
기존 방식들이 logit 값이 높은 예측들을 pseudo ground truth label로 선택하는데 이로인해 대부분의 픽셀들이 사용되지 않아버리는 문제가 생긴다.
논문의 주장 : 예측값이 모호하더라도 모든 픽셀은 training에 영향을 미친다.

예를 들어 이런 상황이라면 높은 logit값을 갖는 클래스들 사이에서는 혼동이 되지만 person과 airplane이 아니라는 사실은 너무나 명확하게 나타나기 때문이다. → 이 클래스에는 속하지 않는다는 것이 confident!
따라서 이러한 샘플들은 negative sample로써 활용되어야한다고 주장한다.
•
이를 위해 entropy를 기준으로 하여 reliable / unreliable pixels를 분리하고 unreliable pixels를 category-wise queue에 넣어 negative samples로 관리한다. 여기서 reliable/unreliable 분류 위한 threshold는 training 진행 과정에서 adaptively적용한다.
•
또한 unreliable pseudo labels의 정보를 잘 이용하기 위해 contrastive loss를 활용한다.
[전체 모델 흐름도]

[total loss function]
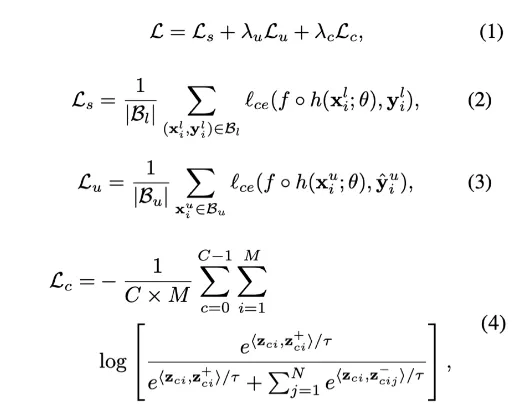
reliable / unreliable pixels 분류
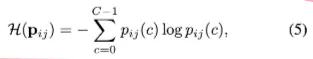

entropy 를 기준으로 \gamma_t보다 작으면 reliable하다고 판단하는데,
는 np.percentile(.flatten(), 100*(1-)) 로 정의 → 가 전체 상위 만큼의 비율이면 unreliable로 분류되게 된다.
여기서 는 epoch에 따라서 다음과 같이 정의된다. , : current training epoch
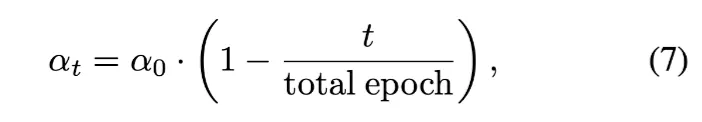
unsupervised loss의 비율인의 경우에는 reliable pixels의 수에 따라서 적응적으로 계산된다.
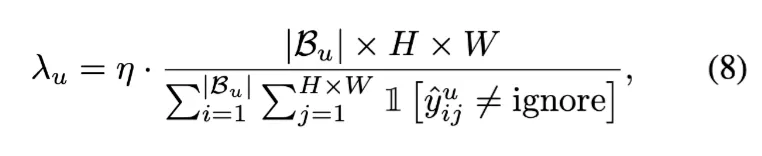
reliable pixels수에 대한 전체 픽셀 수의 비율이다. reliable pixels가 많을 수록 는 작아질 것이다
Unreliable pixels 사용 : contrastive loss
unreliable pixels도 사용하기 위해 위에서 말했던 해당 클래스에 속하지 않는다는 명확함을 이용해 negative samples로서 contrative loss로 활용한다.
c클래스에 대한 anchor pixels의 집합은 labeled data에서 GT class가 c인 features와 unlabeled data에서 pseudo label이 reliable하면서 class c에 속하는 features의 합집합이다.
positive samples
c클래스 내의 모든 anchors에게 positive sample은 모든 anchors의 중심이다
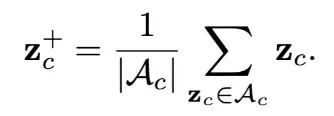
negative sampels
labeled image에 대해서는 1) class c에 속하지 않으면서 2) class c 와 GT class와의 분류가 어려운 픽셀들을 qualified negative samples로 정의하며 이를 판단하기 위해 pixel-level category order를 사용한다.
category order: = np.argsort()
: qualified negative sample이다 / 아니다를 나타내는 binary variable
labeled data에 대한
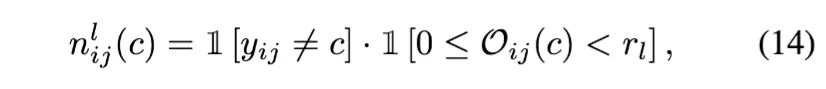
정답이 아니면서 순위 이하
unlabeled data에 대한
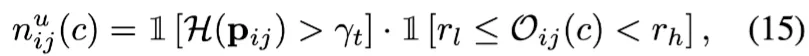
entropy 기준으로 unreliable하면서 이상 미만 순위인 것
여기서는 =20, =3으로 설정했다고 한다.
최종 negative samples 집합
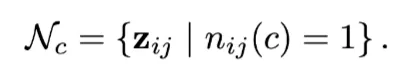
category-wise Memory Bank
dataset의 long tail 현상으로 인해 배치 내에서 특정 카테고리에 속하는 negative sampels가 부족한 현상을 해결하기 위함으로, memory bank를 통해 negative samples의 안정적인 수를 유지한다.
FIFO queue인 로 정의된다. → c 클래스에 대한 negative samples 저장
unreliable pseudo label 사용하는 전체 알고리즘

Details
ResNet 101 with ImageNet pretrained weights + Deeplabv3+ segmentation head
PASCAL VOC 2012 dataset
