Alexnet, VGG→ skip connection, shortcut 사용 x = plain network
plain network가 깊어지면 gradient vanishing and gradient exploding ⇒ gradient descent과정에서의 미분에서 chain rule 에 의해 작은 기울기가 여러번 곱해지면 vanishing, 큰 기울기가 여러번 곱해지면 exploding ⇒ 이러한 현상때문에 깊이가 깊어질수록 성능 저하 현상 (degradation)
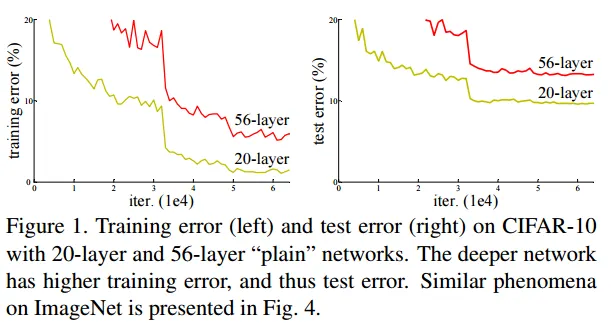
이를 해결하기 위해 skip connection, shortcut connection 적용
Skip connection, Shortcut Connection
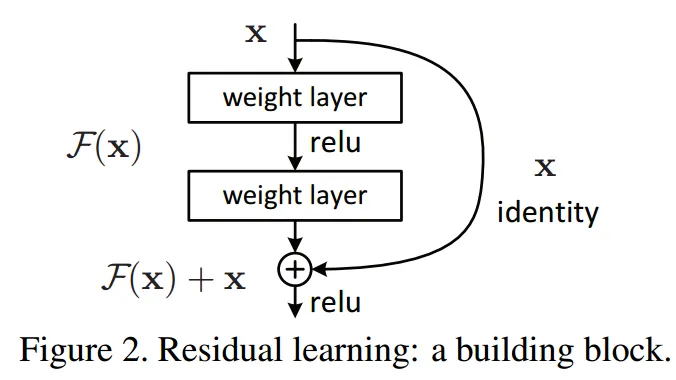
plain network : H(x) = x가 되도록 학습이 목표
ResNet : skip connection으로 출력값에 x가 더해져 H(x) = F(x) + x가 되도록 학습 == F(x) 가 0이 되도록 학습 == H(x) = 0+x가 되도록 학습 ⇒ 최적화가 쉬워진다 왜? 미분했을 때 더해진 x가 1이 돼 기울기 소실 문제가 해결되기 때문
는 보통 2~3 레이어지만 자유롭게 설정 가능하다. 그러나 1개의 레이어로 이뤄져있을 경우 와 같이 선형이 되므로 얻을 수 있는 장점이 없다
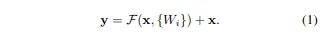
skip connection과 shortcut connection은 결국 더해주는 것(element-wise addition)이기 때문에 더해지는 값 x와 출력값의 차원() 의 차원(채널수) 가 같아야 합니다.
또한 이를 통해 activation function외에 또 하나의 nonlinearity를 적용하게 된다.
입력차원(x의 차원) < 출력차원의 경우 사용하는 2가지
두 옵션 모두 두개의 사이즈에서 shortcut이 진행될 때 stride 2로 실행된다.
1.
shortcut의 경우 증가한 차원에 대해 추가적인 zero padding 적용 ( Bottle neck 구조에서 사용)
2.
차원 증가시에만 projection shortcut 사용 다른 경우의 shortcut은 identity : 추가 파라미터 ()필요 (1x1conv연산으로 실행되기 때문) 1x1 conv → spatial 정보는 최대한 건드리지 않으면서 채널만 F(x)와 맞춰줌
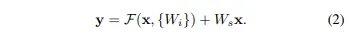
Bottleneck Design
NN의 복잡도 감소→학습시간감소 를 위해 사용된다
ResNet 50 이상에서 사용
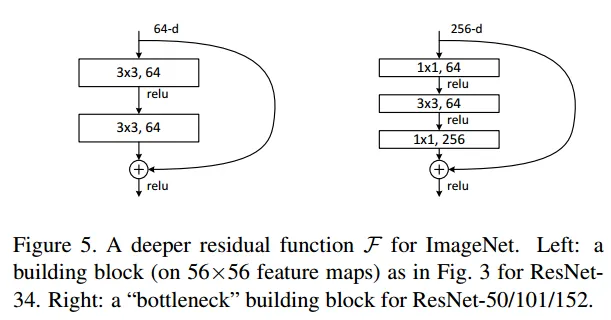
마치 bottleneck처럼 레이어의 앞과뒤에 1x1 conv layer가 추가된 모양이다.
이는 NIN과 GoogleNet에서 제안된 방법으로, 1x1conv연산은 채널수를 조절하고 채널간 정보를 고려해 3x3필터는 지역정보에만 집중할 수 있도록 일종의 역할분담의 역할입니다.
+ 파라미터 수를 줄이는 역할. 더 깊은 구조에도 파라미터수가 더 적습니다.
또한, 1x1 conv는 곱연산으로, 영상처리적 측면에서 대비를 높이는 역할이 있고, 그는 고주파 성분을 강조시키는 것과 같아 1x1로 픽셀단위로 중요한 성분을 강조시킨 후 3x3으로 지역적 특성(공간적 특성)을 강조함으로써 원본의 정보를 최대한 보존시키고자 한 Residual block의 효과를 더 강화시키는 역할을 한다고 볼 수도 있습니다.
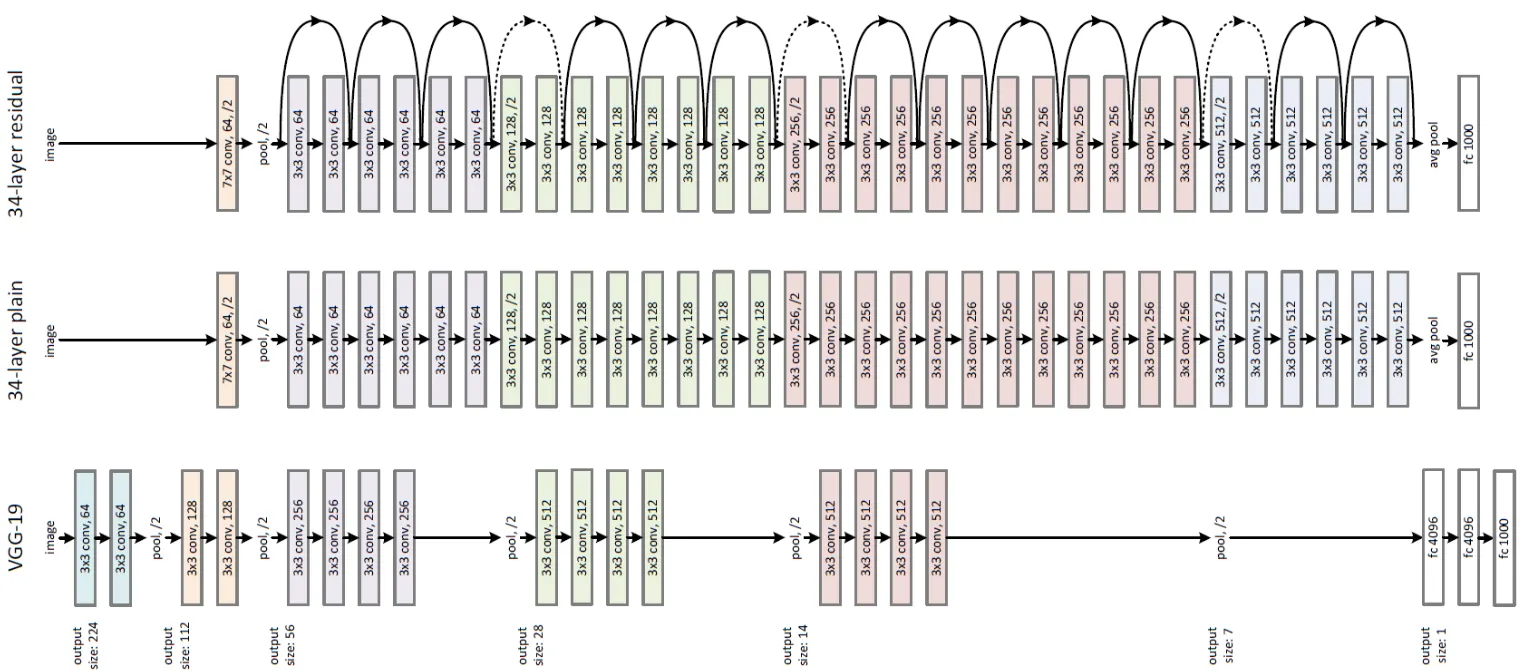
bottleneck design으로 연산량을 감소시켜 34-layer는 50-layer ResNet이 되고, bottleneck design을 지닌 더 깊은 신경망이 있습니다. ResNet-101과 ResNet-152 입니다. 전체적인 구조는 아래와 같습니다.
첫 conv 이후 maxpool 한 이유?
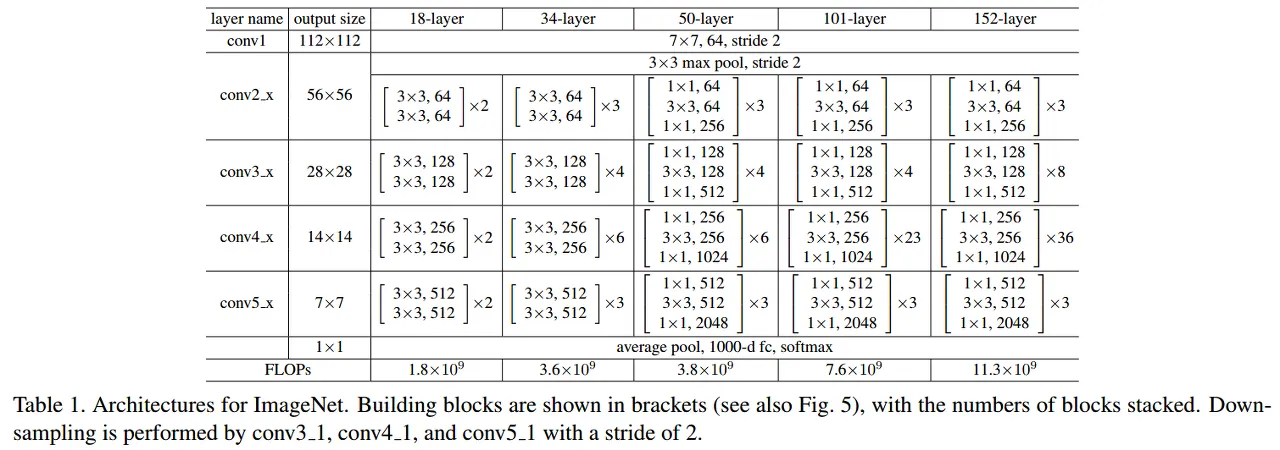
VGG-16 보다 ResNet-152가 더 적은 연산량을 갖고 있습니다.
ResNet 50 | 34-layer의 각 2-layer block을 이 3-layer bottleneck block으로 대체, 증가한 차원에 대해서는 option B사용 |
ResNet 101 | 3-layer block을 더 사용해 구축 - 23개 |
ResNet 152 | 3-layer block을 더 사용해 구축 - 36개 |
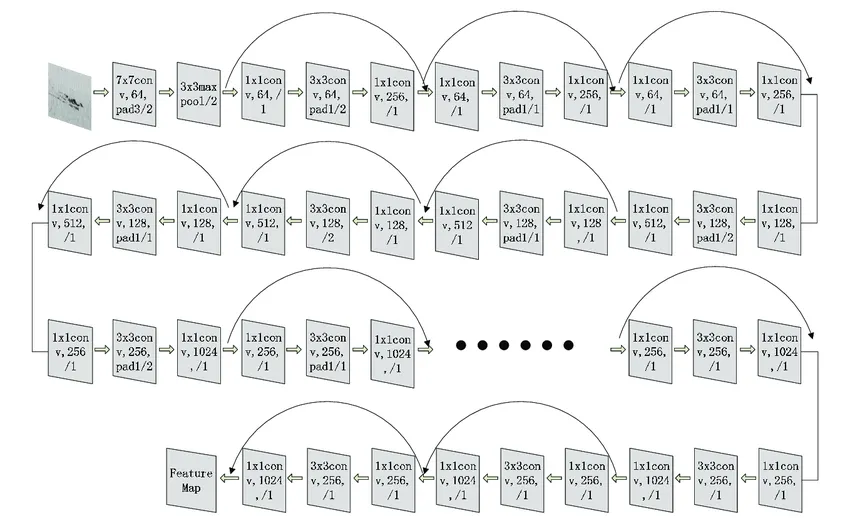
resnet 101
Implementation
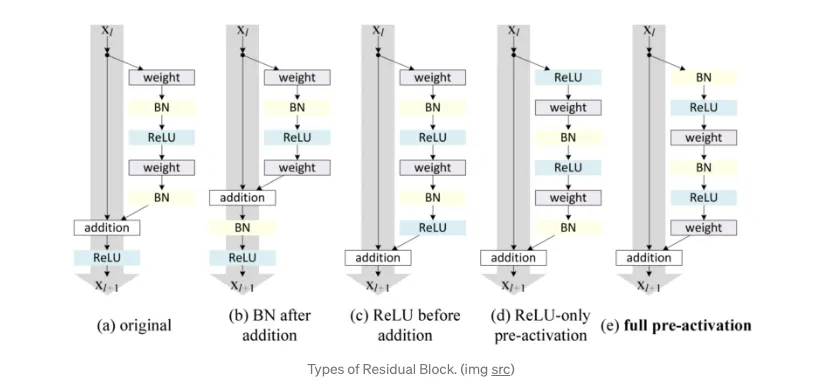
activation function 적용 전에 conv layer 바로 다음 Batch Normalization적용
•
conv - BN - activation(ReLU)의 순서에는 당연하지만 이유가 있습니다. BN은 간단히 말해 각 레이어로 들어가는 입력의 분포를 맞춰주는 것인데, ReLU로 0이하의 값을 잘라버린 후 BN을 해버리면 중요할 수도 있는 정보들이 사라진 상태로 분포를 맞춰주는 것이므로 의미가 없어질 수 있습니다(효과가 감소)
ReLU 전에 BN으로 분포를 맞춰주면 가운데 있는 값이 보통 중요한 값이므로, 이후에 ReLU를 하면 중요한 값이 소실될 가능성이 줄어듭니다. 그러므로 실험적으로도 BN-ReLU가 더 성능이 좋습니다
13논문처럼 weight initialize(코드 참고)
모든 plain/residual nets를 처음부터 학습
SGD사용(mini batch 256, learning rate는 0.1부터 시작해 plateu 에러 발생시 10으로 나눠짐)
weight decay : 0.0001, momentum : 0.9
최대 iteration만큼 학습
dropout 사용 x (사실 마지막 분류기를 제외하고 FC레이어 자체가 없기 때문에 필요자체가 없습니다 / 또한 ResNet의 특성상 레이어를 거쳐도 원본의 특성이 잘 유지되기 때문에 FC가 필요없습니다)
Plateau 현상이란, Loss function에 평지(Plateau)가 생겨 기울기가 0에 가까워져 loss가 업데이트 되지 않는 현상을 말합니다. 이 경우는 local minimum에 비해 일어날 확률이 높습니다.
성능비교
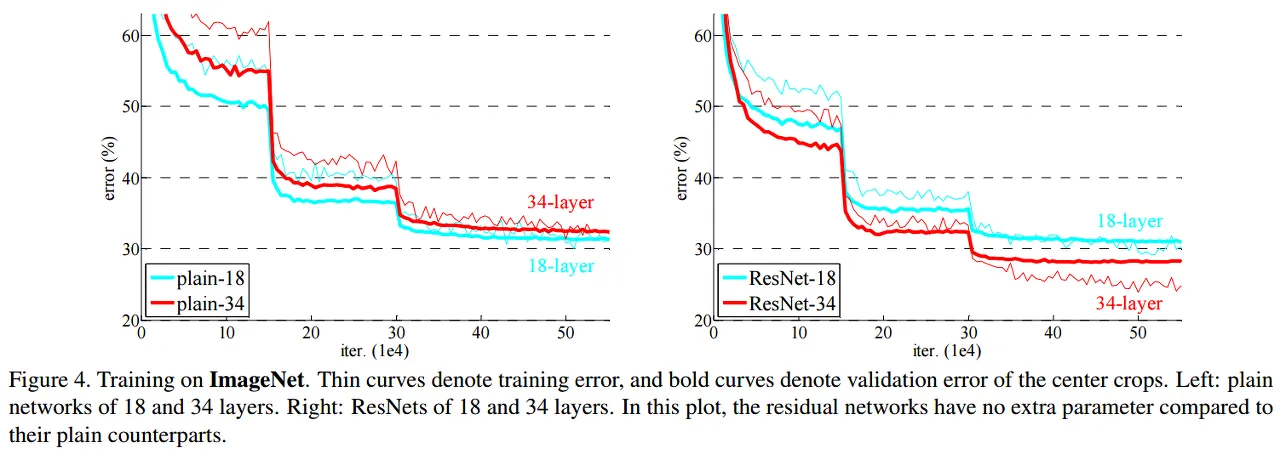
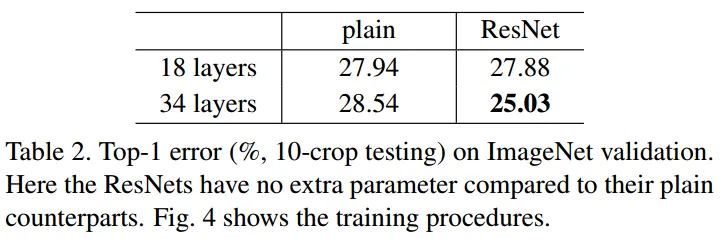
plain network : 18-layer의 성능 > 34-layer (기울기 소실 문제 때문)
ResNet 34-layer의 성능 > 8-layer (기울기 소실 문제가 skip connection에 의해 해결)
18-layer plain network와 18-layer ResNet network에는 차이점 X (깊지 않은 신경망에서는 기울기 소실 문제가 나타나지 않기 때문)