
외부정렬
입력 크기가 매우 커서 읽고 쓰는 시간이 오래 걸리는 보조 기억 장치(디스크, 테이프 등)에 입력을 저장할 수 밖에 없는 상태에서 수행되는 정렬
주 기억 장치의 용량 만큼 보조기억장치에서 데이터를 읽어 정렬한다
보조기억장치의 특성에 따라서는 데이터에 순차적 접근만 가능하다
보조기억장치와 주기억장치 사이에 데이터 이동 횟수는 최소화를 해줘야 한다.
C.f. 보조기억장치는 접근속도가 느리고, 접근이 제한적이다.
레코드 접근시간 >> 레코드 비교시간
Ex)
•
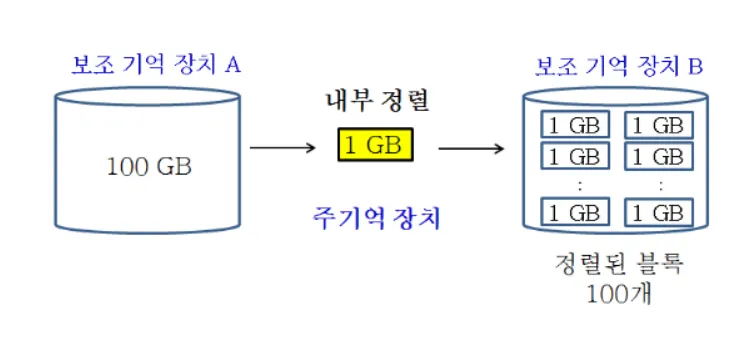
컴퓨터의 주기억 장치의 용량이 1GB이고, 정렬할 입력의 크기가 100GB
⇒ 내부정렬 알고리즘으로 정렬할 수 없다.
•
외부 정렬은 입력을 분할해서 주기억 장치에서 수용할 만큼의 데이터에 대해서만 내부정렬을 수행 → 그 결과를 보조 기억 장치에 저장
•
100GB의 데이터를 1GB만큼씩 주기억 장치로 읽어 들이고, 퀵 정렬과 같은 내부정렬 알고리즘을 이용하여 정렬한 후, 다른 보조 기억 장치에 저장한다.
•
이것을 반복하면 원래의 입력 100GB가 100개씩 정렬된 블록으로 분할되어 보조 기억 장치에 저장된다.
•
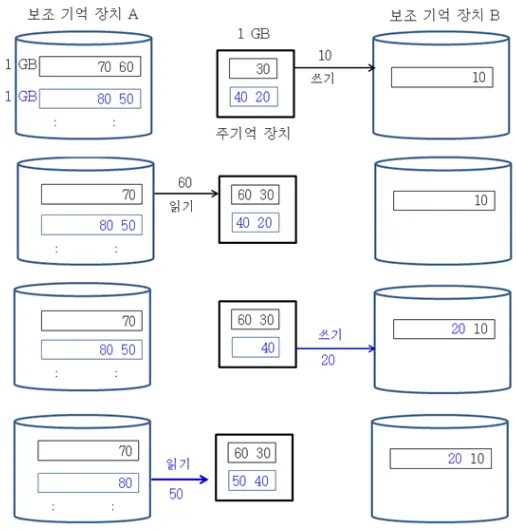
그 다음 정렬된 블록들을 하나의 정렬된 거대학 블록으로 만들어야하기에 합병을 반복 수행한다(merge)
= 블록들을 부분적으로 주기억장치에 읽어들여 합병을 수행하고 부분적으로 보조 기억 장치에 쓰는 과정
Ex) 1GB 블록 2개가 2GB 블록 한개로 합병될 때
•
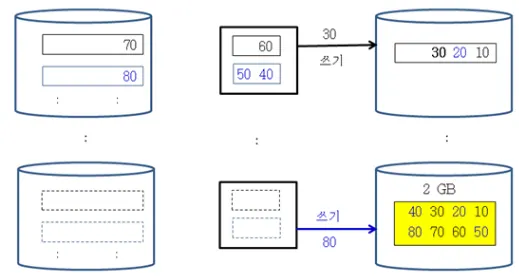
나머지 98개 블록 대해 위 과정 49회 반복하면 2GB블록 50개가 만들어짐
•
이후에는 또 2GB 블록 두개씩 merge하는 과정 25회
•
→반복....→ 블록크기가 2배씩 커지면서 블록수는 1/2이 되어 마지막엔 100GB블록 하나가 된다.
런(run)
하나의 파일을 여러 개의 서브파일(subfile)로 나눠 내부 정렬 기법을 사용해 정렬시킨 파일
ex) 2000개의 레코드를 가진 파일을 정렬하는 문제에서 주기억장치의 용량이 1000개의 레코드까지만 허용한다면, 2개의 런이 사용된다.
외부정렬 알고리즘은 합병정렬 알고리즘이 기본이다
1.
정렬단계( sort phase )
정렬할 파일의 레코드들을 지정된 길이의 서브파일로 분할하고 이를 정렬해 run을 만든 후 입력 파일로 분배
2.
합병단계( merge phase )
정렬된 run들을 합병해 큰 run으로 만들고, 이것들을 다시 입력파일로 재분배해 합병하는 방식→ 모든 레코드들이 하나의 런에 포함되도록 만듬
균형적 다방향 합병정렬
양방향 합병정렬 ( Two-way Merge Sort )
입력 : 입력 데이터가 저장된 장치
출력 : 정렬된 데이터가 저장될 장치
: 미 정렬된 데이터
: 정렬된 run

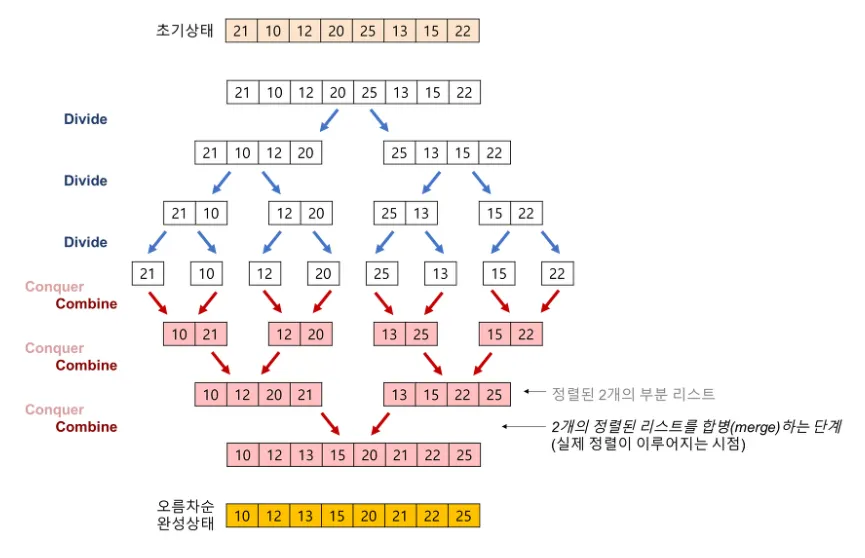
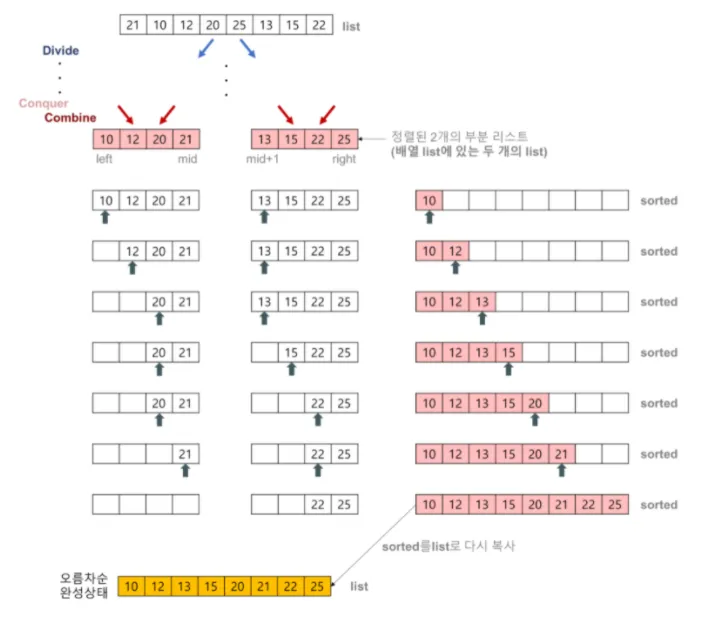
Step1. 분할(Divide): 배열을 반으로 분할한다. 분할한 배열의 원소는 각각 n/2이다.
Step2. 정복(Conquer): 분할한 배열을 각각 따로 정렬한다. 분할한 배열에 원소의 크기가 2개 이상이면 순환 호출을 이용하여 다시 분할 정복 알고리즘을 적용한다.
Step3. 결합(Combine): 정렬된 부분 배열들을 하나의 배열로 합병하여 정렬한다.
다방향 합병정렬( M-way Merge Sort )
2-way 합병 정렬을 일반화 한것으로 분할 단계에서 배열을 2개가 아닌 k개의 부분 배열로 분할하여 정렬을 진행하는 방식
합병 단계에서 k개의 부분배열을 하나의 배열로 합병하기 위해서는
첫번째 부분배열과 두번째 부분배열을 합병, 합병한 배열과 세번째 부분배열을 합병, . . . , 합병한 배열과 k번째 부분배열을 합병
하는 과정을 거쳐야 한다.
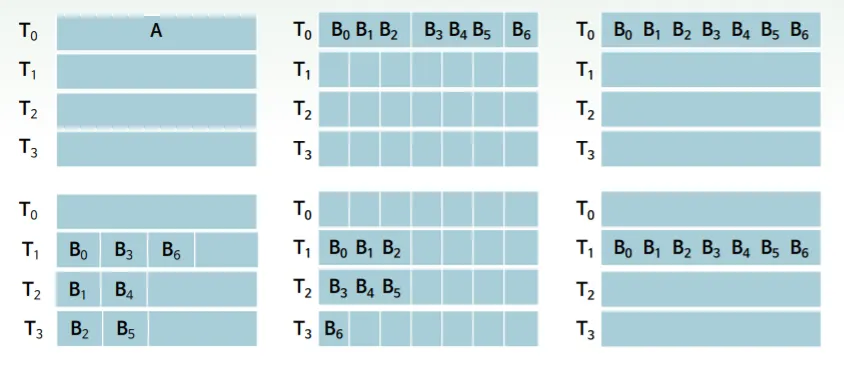
균형적 다방향 합병정렬( Balanced Multiway Merge Sort )
정렬할 파일의 레코드 n개
내부 정렬 가능 블록 크기는 b
4개의 테이프 장치 이용 →
1.
에 정렬할 레코드들이 있다
2.
의 레코드들을 b개의 레코드로 이뤄진 블록으로 나눈다
3.
이 블록들을 주기억장치에 읽어들여 내부정렬 알고리즘으로 정렬하고
4.
정렬된 블록들 을 와 에 번갈아가며 저장한다.
5.
홀수 번호 가진 블록들은 T_3, 짝수번호 가진 블록들은 에 저장된다
** n이 b로 나눠지지 않으면 마지막 블록인 크기는 b보다 작다
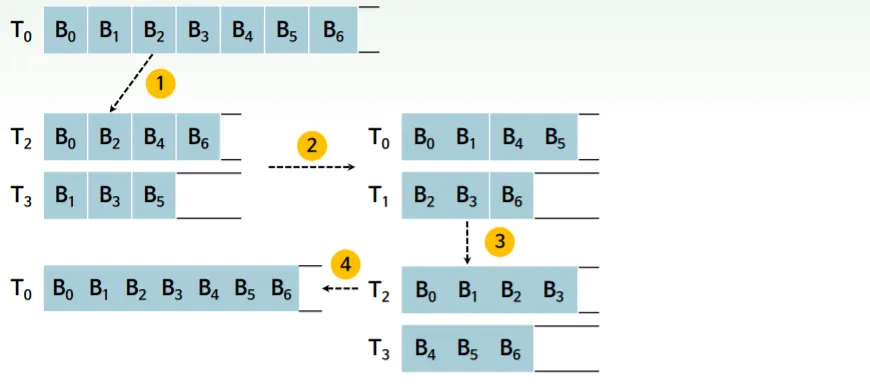
블록들이 주기억장치와 여러 테이프를 오고가면서 두개씩 짝지어 merge과정이 순환적으로 반복돼 블록 수가 줄고 블록 크기가 커지게 됨
여러 테이프에 분산되어있는 블록을 머지 → 다방향 머지
외부정렬의 성능을 개선
외부정렬 = 정렬단계 + 합병단계
1.
런 하나의 크기를 가능한 크게 만들어 전체 합병 횟수를 줄이기
2.
합병 전 각 장치에 저장할 런 개수를 조정해 합병 과정에서 만들어지는 불필요한 이동 및 복사 횟수 줄이기
1번 전략
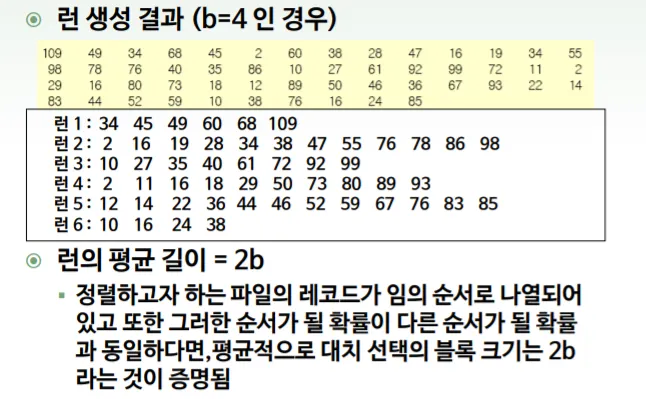
런 하나의 크기를 가능한 크게 만들어 전체 합병 횟수를 줄이기
정렬 단계에서의 대치선택으로 가능
대치선택
초기 정렬 블록을 크게 해 테이프 이동 횟수를 줄이고자 하는 목적
정렬의 첫번재 단계에서 만들어지는 정렬이 크면 클수록 두번째 단계에서 합병하는 횟수가 줄어들기 때문
⇒ 우선순위 큐 사용
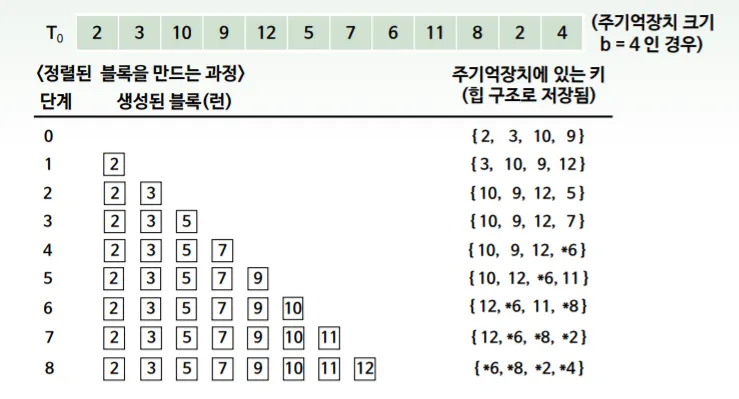
Q. 주 기억장치에서 내부 정렬 가능한 블록의 최대 크기가 b일 때 b보다 큰 사이즈의 run을 만들어낼 수는 없을까?
⇒ 런을 만드는 과정에서 주기억장치에 항상 b개의 레코드를 상주시키고 이를 최솟값 힙 구조로 운영
⇒ 마지막으로 출력된 키값보다 큰 키 값을 갖는 레코드가 출연하면 이를 별도로 마크(*, frozen)시키고, 마크된 레코드 키값은 로 취급
⇒ 주기억장치 내 모든 레코드가 마크된 경우 새로운 런 생성을 시작
<대치선택을 통한 런 생성>
1.
입력 파일에서 버퍼로 b개 레코드 읽기
2.
버퍼를 최솟값 힙으로 재구성하고, 키 값이 가장 작은 레코드를
선택해 출력한 뒤 버퍼에서 삭제
3.
입력 파일에서 다음 레코드를 읽어 버퍼에 포함시킨 뒤 출력된
레코드와 비교(모든 레코드가 동결되어 다음 레코드를 읽어 들일
공간이 없다면 단계 4로 진행)
• 삭제한 레코드(출력레코드) < 새로 삽입되는 레코드(입력레코드)이면 2번을 반복
• 입력 레코드의 키 값 < 출력된 레코드의 키 값 이면 레코드에 “동결(frozen)” 마크 표시
• 동결된 레코드는 단계 2의 선택에서 제외
• 동결되지 않은 레코드는 단계 2로 돌아간다.
4.
동결된 레코드들을 모두 동결 해제하고, 단계 2로 돌아가 새로운
런 생성
2번 전략
합병 전 각 장치에 저장할 런 개수를 조정해 합병 과정에서 만들어지는 불필요한 이동 및 복사 횟수 줄이기
합병단계에서의 다단계 합병정렬(Polyphase Merge Sort)로 가능
