올해 CVPR에서 google research에서 발표한 논문입니다.
대학원 수업 발표도 해야해서 related work까지 조금 길게 정리했습니다. 하핳
Abstract
semantic segmentation 라벨을 생성하는데에는 시간과 돈이 많이 필요하다.
따라서 semantic segmentation 효율을 높이기 위해 denoising autoencoder를 다시 들여다보면서 Unet을 pretrain하기 위한 denoising objective의 사용을 연구하였다.
semantic segmentation 모델로 Transformer-based Unet을 사용하였고, 이 모델은 denoising autoencoder로써 pretrain된 후 적은 수의 labeled examples로 semantic segmentation을 위해 finetuning되었다.
⇒ 적은 수의 데이터로 효율적으로 성능을 내기 위한 논문임.
denoising으로 pretrain하고 finetuning한 성능이 random initialization으로 semantic segmentation training한 성능을 능가하였고, ImageNet-21k로 pretrain후 finetuning한 성능도 능가하였다.
핵심은 denoising pretraining이 decoder를 pretrain할 수 있는 능력이다.
⇒ 보통 autoencoder는 pretrain후 encoder를 활용하기 위한 목적으로 쓰임
이렇게 제안하는 pretraining방식을 Decoder Denoising Pretraining(DDeP)라고 정의하였다.
DDeP의 순서
1.
encoder를 supervised learning으로 i
DDeP는 label-efficient semantic segmentation에서 SOTA 성능을 달성했다.
실험 datasets : CityScapes, Pascal Context, ADE20K
1. Introduction
pixel-level label 생성에 대한 어려움
semantic segmentation / depth estimation같은 dense pixel-level prediction이 필요한 computer vision분야들이 있다.
dense pixel-level prediction label ( ground truth annotations )의 문제점
1.
비싸다
2.
시간이 많이 든다
3.
실수가 일어나기 쉽다
이러한 문제로 위의 tasks들에 대해 정확한 supervised model을 구축하기가 어렵다.
기존에 사용된 pretraining 방식의 한계
SOTA기술들은 model backbone을(e.g. encoder) supervised classifier 혹은 self-supervised feature extractor로 pretrain하는 것에 의존하곤 한다.
그러나 ResNet같은 대부분의 backbone architectures는 점진적으로 feature map해상도를 줄여나가기 때문에 pixel-level prediction을 수행하려면 decoder에서 여러개의 upsampling layer들이 필요하고 추가적 파라미터가 발생한다.
그러나 이런 추가적 파라미터들이 존재하는 디코더에 대해 대부분의 SOTA semantic segmentation models는 파라미터들을 random하게 초기화한다.

본 논문에서 pretraining에 대한 관점과 computer vision 분야에서의 연구 필요성
pretraining semantic segmentation에 대한 새로운 시작점은 large unlabelled data에 대해 학습해 data distribution을 배우도록해 generative modeling을 수행하는 것이다.
⇒ 예를 들면 denoising의 경우 label이 필요없고 오직 원본 이미지만이 필요하다. 그래서 larget dataset을 생성하기 쉽고, denoising task는 noise가 존재하는 input으로부터 복원된 새로운 이미지를 생성하는 task라고 볼 수 있기 때문에 generative modeling이라 정의할 수 있다.
Generative modeling : label 필요  , pixel-level에서 image의 representation을 학습 → dense prediction tasks에 대해 유망한 representation learning method
, pixel-level에서 image의 representation을 학습 → dense prediction tasks에 대해 유망한 representation learning method
, pixel-level에서 image의 representation을 학습 → dense prediction tasks에 대해 유망한 representation learning methodex) NLP 분야 → BERT같은 경우 mask된 token 예측하는 식의 pretrain → 성공적이었다.
Computer vision 분야 → 특히 pixel prediction tasks에서의 generative pretraining 방식이
supervised방식보다 뒤쳐짐.
왜 denoising pretraining인가
diffusion models & score-based generative models → image와 audio synthesis에 새로운 접근법으로 등장. GAN보다 더 좋은 성능을 냈다.
Denoising Diffusion Probabilistic Models ( DDPMs )의 경우 일련의 반복적인 denoising steps를 통해 gaussian noise를 target distribution으로 변환하는 법을 학습해 복잡한 empirical distribution을 근사화한다.
DDPMs : Unet같은 encoer-decoder 구조로, noise로 손상된 input에서 깨끗한 이미지를 반복적으로 복구한다. 따라서 구조적으로 dense prediction models와 구조적으로 유사해 semantic segmentation과 같은 tasks에 적합한 후보가 된다 ⇒ pretraining으로 denoising을 선택한 이유
DeP, DDeP (proposed)
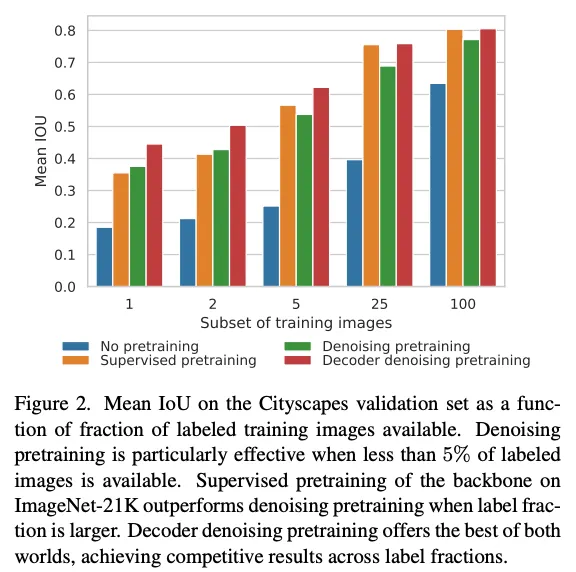
noise의 수준을 잘 선택해서 Denoising pretraining(DeP)을 수행하면 few-shot semantic segmentation에서 경쟁력 있는 representation을 산출하게되고, 이는 random initialization이나 ImageNet-21k pretraining의 성능을 능가한다는 것을 발견했다.
그러나 주의할 점은 semantic segmentation을 위한 labeled data가 증가할수록 ImageNet-21k pretraining의 성능이 점점 DeP를 능가한다.


denoise를 위한 dataset 생성을 위해 i.i.d gaussian noise를 추가했다.
Fig2에서 보이듯 Denoising pretraining(DeP)은 label 이 적은 상황에서 경쟁력 있다. 그러나 label이 많아지면 supervised pretraining보다 성능이 낮아지므로 이를 해결하기 위해 decoder denoisinig pretraining(DDeP)을 제안한다. supervised pretraining과 denoising pretraining을 합친 것으로, label이 많은 경우 / 적은 경우 모두에서 좋은 성능을 보인다.
contributions
•
semantic segmentation을 위한 unsupervised Denoising Pretraining(DeP)를 제안. labeled image수가 적을 때 random initialization, ImageNet-21K pretraining 성능 능가
•
semantic segmetation을 위한 decoder denoising pretraining(DDeP)를 제안. supervised pretraining과 denoising pretraining의 장점을 결합.
frozen supervised backbone은 denoising에서 pretrain된 decoder와 결합해 사용된다.
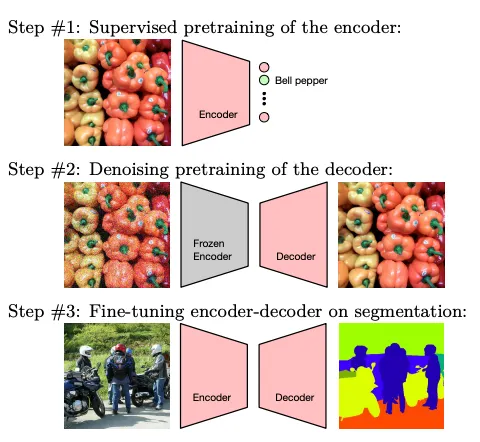
CVPR 버전에는 이 그림이 없고 arxiv 버전에만 있다.
2. Related Work
위에서 말했듯 pixel level labels생성의 어려움 → 적은 labeled data에서의 semantic segmentation 연구가 있어왔음. 대부분의 방법은 semi-supervised learning(SSL)이다.
SSL은 labeled training data에 더해 large unlabled images dataset에 대한 접근을 가정한다.
related work에서는 이와 관련된 내용으로 data augmentation, generative models, self-supervised learning in label-efficient semantic segmentation을 다룬다.
Data augmentation
•
Cutout

•
Cutmix
•
copy-paste augmentation

DDeP에서는 연구에서는 이런 복잡한 방식은 사용하지 않고 horizontal filp, random inception-style crop같은 간단한 augmentation만을 사용했다.
Generative models
GAN
초반 label-efficient semantic segmentation들은 GAN을 사용해 synthetic training data를 생성하고 real semantic segmentation mask와 predicted semantic segmentation masks를 discriminate했다.
DatasetGAN 이 최신 GAN의 구조들이 pixel-level image를 이해하게 해주는 data를 합성하는 것에 효과적이나, 오직 어느정도의 labeled images가 존재해야 가능하다.
Diffusion model
diffusion model은 proof of concept로서 semantic segmentation masks를 반복적으로 개선하는데 사용됐다.
동시에 다른연구 는 labeled data가 적을 때 semantic segmentation을 위해 학습된 diffusion model의 features가 효과적이라는 것을 증명한다.
대조적으로 이 연구에서는 단순한 denoising pretraining으로 완전한 fine-tuning encoder-decoder 구조를 연구했다.
Self-training, consistency regularization
self-training / pseudo-labeling → 가장 오래된 SSL 알고리즘 중 하나이다.
일단 처음엔 supervised model을 사용해 pseudo-label로 unlabelled data에 annotate하고 이후에 pseudo-labeled data와 human-labeled data를 혼합해 개선된 모델을 학습한다.
이 과정이 여러번 반복된다. self-training은 object detection, semantic segmentation을 향상시키기 위해 사용되곤 한다.
이 방식들은 조심스러운 하이퍼파라미터 설정이 필요하며, propagating noise를 피하기 위해 타당한 initial model이 필요하다. self-training과 denoising pretraining을 결합하는 것은 더욱더 결과를 향상시킬 것으로 예상된다.
Self-supervised learning
unlabeled data에서 구성하기 쉬운 predictive pretext tasks를 공식화하며 downstream discriminative tasks에 도움을 준다.
NLP에서 masked language modeling이 좋은 결과를 보여주면서 표준이 되었다. computer vision에서는 image 주변영역을 예측하는 것이나 inpainting작업, image colorization등에서 self-supervised learning방식들이 제안되었다. 최근 methods는 모범적인 discrimination과 contrasive learning이 image classification에서 좋은 영향을 보여줬다.
이 접근들은 object detection과 semantic segmentation에서 backbone을 성공적으로 pretrain하는데 새용되었으나 DDeP와 다른점은 decoder를 random 으로 initialize했다는 것이다.
Self-supervised learning for dense prediction
이전연구에서 제안된 dense contrastvie learning → dense prediction task를 위한 self-supervised pretraining접근이다.
이는 image level features와 대조되게 patch level 과 pixel level features에서 적용된다.
이 연구에서는 가장 오래되고 간단한 self-supervised 방식 중 하나인 denoising autoencoder를 다시 살피며 가장 현대적인 Unet architecture로 noise level을 잘 선택하면 이렇게 학습된 representation이 semantic segmentation으로 잘 transfer된다는 것을 보여준다.
diffusion models
diffusion models는 GAN보다 우수한 quality의 이미지들을 생성하는 새로운 생성모델의 종류이이고 이 모델들은 denoising autoencoder와 denoising score matching이라는 점에서 연결되며 energy-based model이라고 볼 수 있다.
Denoising Diffusion Models(DDPMs)는 최근 conditional generation tasks( e.g. super-resolution, colorization, inpainting )에 적용되어왔으며 image representation을 배우는데 적합하다는 것을 보여준다. 이 연구는 DDPMs의 성공에서 영감을 받았으나 많은 요소가 부족함을 알았고 단순한 denoising pretraining이 더 잘된 다는 것을 알아냈다.
Transformers for vision
NLP에서의 Transformer의 성공에 영감을 받아 많은 논문에서 convolution과 self attention을 결합해 object detection이나 semantic segmentation에 적용하고자했다.
Vision Transformer (ViT)가 convolution-free aproach가 large lebeled dataset에서 좋은 성능을 보였음을 증명했다. 그리고 최근 이를 어떻게 semantic segmentation의 backbone으로 사용할지 연구가 진행되었다.
이 접근들은 decoder의 구조에서 다르지만 ViT를 기반으로 한 semantic segmentation의 위력을 보여줬다.
이 연구에서는 hybrid ViT를 backbone으로 적용했으며 patch embedding projection이 convolutional feature map으로부터 추출된 patches에 적용됐다.
또한 decoder의 크기를 연구했으며 decoder가 wide할수록 semantic segmentation results가 향상되는 것을 발견했다.
3. Denoising Pretraining
이 연구의 목적은 dense prediction tasks에 잘 전달되는 self-supervised image representation을 얻어내는 것.
denoising diffusion probabilistic models in image generation에서 영감을 받아 denoising objectives for unsupervised representation learning을 다시 살펴보고 최신 semantic segmentation에 적용했다.
Network architecture
네트워크 구조로 Transformer-based Unet구조 ( a.k.a TransUNet )를 사용했다. standard Unet에 12-layer Transformer가 통합된 형태이다.
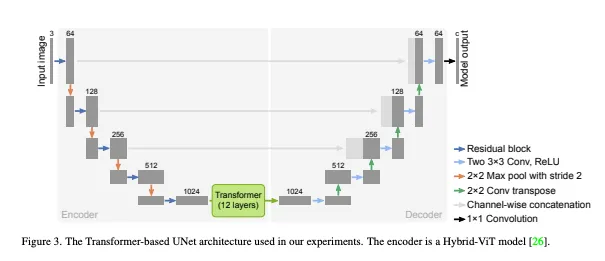
encoder : hybrid model comprising convolution and self-attention layers. encoder는 Hybrid-ViT와 똑같이 적용해 ImageNet-21K에서 pretrained된 weights를 사용할 수 있었다.
CNN feature extractor : ResNet-50
decoder : 3x3 convolution이 각 decoder block에 있는 standard Unet decoder
DDeP를 적용하는데에는 네트워크 아키텍쳐에 대한 제한은 딱히 없지만 본 연구에서는 TransUnet을 사용했다.
3.1. Denoising objective function
pretrain하는 목적이 되는 encoder-decoder 아키텍쳐 : , 는 로 parameterized
input :
output : ( semantic segmentation mask )
noise corrupted version input :
기존 denoising autoencoder : representation learning후 decoder는 제거하고 encoder만 classification을 위해 finetuning
Denoising pretraining : encoder와 decoder는 pretrained되고 함께 fine-tuned될 수 있다.
Denoising Diffusion Probabilistic Models에서의 denoising objective function
최근 denoising autoencoder는 Denoising Diffusion Probablilistic Models(DDPMs)라는 새로운 형태가 등장했고 이전과 가장 다른 점은 variance가 다양한 Gaussian noise를 제거하도록 학습된다는 것이다. 이전의 denoising autoencoders는 전형적으로 고정된 variance를 갖는 gaussian noise를 제거하도록 학습됐다. 더 나아가 DDPMs는 image를 바로 깨끗하게 만들기보다는 noise를 예측하도록 학습된다.
이러한 denoising autoencoder의 재부상으로 본 연구에서 semantic segmentation에 대한 denoising autoencoders로 학습된 representations의 효과를 연구한 것이다.
denoising autoencoders가 어필되는 한가지는 unlabeled data생성이 가능하다는 것이다.
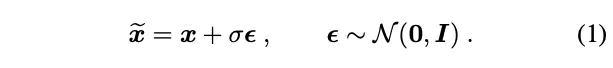
그래서 DDPM denoising objective를 semantic segmentation models의 pretrain에 사용가능한 것이다.
DDPMs는 noisy image를 다음과 같이 만들어낸다. (는 scalar noise level)

정도는 와 으로 조정된다.
이 두가지는 representation learning을 위해서는 차이가 별로 없어서 Eq. (1)을 사용했다.
[ denoising pretraining objective ]
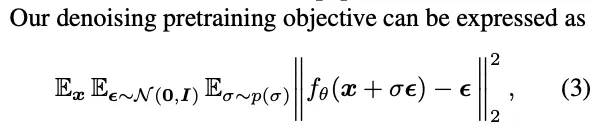
: image-toimage translation architecture such as UNet
: noise scheduler for a DDPM
실제 구현시에는가 하나의 값으로 고정된 simple denoising objective가 더 좋은 퀄리티의 representation을 학습한다는 것을 알게돼서 다음과 같이 정의했다. ( 를 고정시키고 더 단순화 )

이 식은 DDPMs로 모델링 된 diffusion process의 single iteration과 같이 생각할 수 있다.

⇒ 이 식은 간단히 해석하면 로 noise를 예측한 후 실제 noise와의 차이(L2 norm)를 줄이는 것이다.
encoder-decoder 아키텍쳐를 random initialization 이후 pretrain하는 것이 Denoising Pretraining이라 칭한다 ( DeP )
여기에 더해서 supervised learning과 denoising pretraining의 장점을 합쳐 Decoder Denoising Pretraining(DDeP)를 수행하며 이는 encoder를 classification-pretrained weights로 초기화하고 decoder만을 denoising으로 pretrain한다.
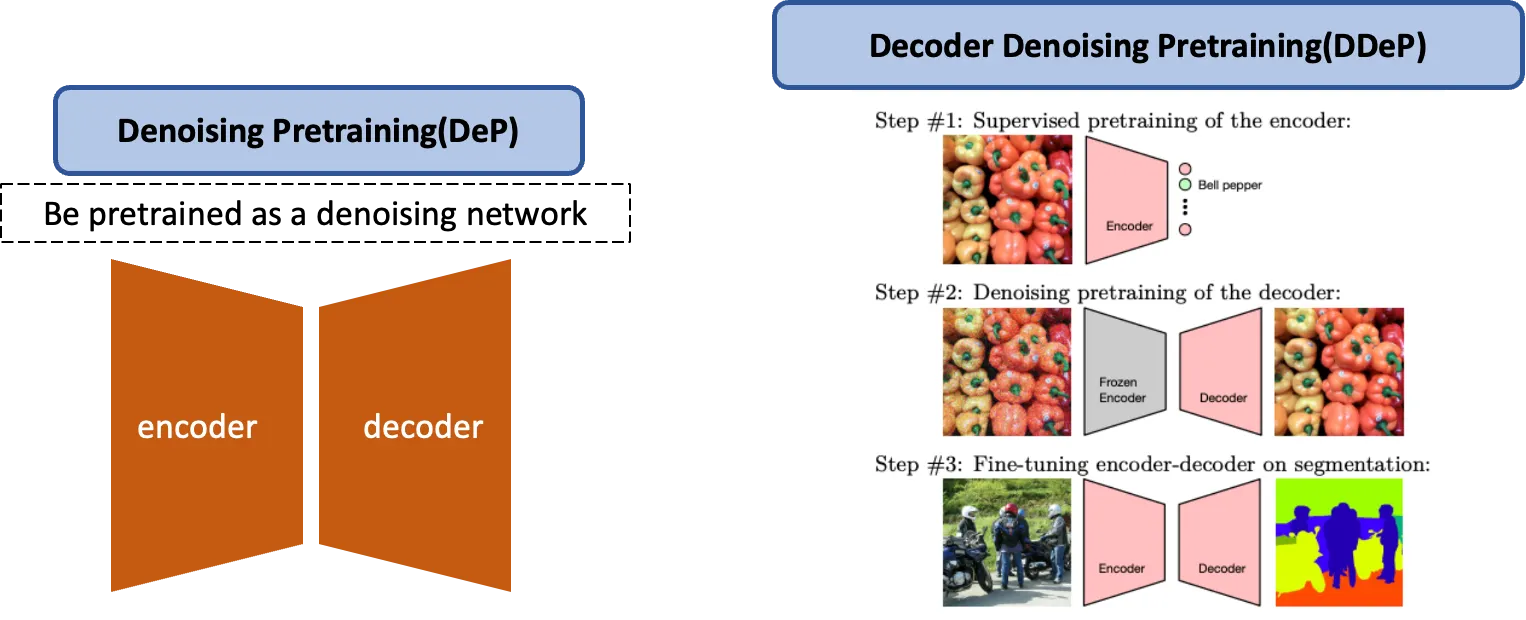
이전 연구에서 영감을 받아 noise vector를 예측하는 denoising objective를 정의하는 대신 의 output을 noiseless image 자체로 regress하는 것으로 할 수도 있다.
두 식의 차이는 input 의 output으로의 skip connection의 유무이다.
•
skip connection O : noiseless image 예측
•
skip connection X : noise 예측
skip connection이 명시되어있지 않으면 을 예측하는 것이 더 효과적이라고 판단했기 때문에 noise를 예측하는 것으로 진행했다고 한다.
또한 를 정하는 것은 representation의 퀄리티에 큰 영향을 미치는 것을 발견했다고 한다. 이를 시각화한 그림을 Fig. 4에 보여주었다.

추가로 pixel값은 [-1, 1]로 범위를 정했다고 한다. 따라서 픽셀들은 approximately conform to a zero mean and unit variance.
semantic segmentation으로 finetuning하기 전에 마지막 projection layer를 제거하였다고 한다.
3.2. Extension to diffusion process
값이 고정된 가장 간단한 case에서 이 논문에서 제안하는 DDeP는 diffusion process의 한 step이라고 볼 수 있다.
DDeP가 full diffusion process와 유사해질 수 있게 extensions를 연구했다고 한다.
Variable noise schedule
DDPMs은 clean image로부터 pure noise 를 생성해내거나 그 반대의 process도 수행한다. 그리고 는 각 training example마다 [0, 1]에서 랜덤하게 샘플링된다. 앞에서 말했듯 이 연구에서는 fixed 가 더 효율적인 것을 알았으나 랜덤하게 뽑은 로도 실험을 진행했다. 이는 ablation study에서 다룬다.
Conditioning on noise level
diffusion formalism에서 model은 한 nosie level에서 다음으로 변환하는 함수를 의미한다. 그러므로 현재 noise level에 영향을 받는다.
이는 실제로 구현될 때에 각 training example을 위해 샘필링된 추가적인 model input으로 를 추가해줌으로써 구현된다.
이 연구에서는 거의 고정된 noise level을 사용했기 때문에, conditioning은 필요하지 않았다고 한다.
Weighting of noise levels
DDPMs에서는 loss에서의 다른 noise levels에 각각의 weights를 주는데 이것이 sample quality에 큰 영향을 준다. 이 연구의 실험들이 다양한 noise levels가 transferable representations를 학습하는데에 필수적이지 않기 때문에 이들은 다른 noise levels에 가중치를 주는 실험은 하지 않았다고 한다. 그러나 추후 연구에서 흥미로운 방향이 될 것이라고 한다.
3.3. Hyperparameters and design choices
오직 하나의 파라미터인 noise level
이 값이 작을 수록 DDeP에서 잘 동작하고 클수록 DeP에서 잘 동작했다고 한다.
DDeP와 DeP에서 0.1, 0.8이 각각의 최적의 값이었다고 한다.
