참고자료들





Introduction
기존 NLP에서 SOTA로 자리잡고 있던 RNN류의 모듈들
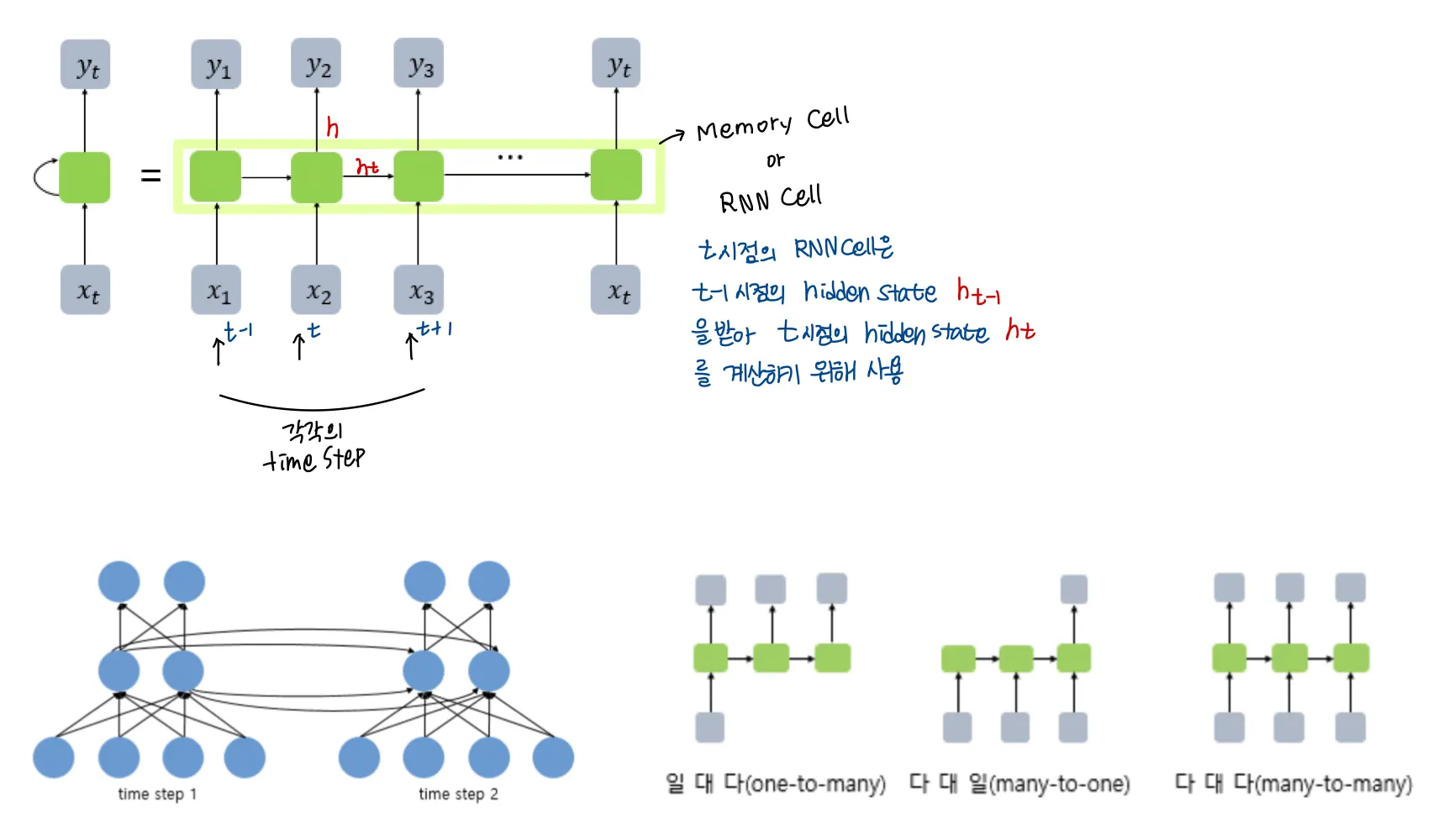
RNN의 단점
1.
병렬 연산이 불가능해 메모리 제약으로 batch 크기가 제한된다.
2.
Sequence의 길이가 길어질수록 정확도가 낮아진다.
⇒ 연속적 연산의 한계
이러한 단점을 극복하기 위해
•
입출력 sequence에서 서로 거리에 상관없는 dependency를 허용하는 Attnetion mechanism이 중요해졌고,
•
recurrent network와 attention mechanism을 함께 사용하던 이전 연구와 달리 Transformer는 오직 attention mechanism에 전적으로 의존하는 구조이다.
•
Transformer는 병렬화에 유리하여 8개의 P100으로 12시간 학습만에 번역 task에 대해 SOTA를 달성했다고 한다.
•
Transformer가 사용한 attention mechanism은 intra-attention이라고도 불리는 self-attention이다. 한 시퀀스의 representation을 계산하기 위해 단일 시퀀스의 서로 다른 위치들을 관련시킨다. ( 독해 / 생성요약 / 문맥추론 / task 비의존적 문장표현 등 다양한 task에서 성공적으로 사용 )
•
End-to-End memory network는 배열된 시퀀스의 recurrent network가 아니라 재귀적 attention mechanism을 기반으로 해 단일언어 QA(Question - Answering)이나 언어 모델링 task에 좋은 성능을 보였다.
그러나 트랜스포머는 입출력 representation 계산 위해 Sequence 할당 RNN이나 convolution없이 self attention에만 의존하는 최초의 변환 모델이다.
QA: 주어진 텍스트 (P)에 대해 질문(Q)이 주어지면, passage와 question 내에서 좋은 답을 내어놓는 것이 주요 태스크
Architecture
트랜스포머의 전체적인 구조는 encoder-decoder 구조를 따르며,
•
encoder는 입력 sequence 을 받아 continuous representation 을 반환한다.
•
decoder는 를 사용해 출력 sequence 를 반환한다.
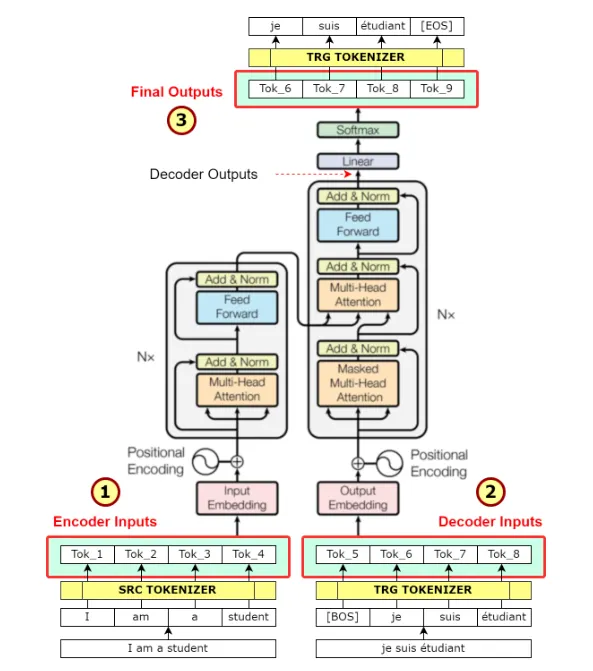
그림을 보면 영어 → 독일어 변환이라고 했을 때, encoder에 영어 input이 token형태로 들어가면, embedding된 후 encoder로 들어가고, decoder에서는 독일어 target의 token이 embedding되어 들어가고 encoder의 output을 입력으로 받는다. final output은 변환된 문장 + [EOS]가 된다.
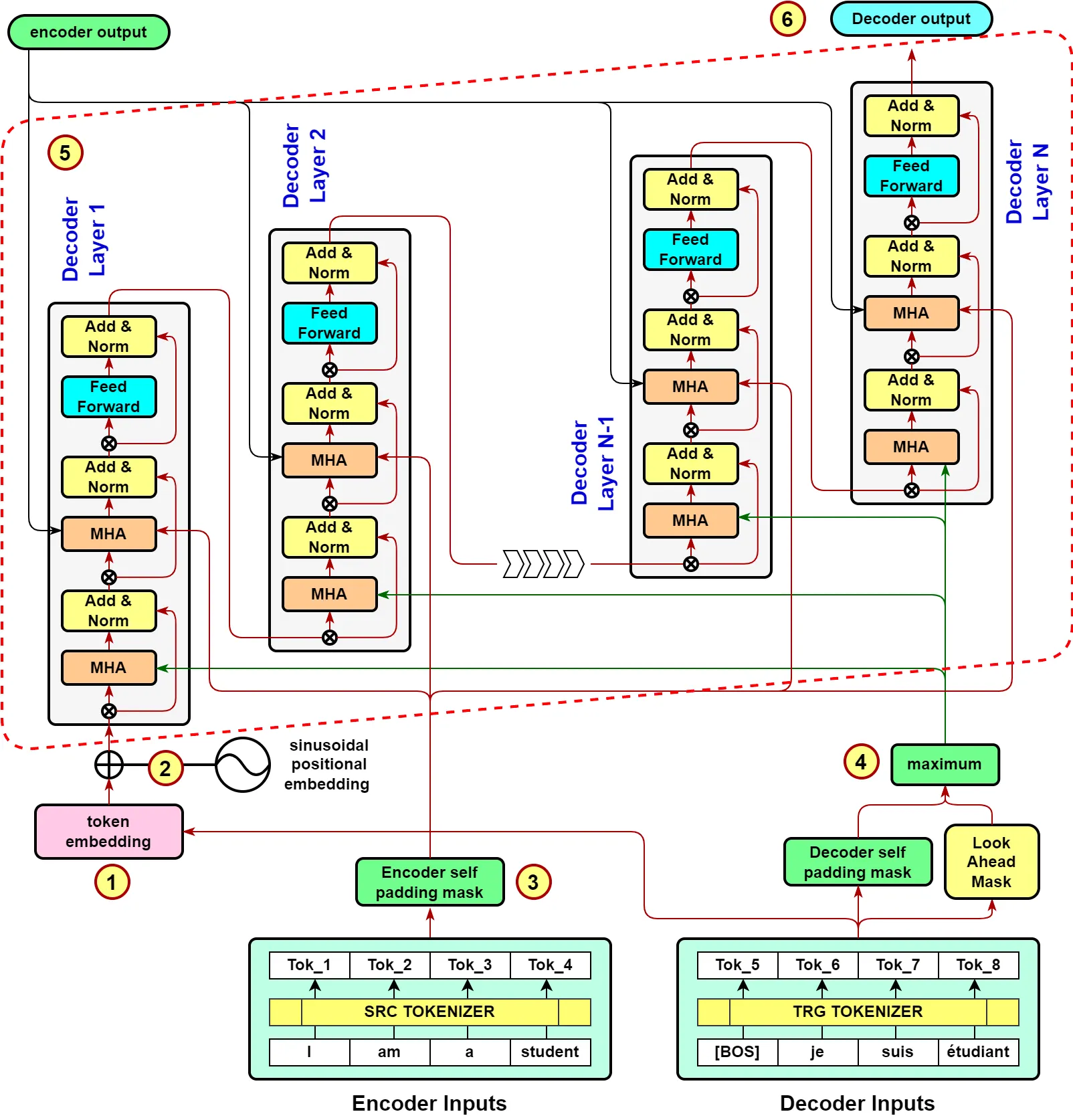
Transformer는 다음과같이 보통 4개의 클래스로 구현된다
1.
Encoder Layer
2.
Decoder Layer
3.
Encoder
4.
Decoder
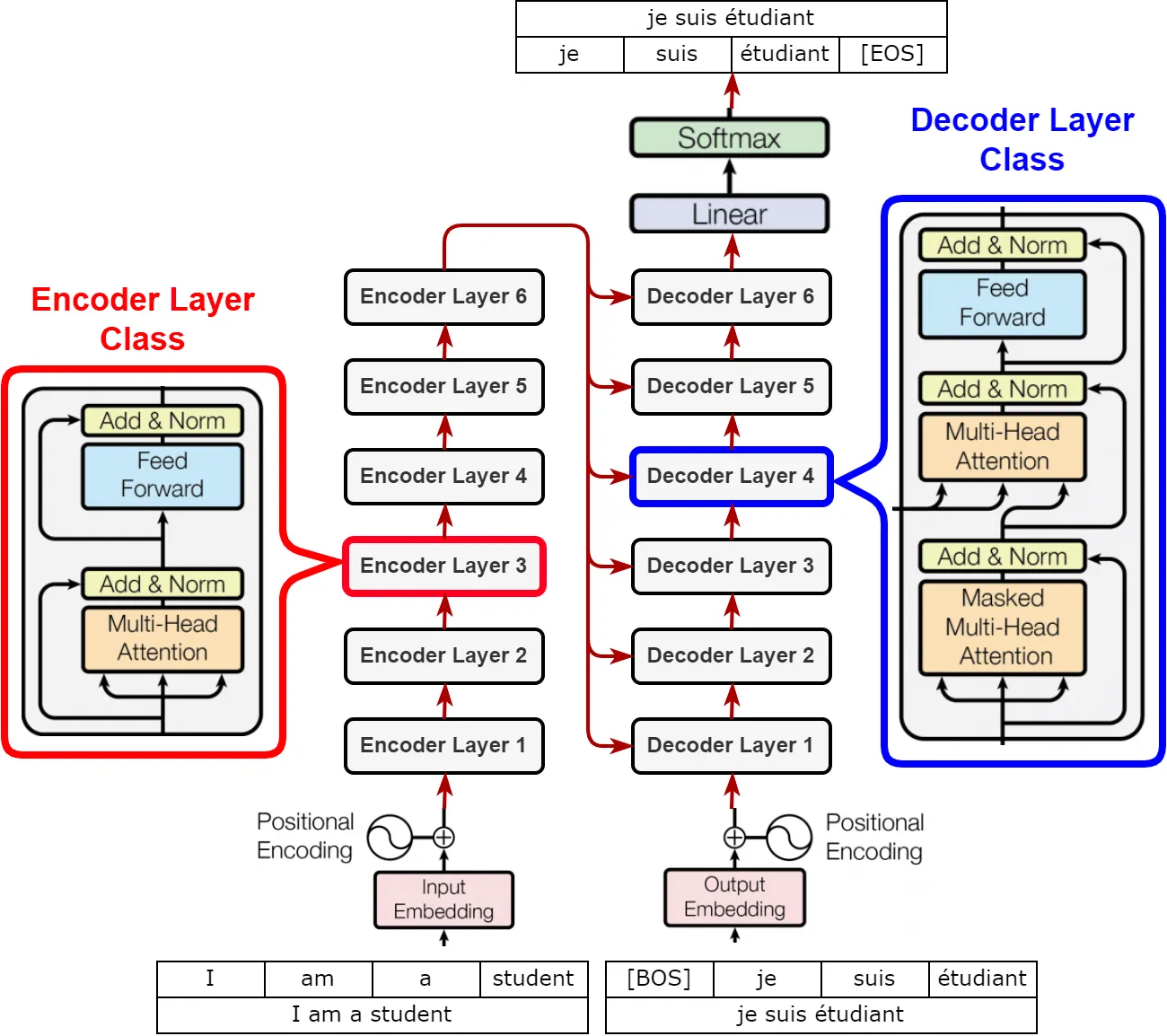
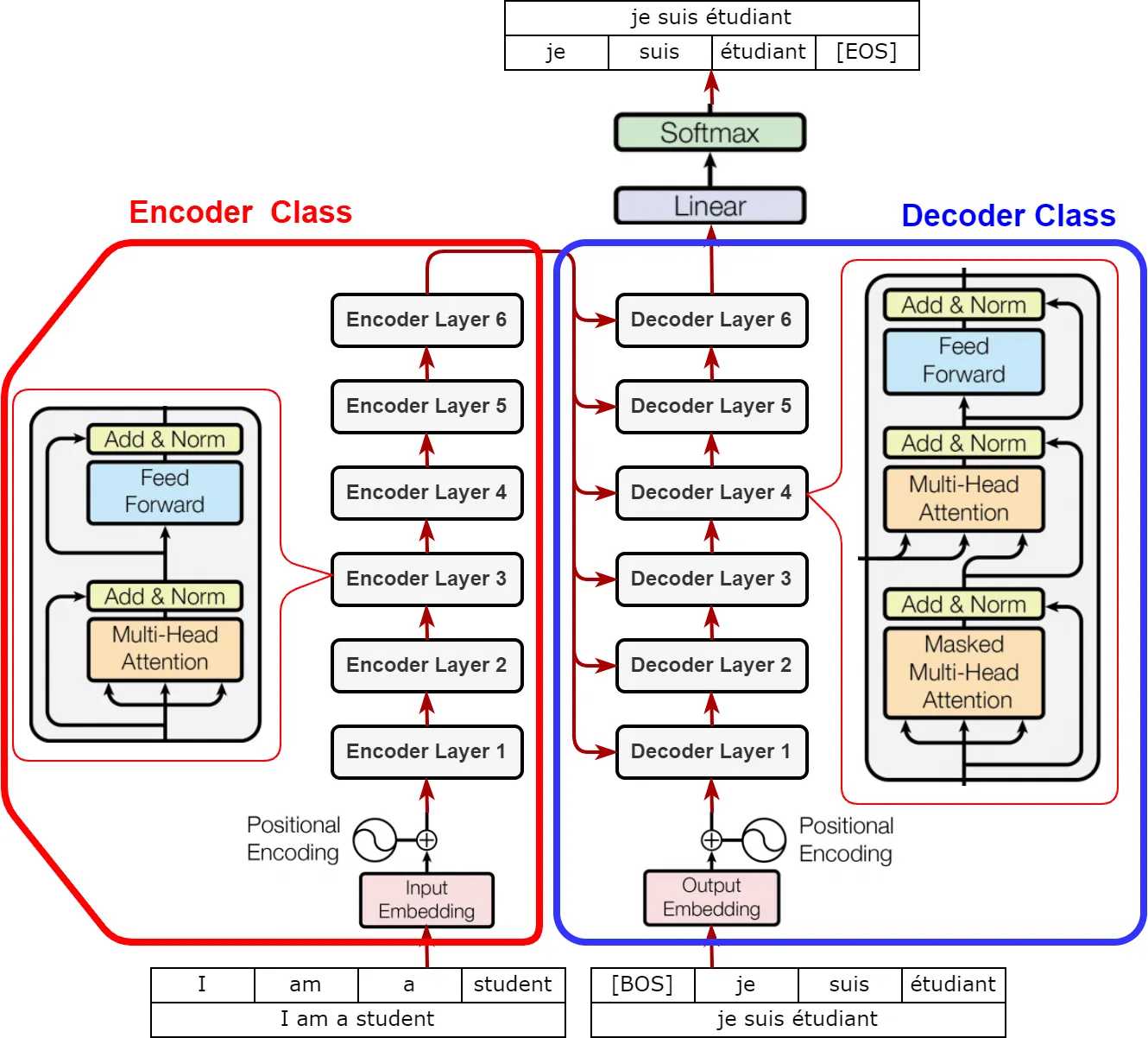
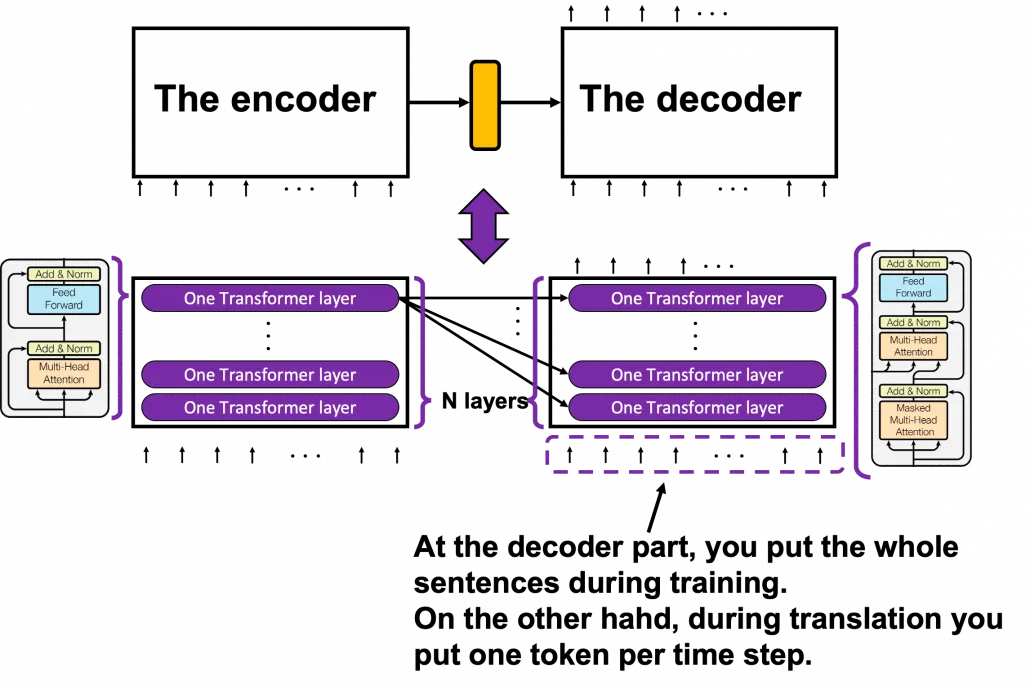
encoder 부분에서 N개의 레이어로 원래 입력 문장을 계속해서 변환하면, decoder부분에서는 N개의 레이어로 입력을 변환하면서 모든레이어에서 encoder 최종 output을 입력으로 받는다.
전체적인 흐름은 다음과 같다
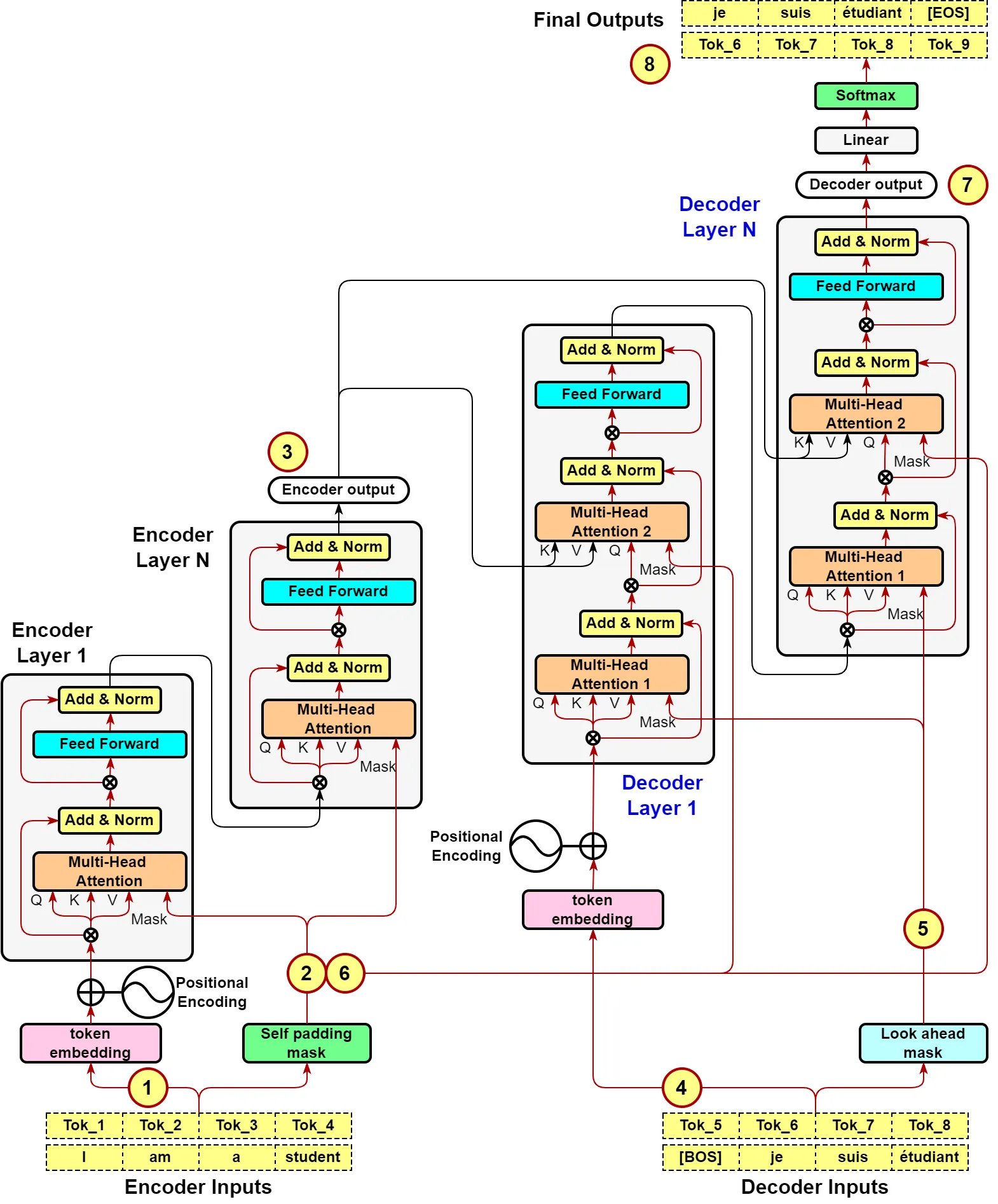
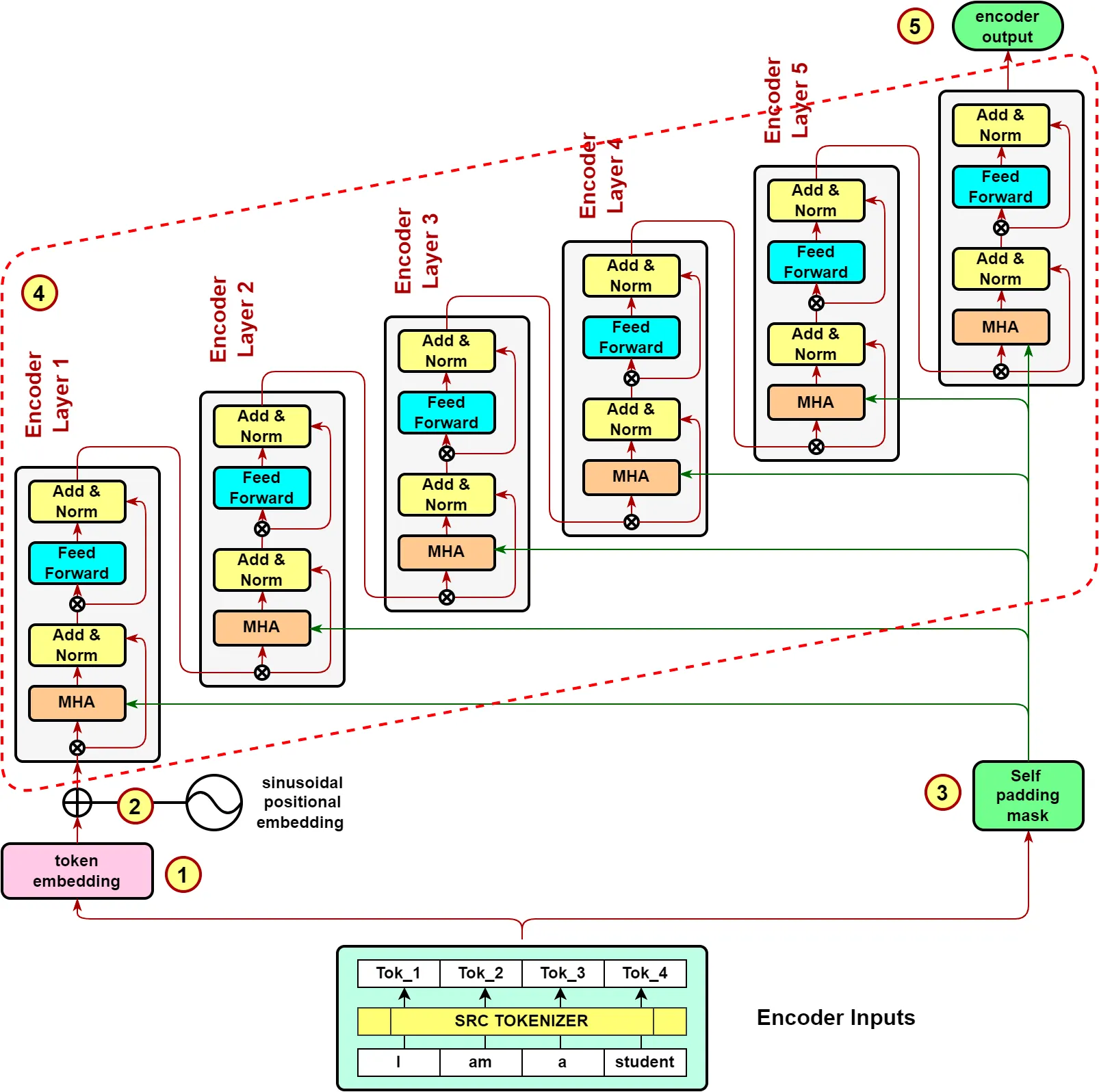
Encoder
encoder의 경우 동일 레이어 encoder 6개를 병렬로 연결해 구성한다.
encoder inputs : Source sentence가 source tokenizer에 의해 생성되는 indexed tokens ( [BOS] 나 [EOS]를 제외하고 만들어지지만 추가되기도 한다. )
special tokens
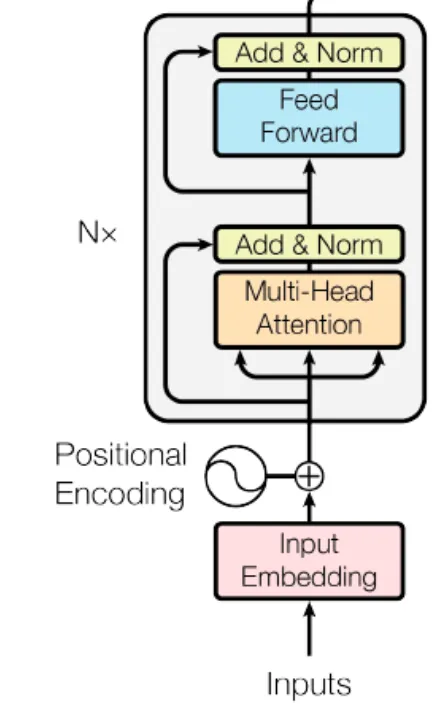
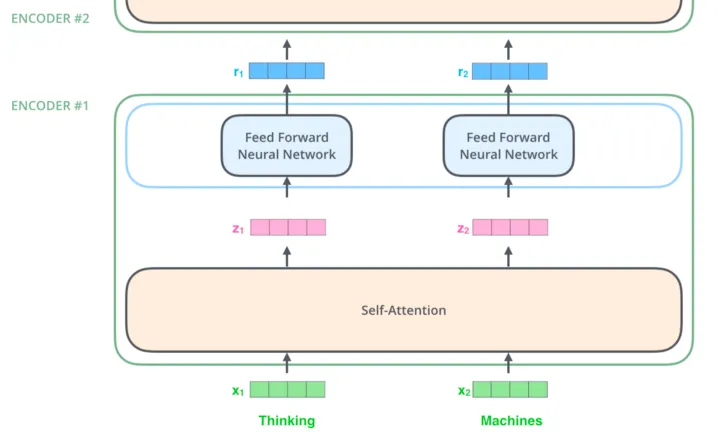
Encoder Layer의 2개의 sub-blocks
1.
multi-head self-attention mechanism
2.
simple position-wise fully connected feed-forward network
add & norm은 두 sub layer 각각에서 residual connection( )과 layer normalization을 사용한다. → residual connection이 있기에 sublayer들의 입력과 출력의 차원은 동일해야 한다. ( 512로 사용했다고 한다 ) → 각 sub block의 최종 output
6개의 레이어를 가진 encoder는 다음과 같이 그려진다
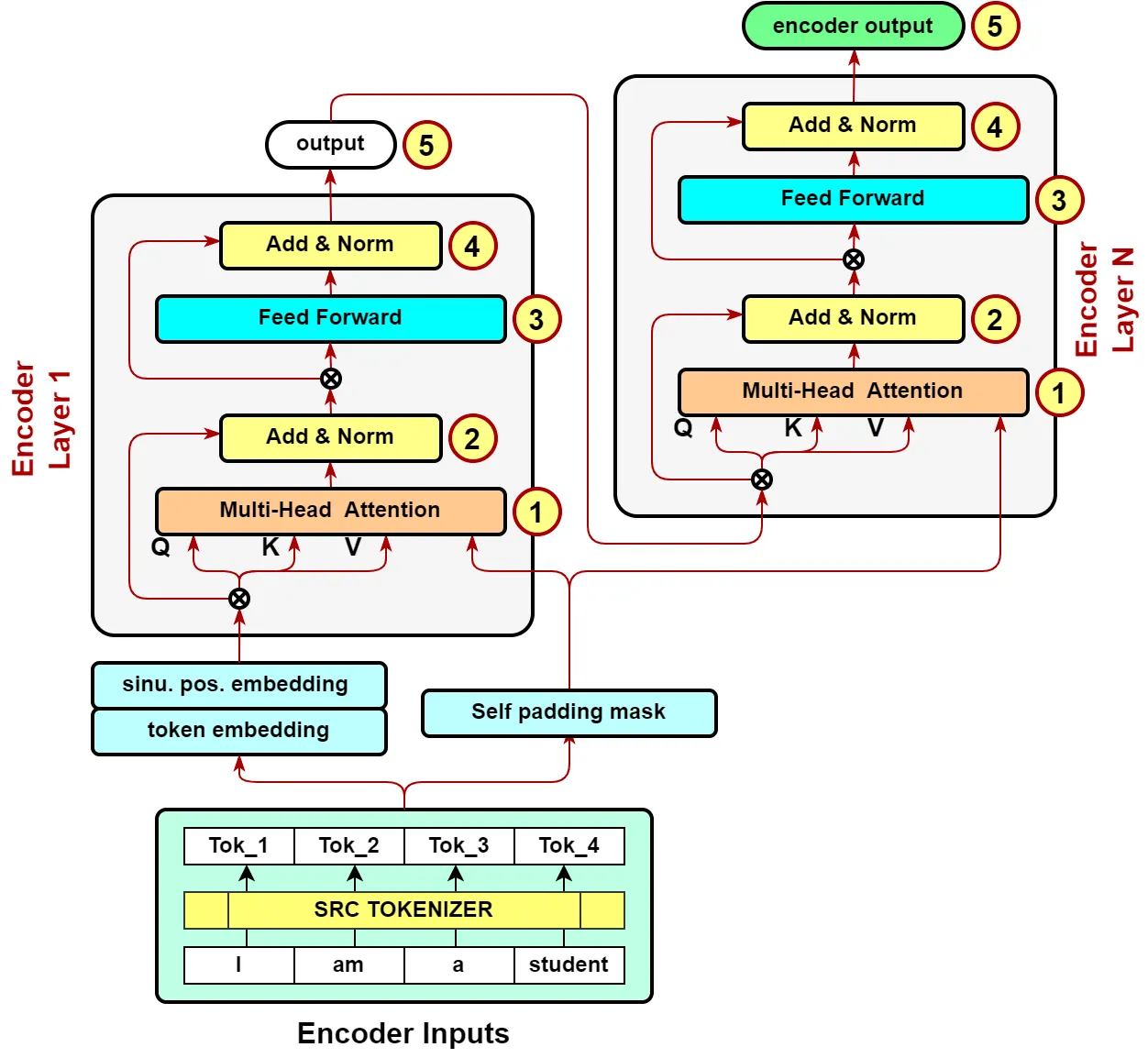
encoder의 output 생성 과정
1.
Encoder input의 token embedding
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
Python
복사
2.
sinusoidal positional encoding ( BERT에선 nn.Embeding으로 대체 )
3.
encoder input으로부터 self padding mask 생성
4.
encoder layers 가 stack됨
self.enc_layers = [EncoderLayer(pf_dim, hid_dim, n_heads, dropout)
for _ in range(n_layers)]
Python
복사
5.
final layer의 output이 encoder의 최종 output
self attention module
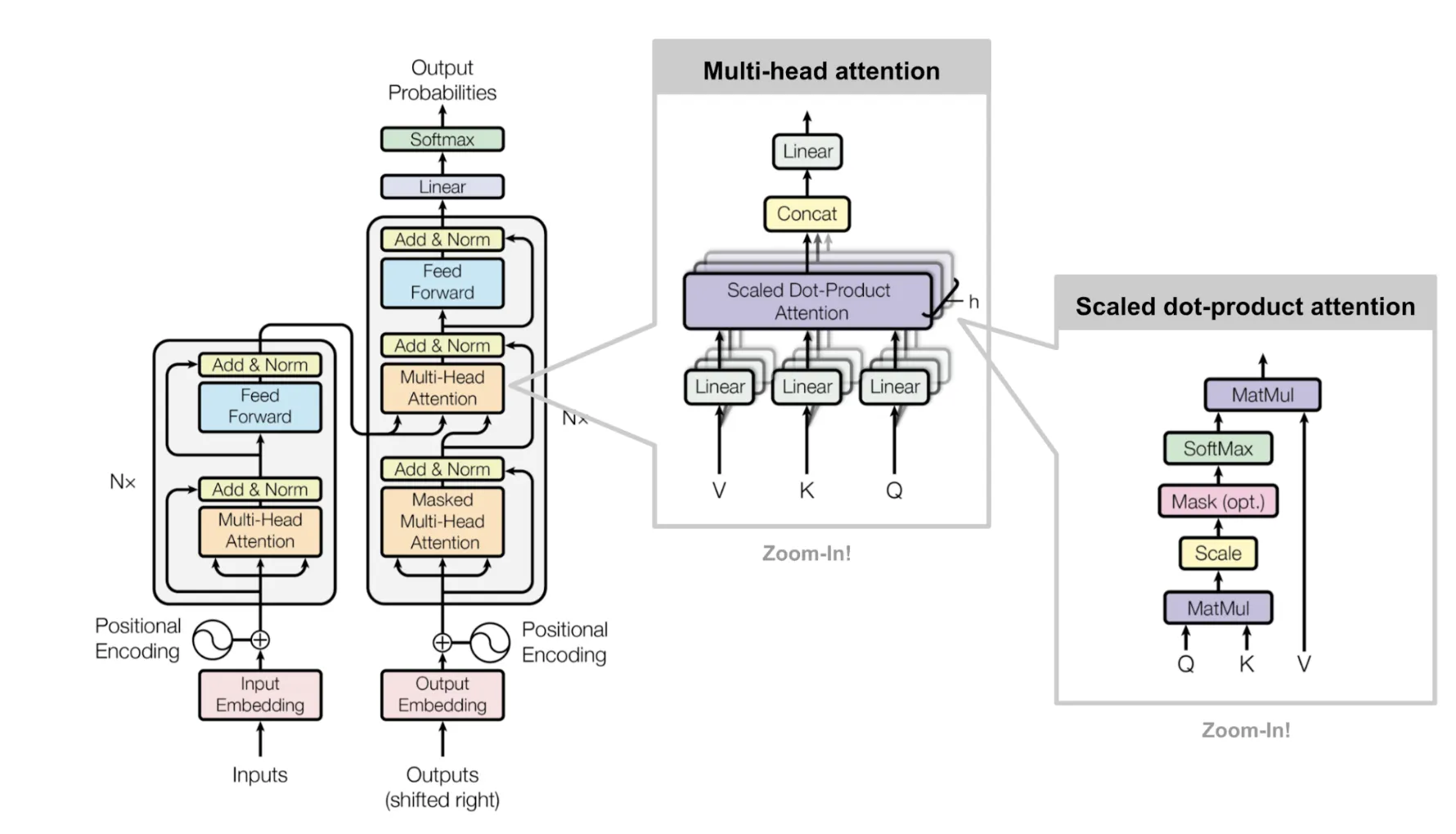
Multi-Head attention과 scaled dot-product attention은 다음 그림과 같다.
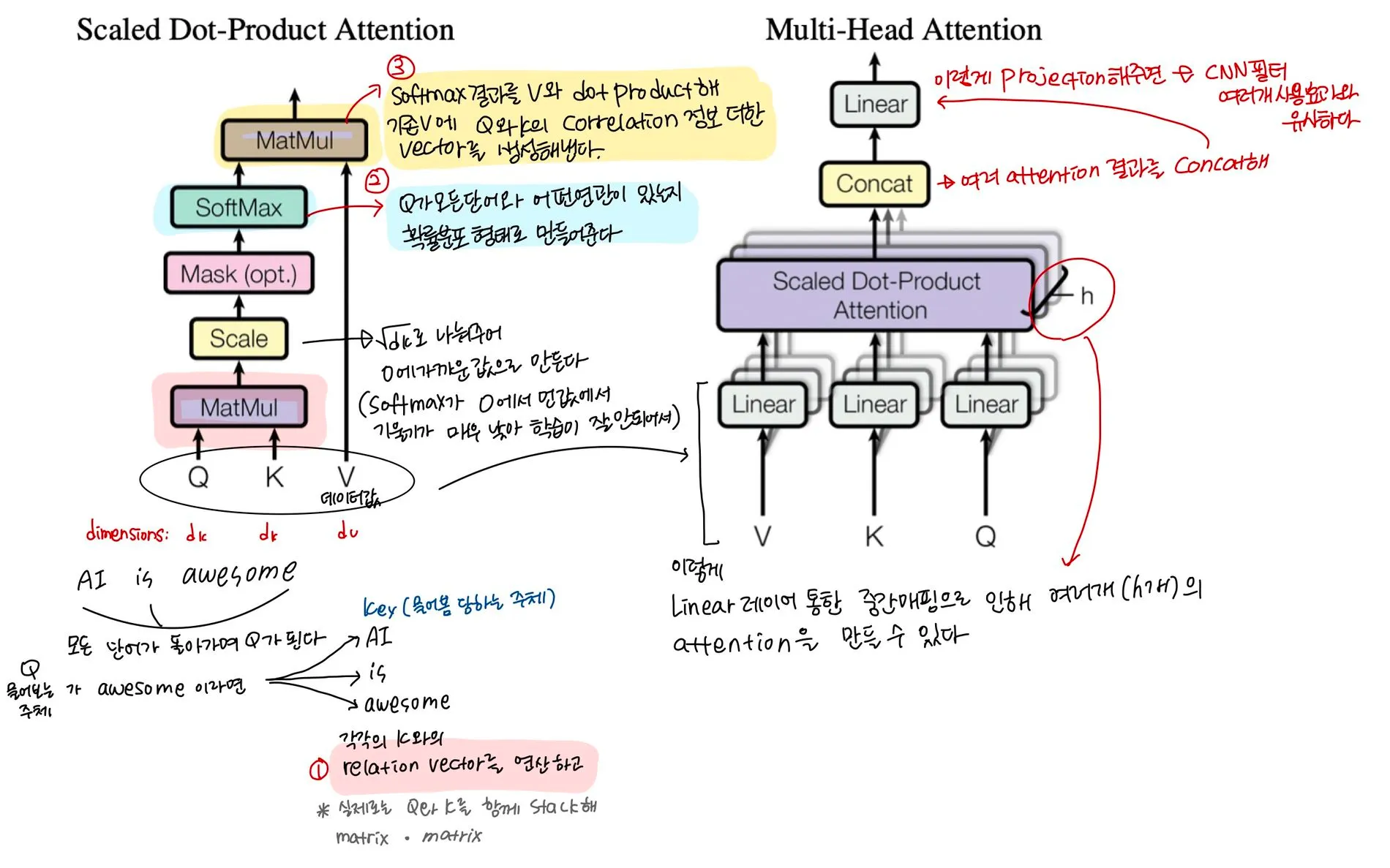
•
Query vector : 현재 처리하고자 하는 token을 나타내는 vector. 영향을 받는 단어 A를 나타내는 변수
•
Key vector : 영향을 주는 단어 B를 나타내는 변수
•
Value vector : 그 영향에 대한 가중치. key와 연결된 실제 토큰을 나타내는 vector
self attention의 전체적인 흐름을 정리하면
1.
Q와 K를 비교해 value에 대한 가중치 / score를 얻는다. 가중치 / score는 Q와 K의 관련성을 의미한다.
2.
이 가중치 / score를 value에 부여해 reweighted values를 구한다.
※ key와 query는 같은 단어일 수 있다
실제로 임베딩되어 입력으로 들어가는 차원을 그림으로 나타내면 아래 그림과 같다.
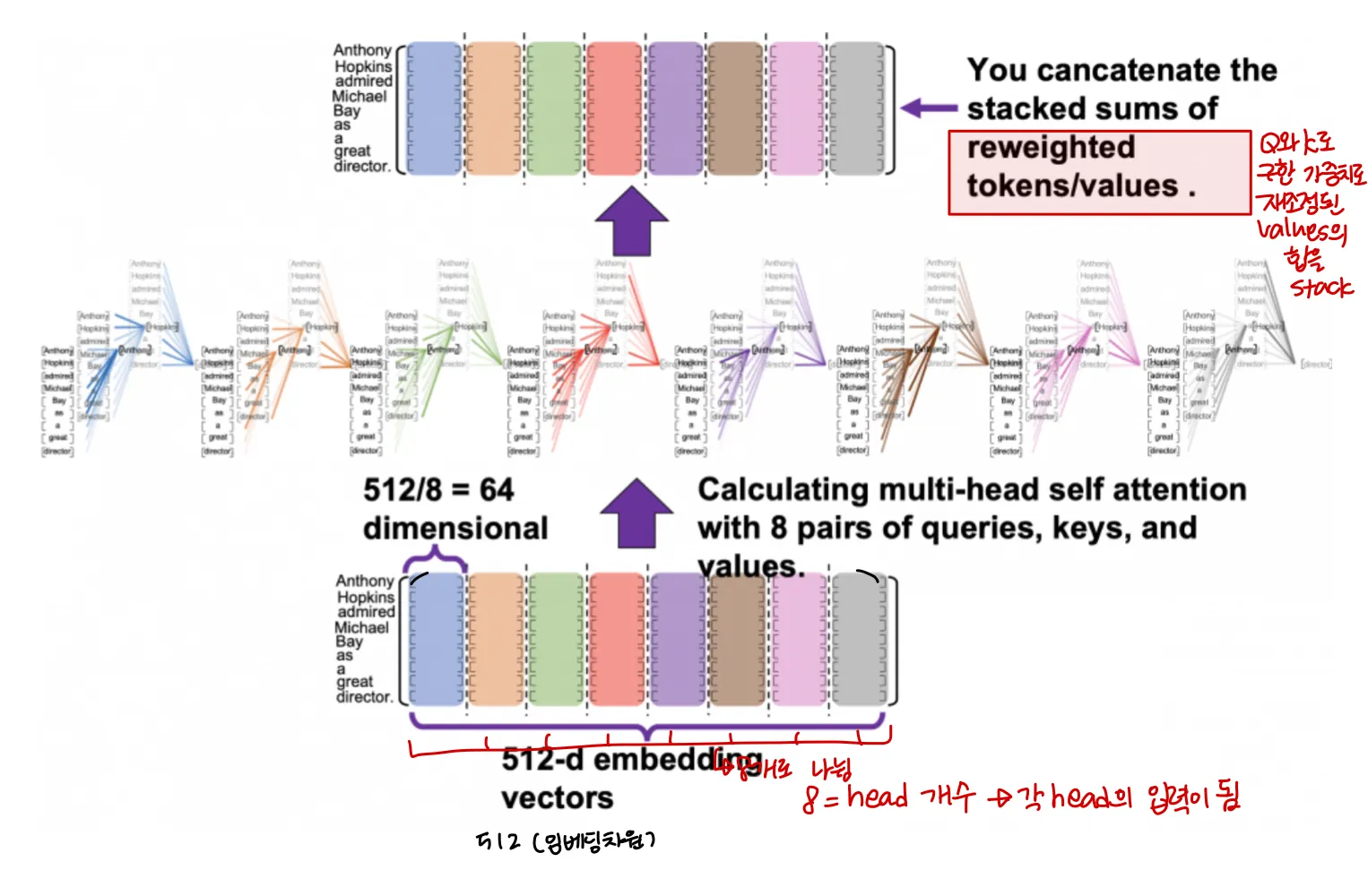
head 개수가 8개라면 한 단어에 대한 전체 임베딩차원을 8개로 나누어 각각 하나의 head로 들어가게 된다.
그림에서 다른색깔로 표현된 8개의 (9, 64) 텐서들은 모두 같은 문장을 나타내고, 각각 독립적으로 self attention을 수행해 value를 reweight한다. 각 색상은 각 head를 나타낸다고 볼 수 있다. 각 head에서 나온 reweighted values의 합계를 쌓아 다시 연결하면 입력 embedding과 같은 shape의 결과가 나온다.
각 head는 각각 다른 기준으로 Q와 K를 비교하게 된다. 만약 encoder 레이어로 이뤄진 Encoder가 8head를 가진다면 개의 다른 기준을 가지고 Q와 K가 비교된다.
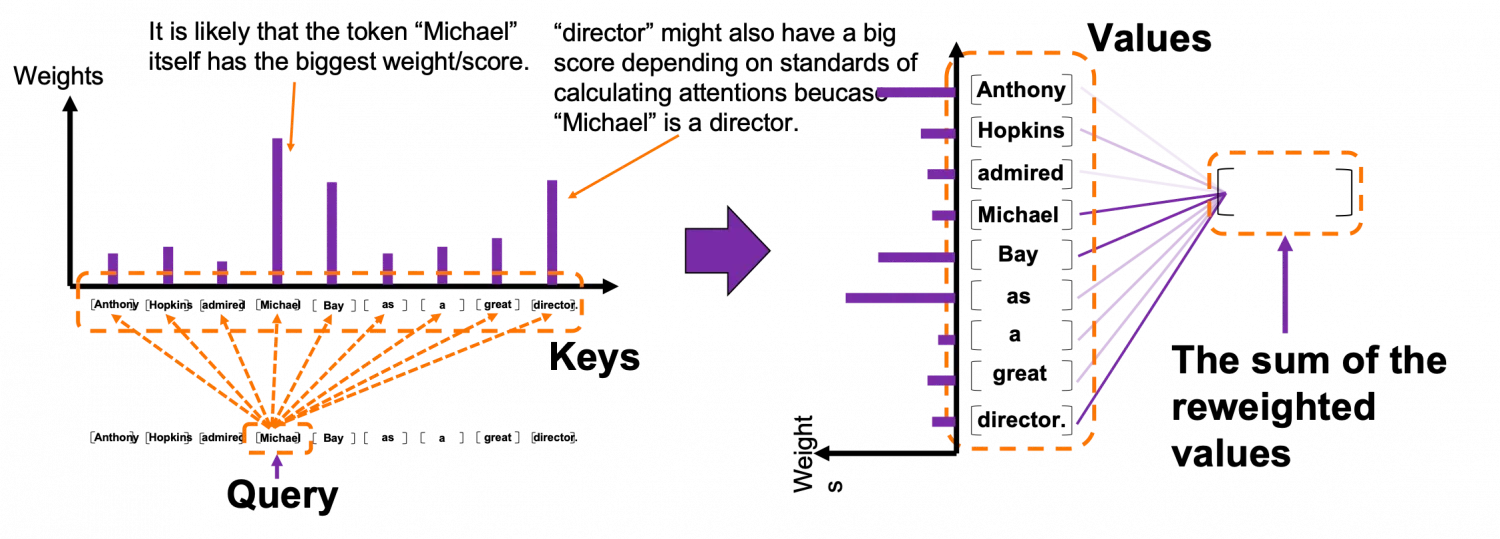
위의 그림은 “Michael”이라는 Query와 Keys와의 관련도( 가중치 )를 그림으로 나타낸 것이다. softmax를 사용하기에 각 weights의 합은 1이다. 이 weights로 reweighted values를 생성한후 합계를 구하는 과정이 위의 그림에 나타나있다. 이 과정을 모든 query에 대해 반복한다.
"query" 토큰 "Michael"과 비교하여
"key" 토큰 "Anthony", "Hopkins", "admired", "Michael", "Bay", "as", "a",
" great', 'director'의 weights는
각각 0.06, 0.09, 0.05, 0.25, 0.18, 0.06, 0.09, 0.06, 0.15입니다.
이 경우 재가중된 토큰의 합계
-> 0.06″Anthony” + 0.09″Hopkins” + 0.05″admired” + 0.25″Michael” + 0.18″Bay”
+ 0.06″as” + 0.09″a” + 0.06″great” + 0.15″director.” 가 실제로 사용된다.
※ 각 토큰은 실제로는 벡터값이다
Plain Text
복사
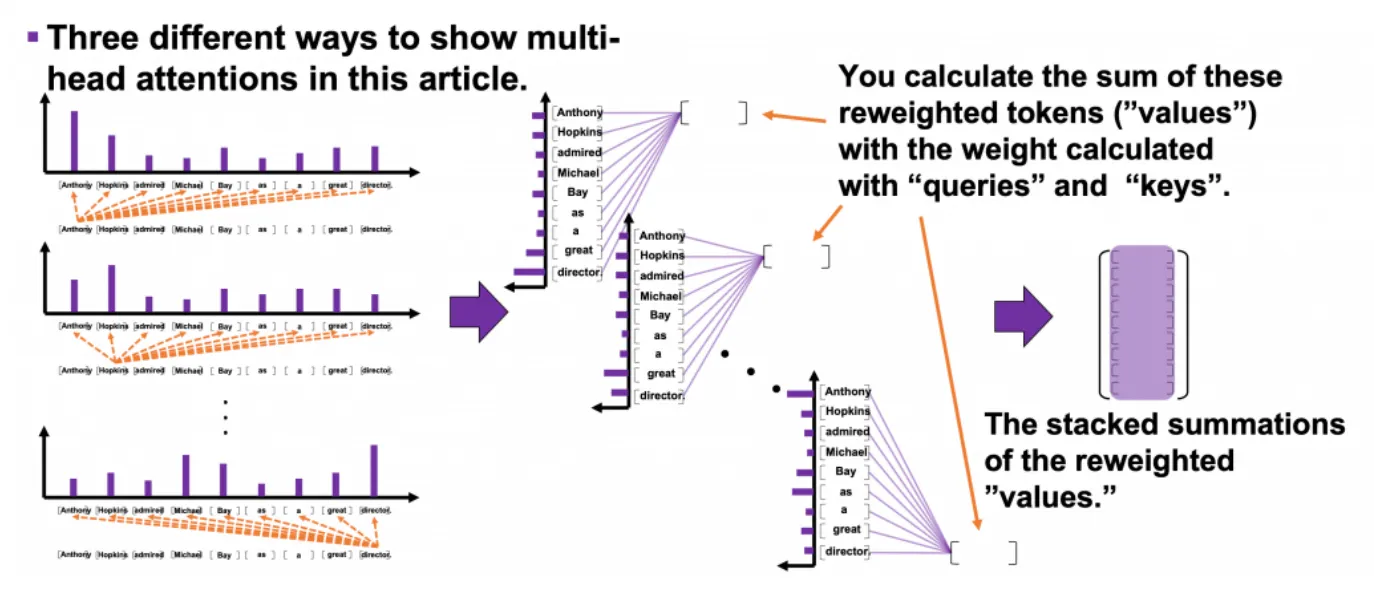
위의 그림처럼 모든 query에서 반복되어 생성된 reweighted values 9쌍의 합계가 stack된 것이 하나의 head의 output이다.
맨 위에서 "Anthony"를 query로 하여 각 key들에 대한 관련도를 구해 values를 rewight
-> value의 차원도 512차원이라고 했을 때
Plain Text
복사
하나의 Query에 대한 연산의 더 간단한 예시
더 디테일하게 살펴보면
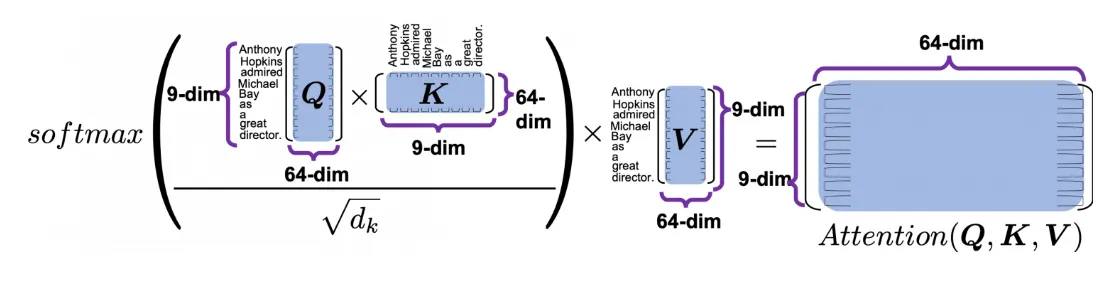
(9, 64)의 Q와 (64, 9)의 K가 matmul되어 (9, 9)차원의 가중치가 연산되면, (9, 64) 차원의 value에 matmul이 되어 ( 9, 64)의 attentioned values ( reweighted values )를 결과로 내놓게 된다.이
각 과정을 더 세부적으로 표현한 것이 아래 그림이다
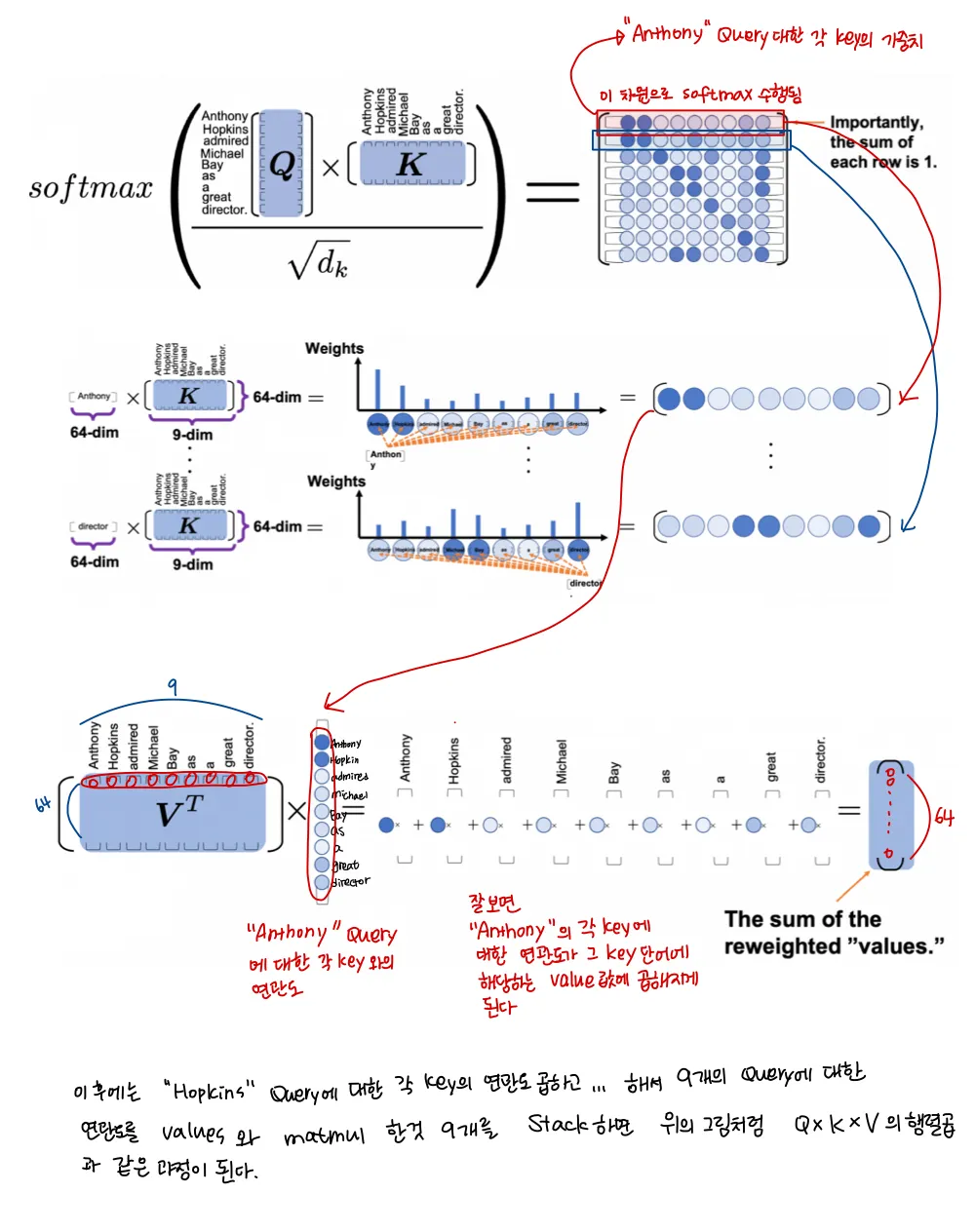
이 과정을 모든 head에서 반복하고, concat해서 Linear 레이어에 넣으면, multihead attention이 수행된다
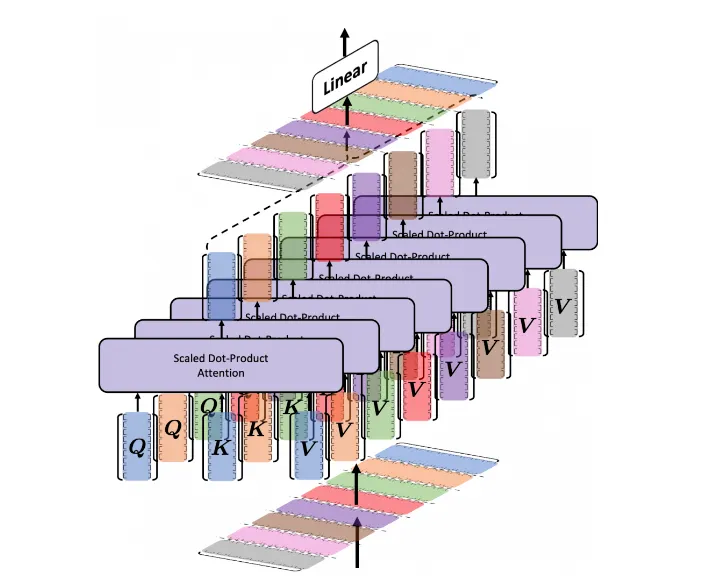
feed-forward module
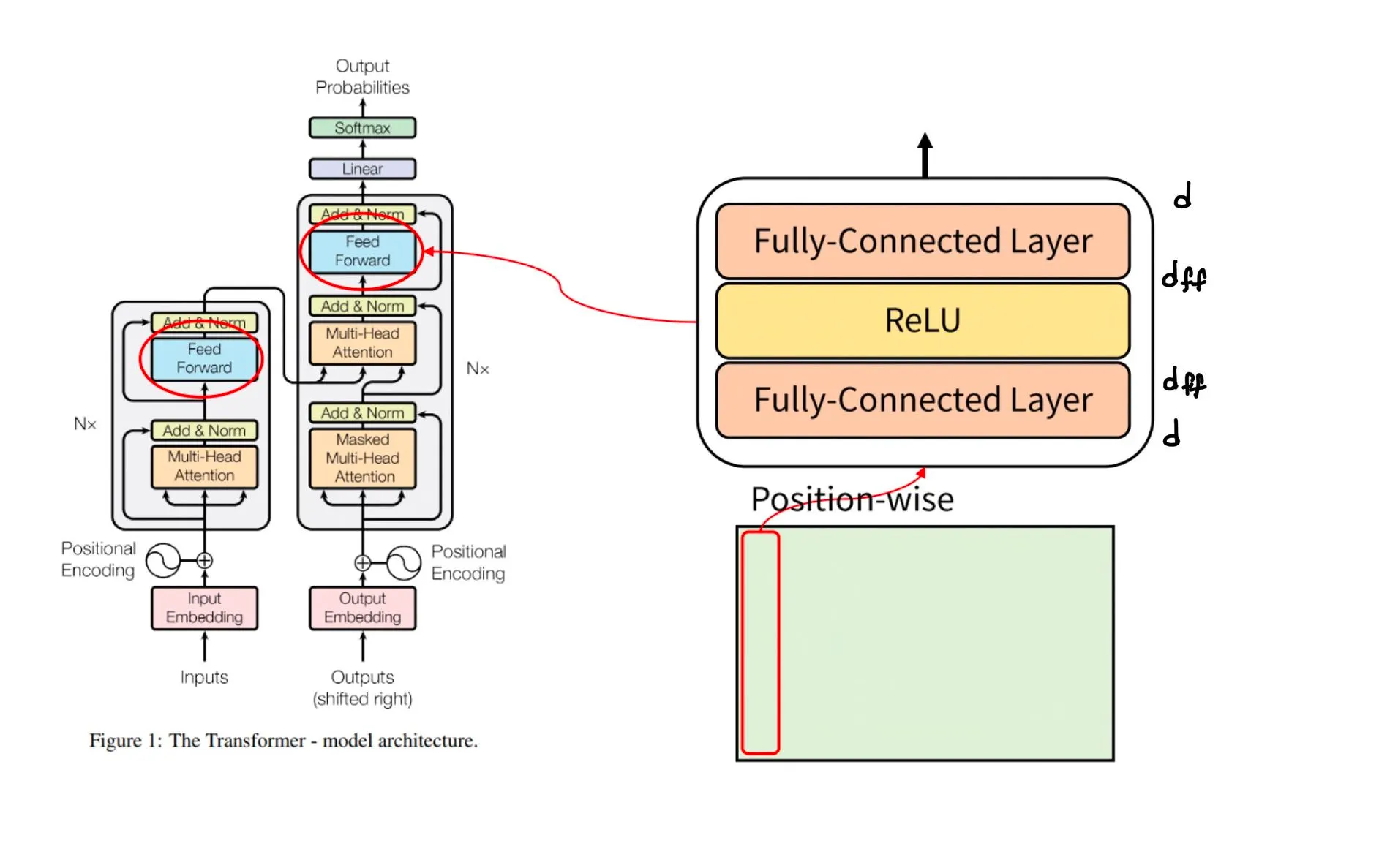
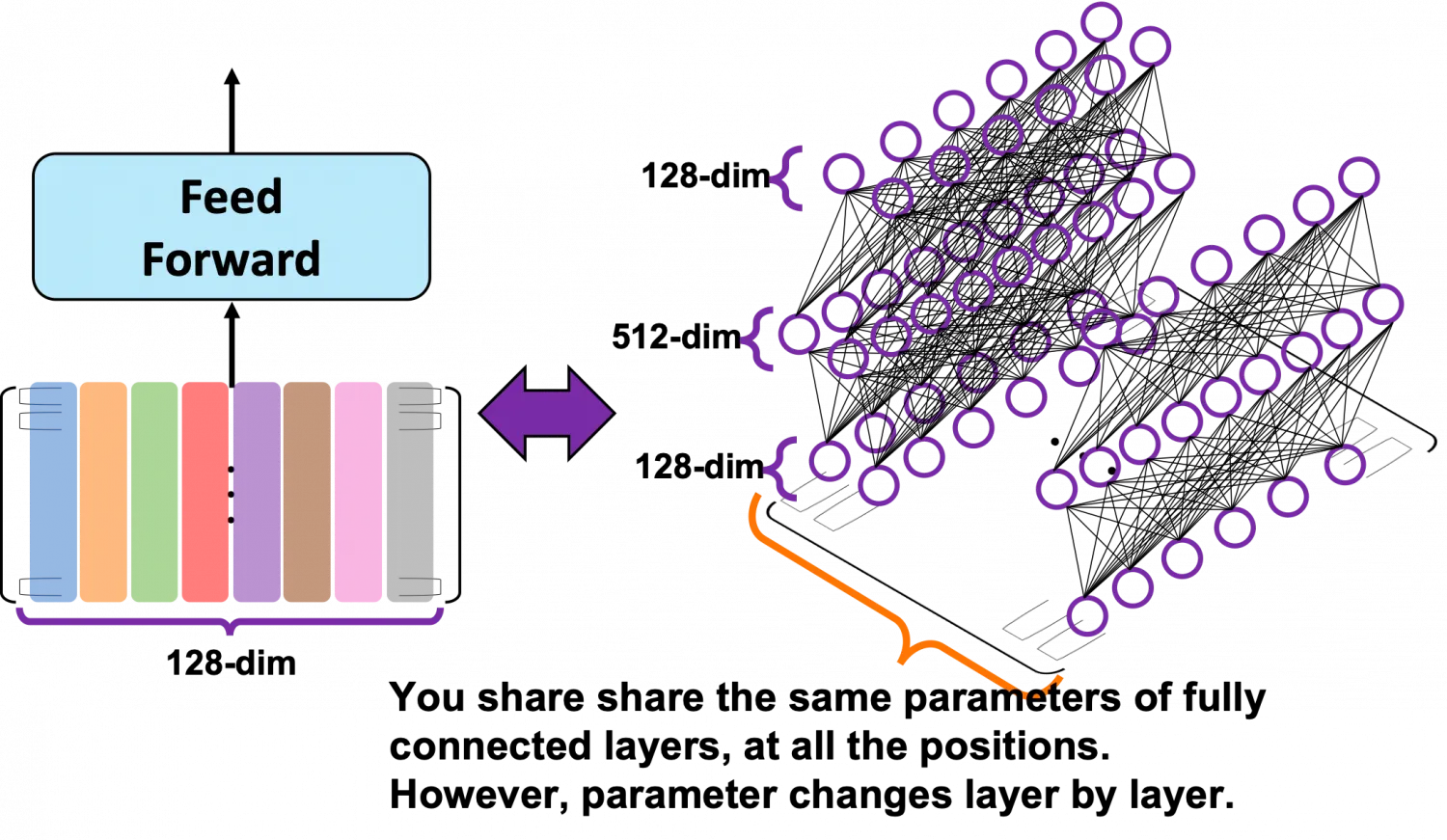
그림을 보면 문장의 모든 위치에서 동일한 파라미터를 공유하고 있다.
중요하게 생각해야할 것은 파라미터 수가 input / target 문장의 길이에 의존하지 않는다는 것이다. multi head attention이 이를 가능하게 한 것이다.
Decoder
decoder inputs : [BOS] + Target sentence가 target tokenizer에 의해 생성되는 indexed tokens
( teacher forcing 개념을 사용하기에 [BOS] 토큰을 추가한다 )
또한 decoder에서는 문장의 형태 / 가중치를 재조정한 값을 레이어별로 유지하게 돼 transformer 모델의 계산 효율을 높였다.
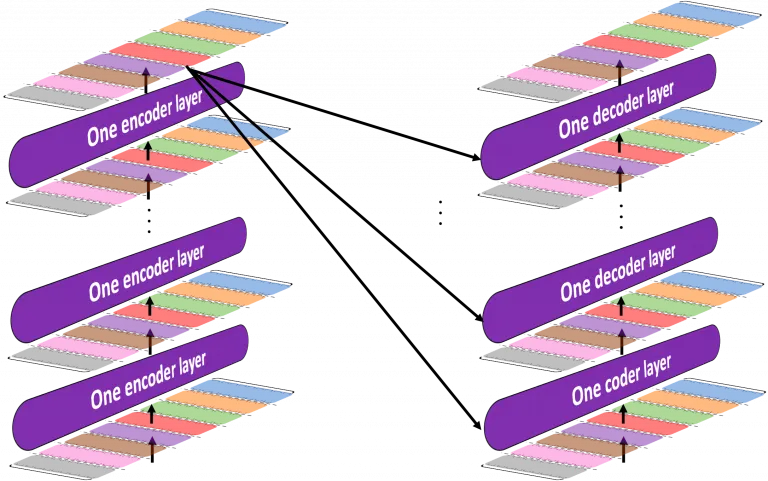
final outputs : Target Sentence + [EOS]가 target tokenizer에 의해 생성되는 indexed tokens.
(teacher forcing 개념을 사용하기에 [EOS]토큰을 문장 끝에 추가해준다)
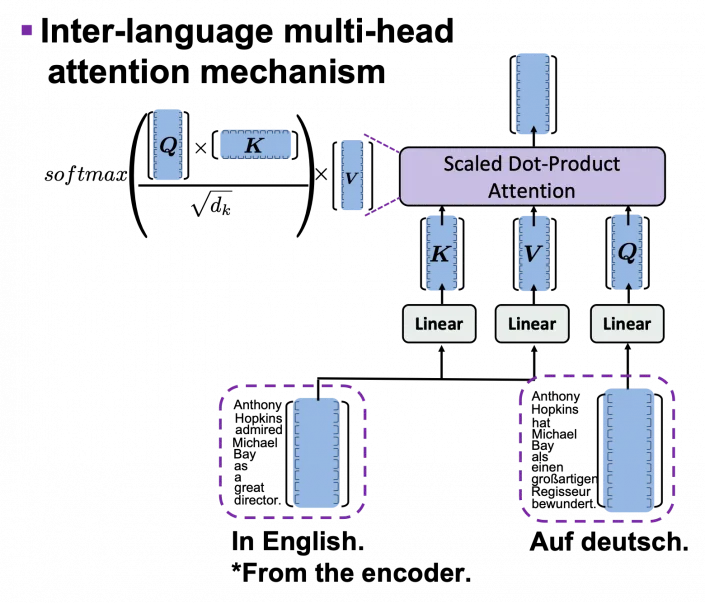
위의 그림에서 보여주는 것은 Decoder의 self-attention multihead attention 뿐 아니라 inter-language multi-head attention mechanism도 가지고 있다. 영어→독일어 변환의 경우에서 encoder의 output인 영어문장의 정보와 독일어 문장의 정보를 비교하게 되는 것이다.
encoder와 더 자세히 비교를 하자면, K, V는 input 문장에서, Q는 target 문장에서 나오는 것이다. 독일어 Q를 영어로된 input문장의 K와 비교를 하게되면서 영어로 된 문장을 다시 reweighted하게 된다. 이렇게 가중치가 재조정된 영어문장을 decoder에서 사용하게 된다.
이 과정을 더 구체적으로 살펴보면
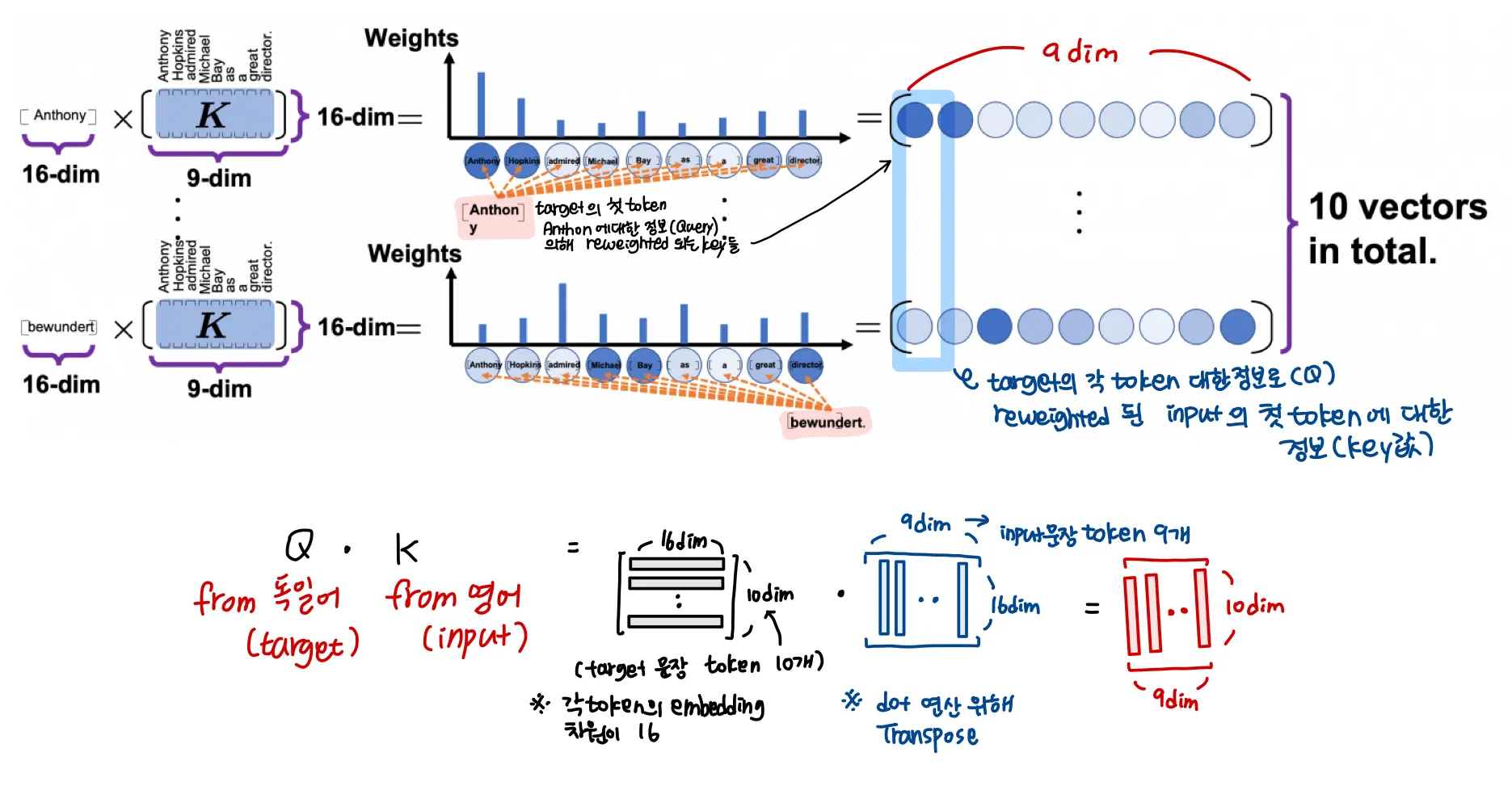
그림에 설명된 것처럼, input 문장인 영어 문장의 정보인 key값들이 target 문장인 독일어 문장의 정보값으로 reweighted되는 것을 볼 수 있다.
연산을 위해 K가 transpose되고 matmul이후 downscale되는 것과 softmax처리까지 나타내면 앞에서의 식처럼 가 되고 최종 multihead attention map은 위에서 나타낸 것처럼 행렬이 된다.
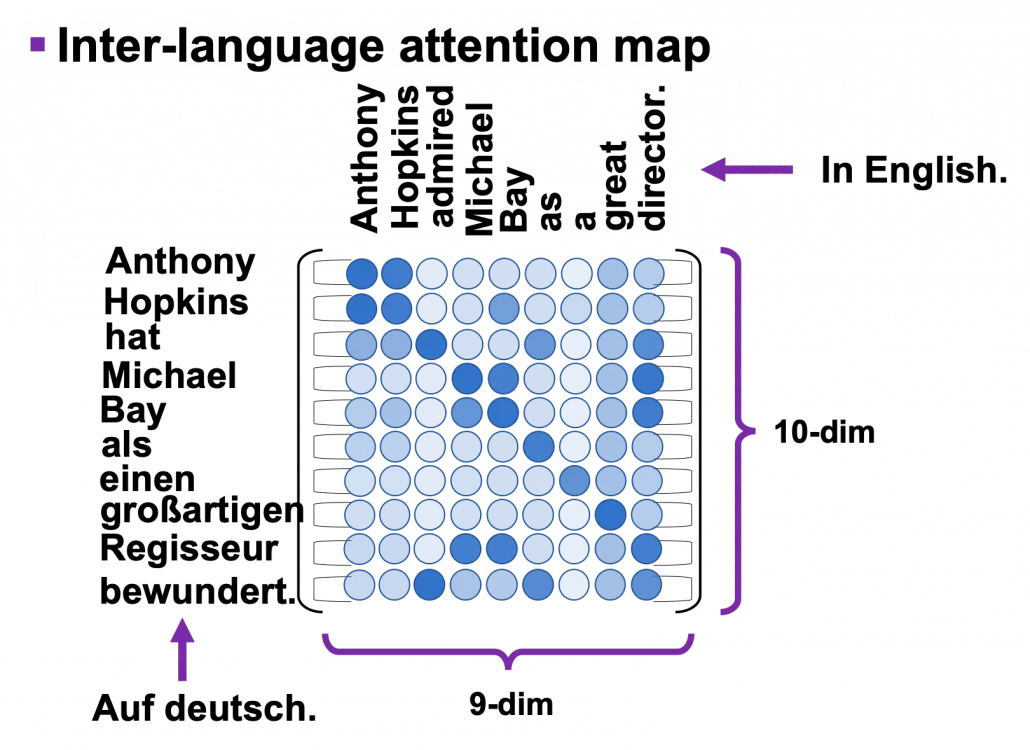
이 그림이 앞에서의 설명을 한눈에 파악할 수 있게 해준다.
“input tokens와 output tokens에 대한 정보들의 관계값들을 가진 결과가 나온다!”
<전체 decoder 모듈의 흐름>
1.
Decoder input token의 embedding 수행
2.
Sinusoidal positional encoding
3.
encoder input으로부터 self padding mask 생성
4.
decoder input으로부터 Look ahead mask생성
5.
stack된 decoder 레이어들 거쳐 마지막 decoder layer의 ouput이 최종 decoder output이 된다.
self padding mask
3번과정은 masked multi-head attention을 말한다. 이는 어려운 개념이 아니라 가장 긴 문장에 맞도록 입력 행렬의 크기를 고정시켜두고, 입력 문장의 최대길이가 41이라면 문장 길이가 41보다 짧아도 41만큼의 길이를 채워주는 것이다. 예를 들어 한 토큰에 대한 임베딩 차원크기가 64이고 최대 문장길이가 41이라면 항상 (64, 41)크기의 텐서가 생성되는 것이다. 그래서 실제로 위의 예시의 경우에도 (10, 9)크기의 attention map이 아니고 (41, 41) 크기의 attention map을 사용하게 된다.
padding은 0값으로 채우게 되며, 아래 그림의 검은 점들이 0인 요소들을 뜻한다.
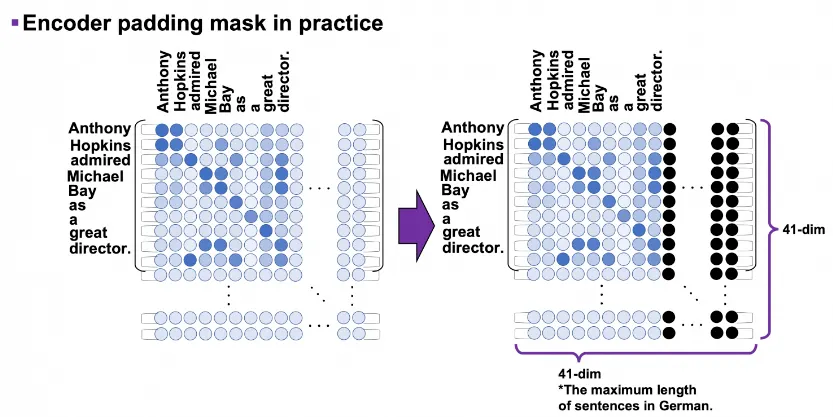
def create_padding_mask(seq):
seq = torch.equal(seq, 0).type(torch.float32)
return torch.reshape(seq, (seq.shape[0], 1, 1, seq.shape[1])
# (batch_size, 1, 1, key의 문장 길이)
Python
복사
※ decoder input의 경우에도 동일하게 문장길이 초과하는 위치를 모두 0으로 채워 padding 해준다.
※ encoder input과 decoder input 그러니까 input 문장과 target 문장의 최대 길이는 다를 수 있다.
look-ahead mask
4번과정의 look-ahead mask는 target의 경우 각 토큰을 이전 토큰과만 비교할 수 있도록 마스킹 해주는 것입니다. 그림으로 나타내면 다음과 같습니다.
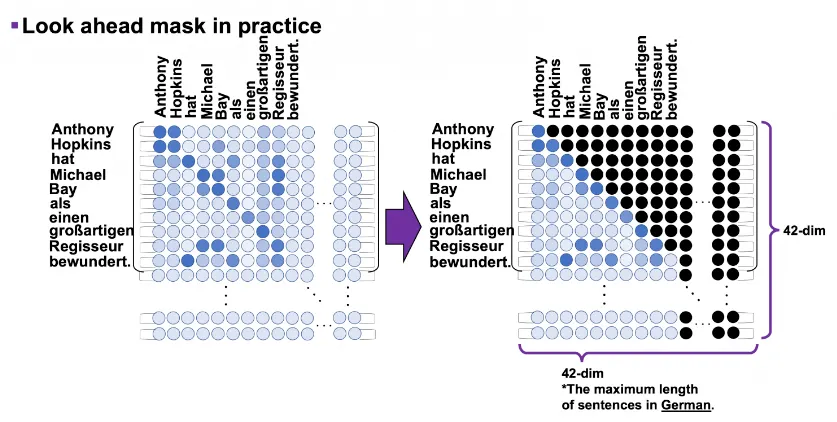
그림에 나온 것처럼 ‘hat’은 “anthony”, “Hopkins” 까지는 비교할 수 있지만 그 뒤에 나오는 단어들과는 비교할 수 없다.
코드로는 다음과 같다.
def create_look_ahead_mask(size):
batch_size, seq_len = target.size()
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_len, seq_len, device=target.device), diagonal=1)).bool()
return nopeak_mask
Python
복사
torch.triu
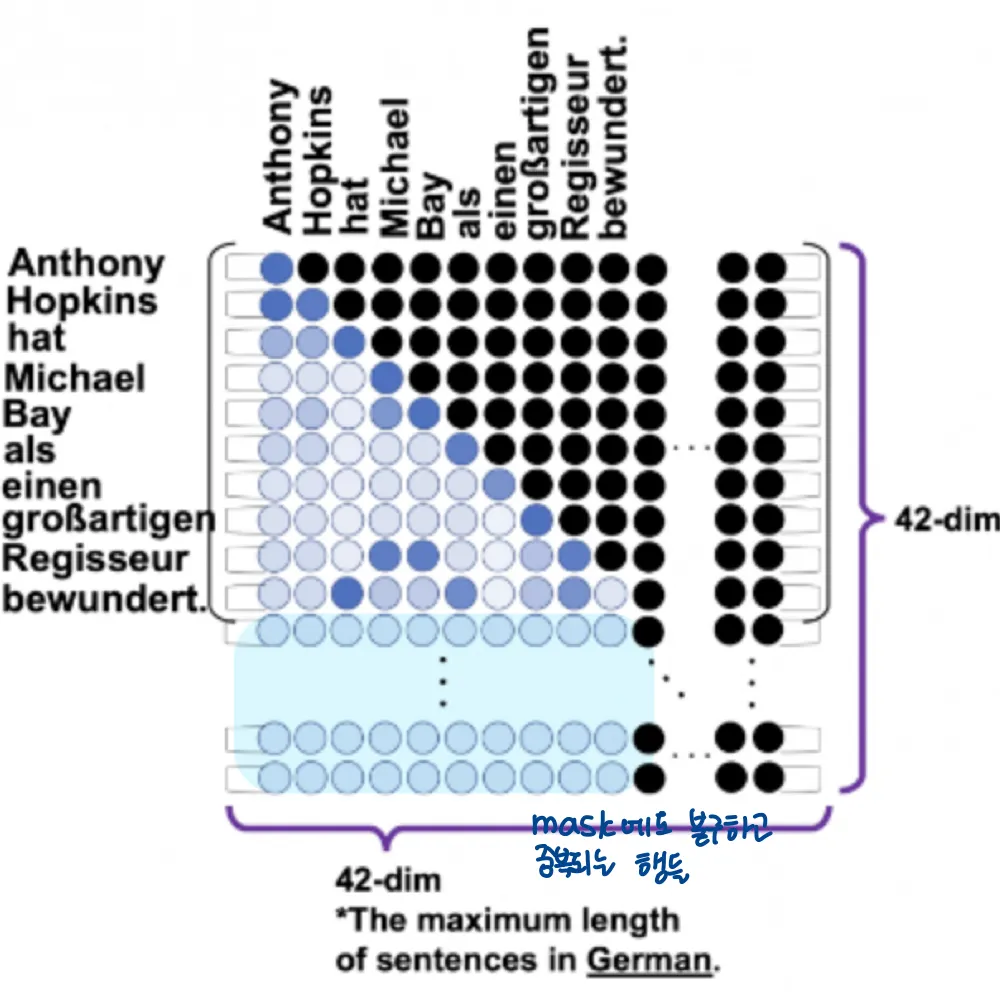
이러한 mask들에도 불구하고 그림의 파란 부분처럼 여전히 존재하는 중복되는 행들이 inference에서 문제를 발생시키지 않을까 생각이 된다
⇒ 그러나 decoding과정에서는 attention map의 행방향으로 최종출력을 decoding하고, [END]토큰을 디코딩하고 나면 디코딩이 중지되기 때문에 중복된 행은 문제가 되지않는다.
decoder에서 앞선 단어로만 decoding하도록 하기
transformer 논문에서는 decoder layer의 self attention sublayer를 수정해 후속 위치에 attention하지 않도록 하였다고 한다.
1.
출력 임베딩이 한 위치 offset된다
2.
look ahead masking을 통해 위치 에 대한 예측이 보다 작은 위치에서의 출력에만 의존하도록 한다
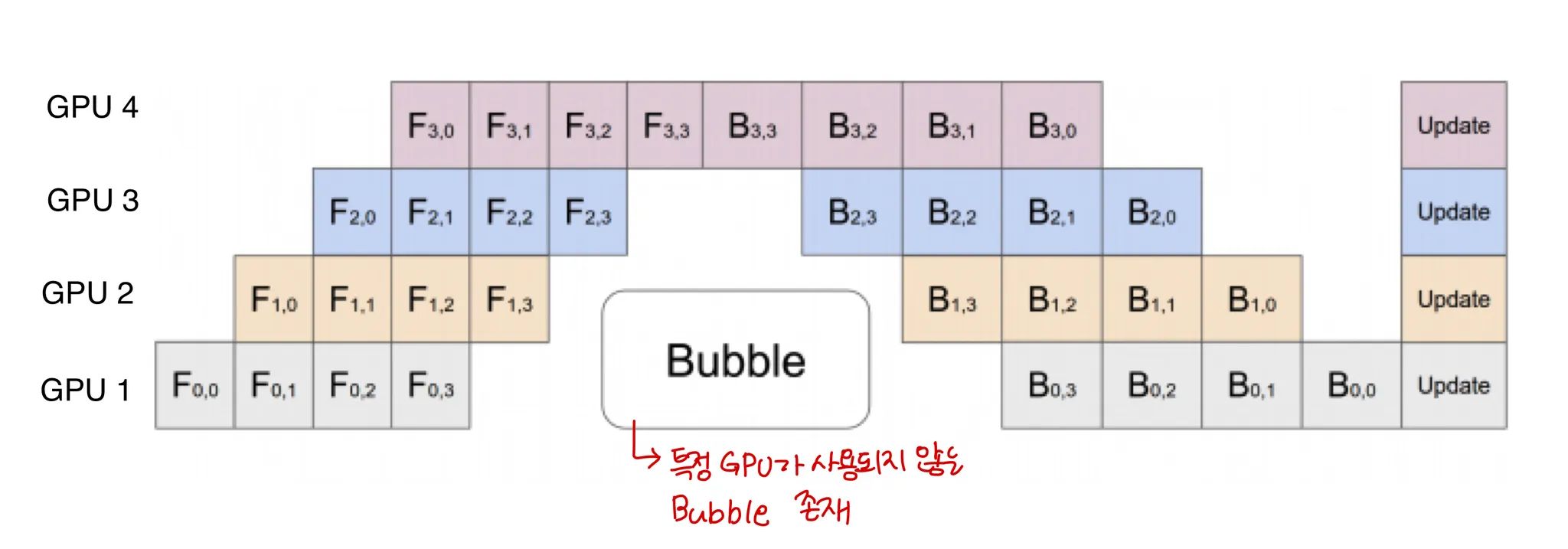
병렬연산

Pipe class 는 nn.Sequential module을 동시에 pipline parallelism으로 train할 수 있게 wrap한다. 모듈이 많은 메모리를 필요로하거나 single GPU에 적합하지 않을 때 유용하다.
ntokens = len(vocab) # 단어 사전(어휘집)의 크기
emsize = 4096 # 임베딩 차원
nhid = 4096 # nn.TransformerEncoder 에서 순전파(feedforward) 신경망 모델의 차원
nlayers = 12 # nn.TransformerEncoder 내부의 nn.TransformerEncoderLayer 개수
nhead = 16 # multiheadattention 모델의 헤드 개수
dropout = 0.2 # dropout 값
from torch.distributed import rpc
tmpfile = tempfile.NamedTemporaryFile()
rpc.init_rpc(
name="worker",
rank=0,
world_size=1,
rpc_backend_options=rpc.TensorPipeRpcBackendOptions(
init_method="file://{}".format(tmpfile.name),
# _transports와 _channels를 지정하는 것이 해결 방법이며
# PyTorch 버전 >= 1.8.1 에서는 _transports와 _channels를
# 지정하지 않아도 됩니다.
_transports=["ibv", "uv"],
_channels=["cuda_ipc", "cuda_basic"],
)
)
num_gpus = 2
partition_len = ((nlayers - 1) // num_gpus) + 1
# 처음에 인코더를 추가합니다.
tmp_list = [Encoder(ntokens, emsize, dropout).cuda(0)]
module_list = []
# 필요한 모든 트랜스포머 블록들을 추가합니다.
for i in range(nlayers):
transformer_block = TransformerEncoderLayer(emsize, nhead, nhid, dropout)
if i != 0 and i % (partition_len) == 0:
# partition_len만큼의 트랜스포머 블록들을 nn.Sequential 객체로 module_list에 추가
module_list.append(nn.Sequential(*tmp_list))
tmp_list = []
device = i // (partition_len)
tmp_list.append(transformer_block.to(device))
# 마지막에 디코더를 추가합니다.
tmp_list.append(Decoder(ntokens, emsize).cuda(num_gpus - 1))
module_list.append(nn.Sequential(*tmp_list))
# module_list는 nn.Sequential로 묶인 트랜스포머 블록들과 Decoder를 가지고 있음.
from torch.distributed.pipeline.sync import Pipe
# 파이프라인을 빌드합니다.
chunks = 8
model = Pipe(torch.nn.Sequential(*module_list), chunks = chunks)
def get_total_params(module: torch.nn.Module):
total_params = 0
for param in module.parameters():
total_params += param.numel()
return total_params
print ('Total parameters in model: {:,}'.format(get_total_params(model)))
Python
복사
Pipe 객체를 생성할 때 파라미터로 들어가는 chunks는 micro-batch의 개수이다.(default 1)
micro batch?
pytorch 튜토리얼에 따르면 병렬처리 하지 않았을 때 (Pipeline parallelism을 사용하지 않았을 때) training 과정을 그림으로 나타내면 다음과 같다.
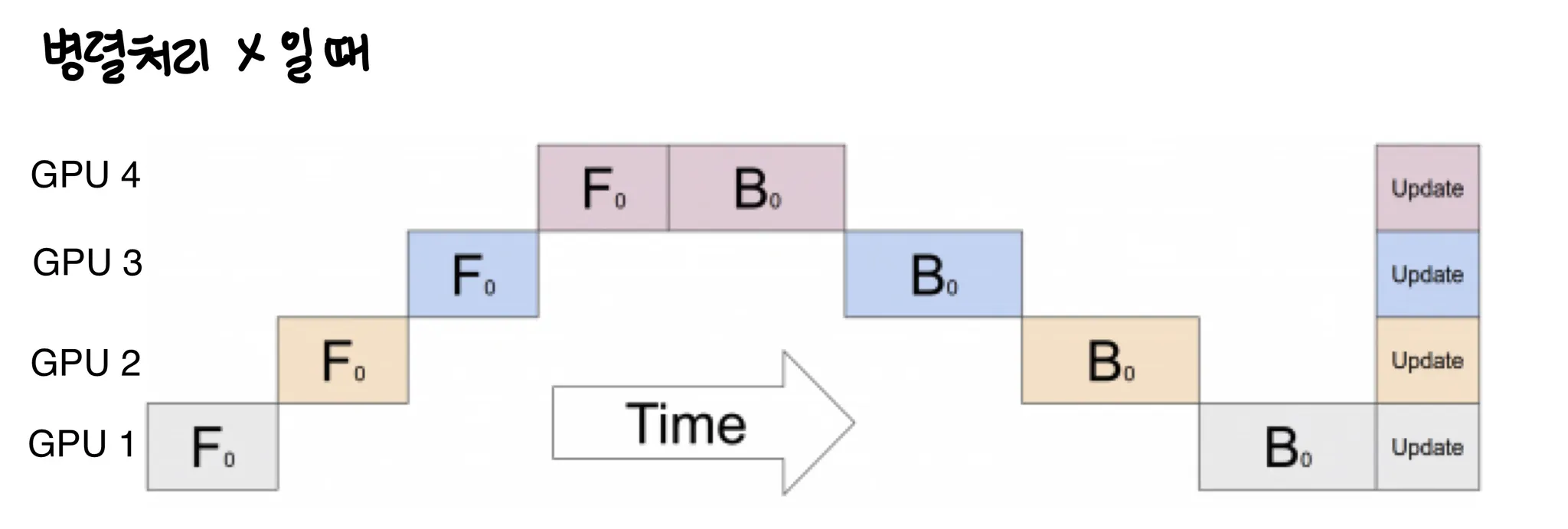
한 time에 하나의 GPU만 사용하고 있는 것을 볼 수 있다.
pipeline parallelism을 사용하면 다음과 같이 input batch가 여러개의 micro batches로 나뉘고 이 micro batches의 실행을 GPU에 파이프라인화 한다.