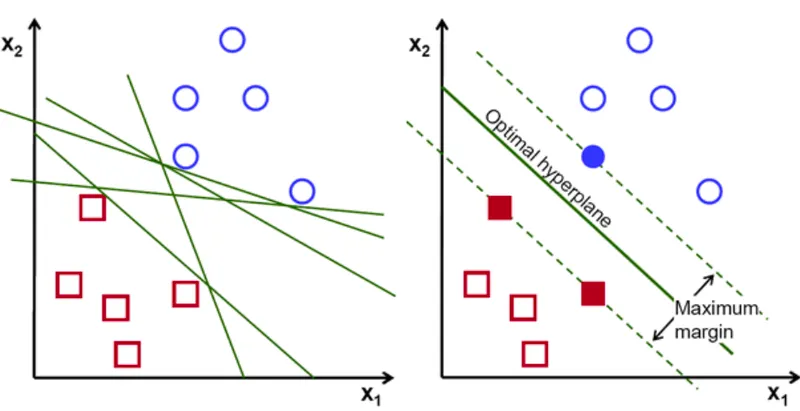
우리는 이렇게 최적의 결정선을 찾아야한다.
SVM에서는 두 클래스 사이 거리(margin)이 가장 큰 결정선을 최적이라고 판단한다
Support Vector Machine에서 support vector란 결정선 근처의 데이터포인트들을 말하며, 이 데이터들이 경계를 결정하는 주된 역할을 한다
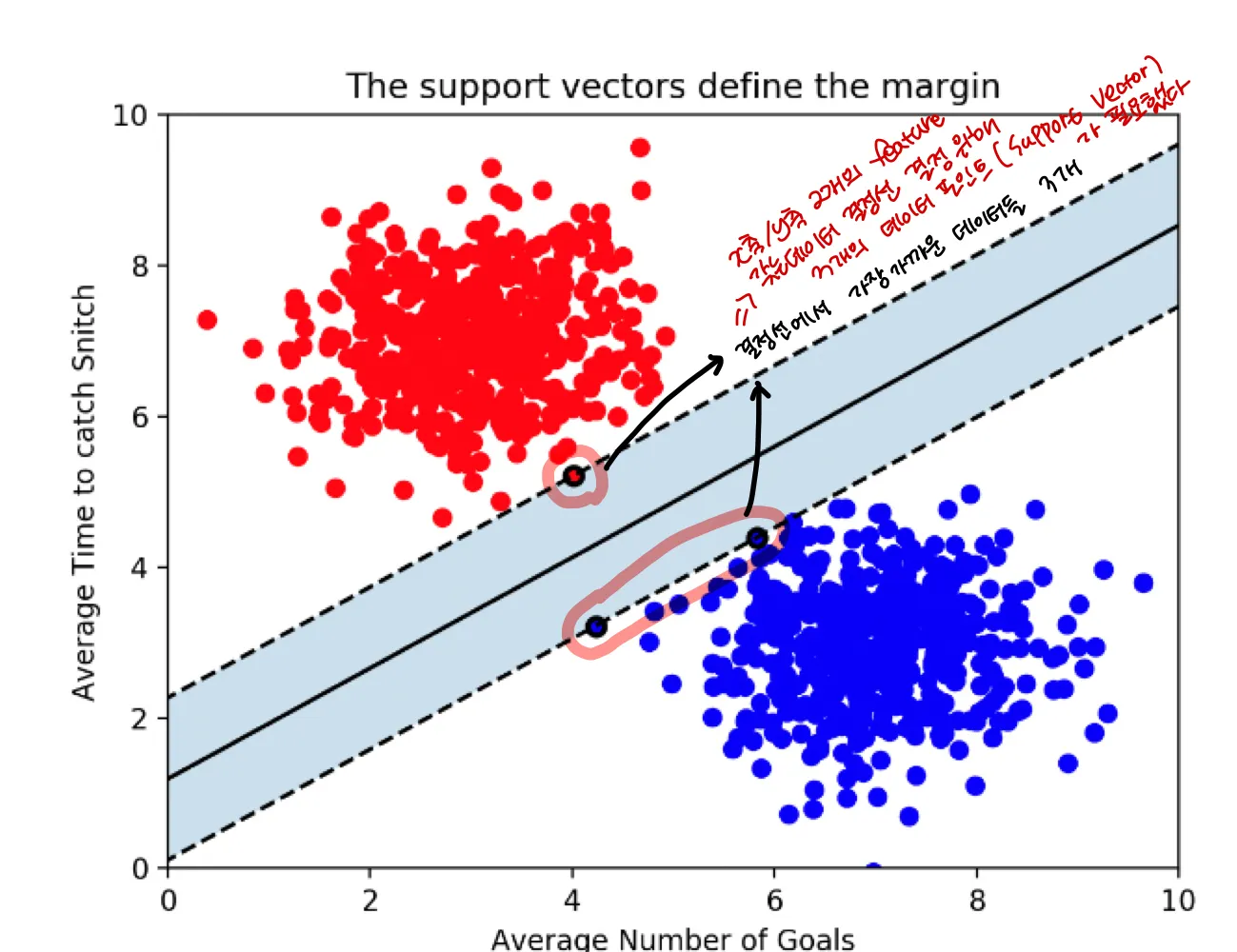
그림을 보고 알 수 있는 것은 n개의 feature 갖는 데이터는 최소 (n+1)개의 서포트 벡터가 존재한다는 것이다
⇒ 서포트벡터만 잘 골라내면 수많은 데이터를 고려할 것 없이 빠르게 Decision boundary를 구할 수 있다.
이를 위해 가장 중요한 것은 outlier를 다루는 일이다
1.
기준을 까다롭게 잡아 outlier를 허용하지 않은 경우
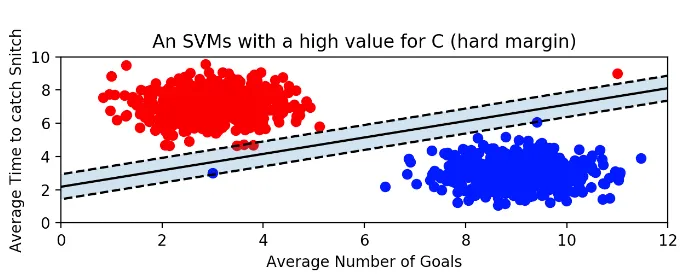
margin이 매우 작다 → hard margin → 개별적인 학습데이터를 다 놓치지 않으려해 overfitting 가능성 높아짐
2.
기준을 너그럽게 잡아 outlier를 어느정도 허용한 경우
margin이 비교적 크다 → soft margin → 그러나 너무 많은 데이터를 놓치게 되면 underfitting가능성이 높아진다
선형으로 Decision Boundary를 그릴 수 없을 때
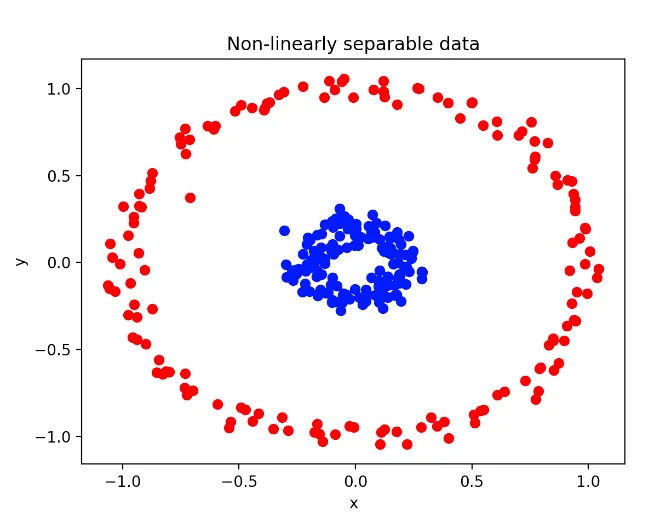
이렇게 직선으로 분류할 수 없는 데이터에서는 polynomial 커널을 사용한다
2차원의 (x, y) 좌표에 존재하는 점을 예를들면 3차원에 투영하는 것이죠
예를 들면
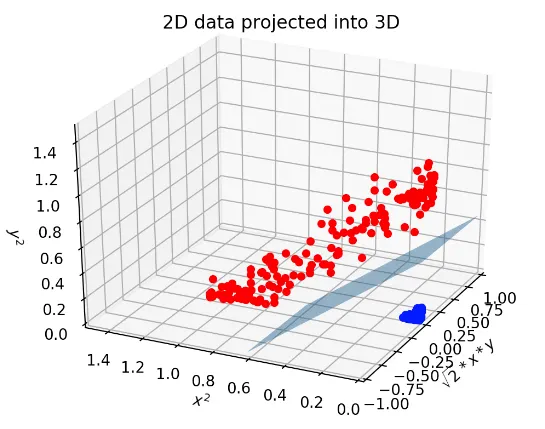
이런식으로 바꿔주면 이제 원래 하던대로 결정선을 그을 수 있는 형태로 바뀐다
