
Grouped convolution
기존 2D convolution problem
1.
Expensive Cost
2.
Dead Channels : 신경망의 학습 과정에서, 출력 결과에 영향을 거의 미치지 않는 채널들
3.
Low Correlation between channels
for contextual Information
•
receptive field 확장 ( e.g. kernel size 확장 )
•
conv layer 더 많이 쌓기 ( 더 유의미한 정보 추출 )
•
contextual information을 더 잘 뽑기 위한 방법들은 보통 연산량이 많아진다
연산량은 줄이면서 정보 손실은 일어나지 않게 하는 방법이 없을까?→ 여러 conv 방식들
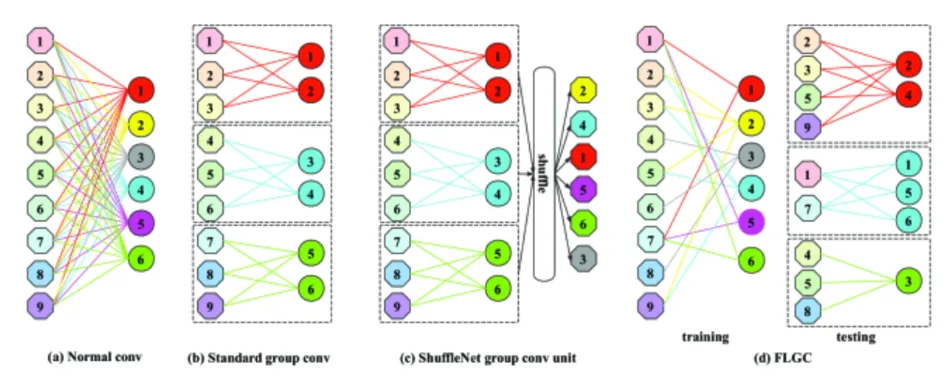
channel간의 dependency 를 끊어서 연산
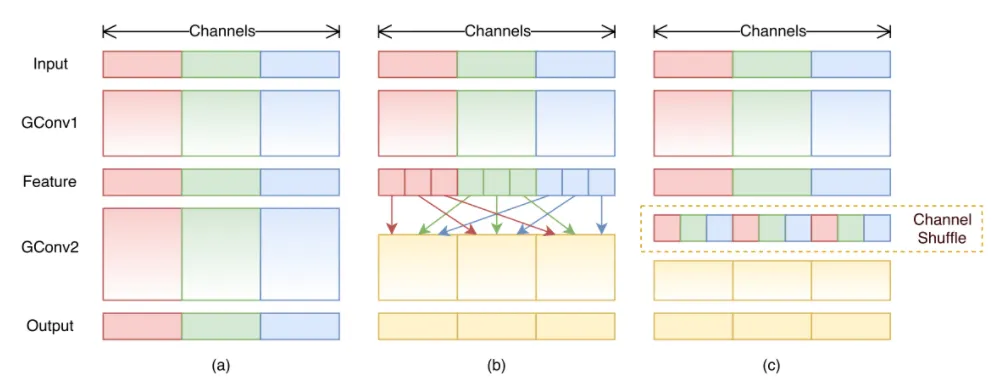
위 그림의 (c) ShuffleNet narrow receptive field 해결. 이 shuffle은 hyper parameter로 개발자의 개입이 필요하므로, D를 제안
그 중 ResNext에서 소개된 grouped convolution
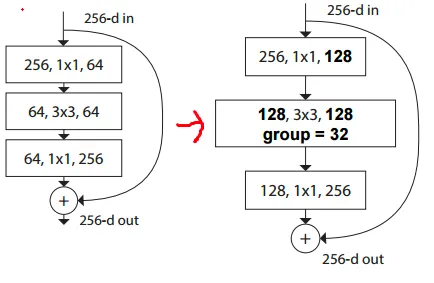
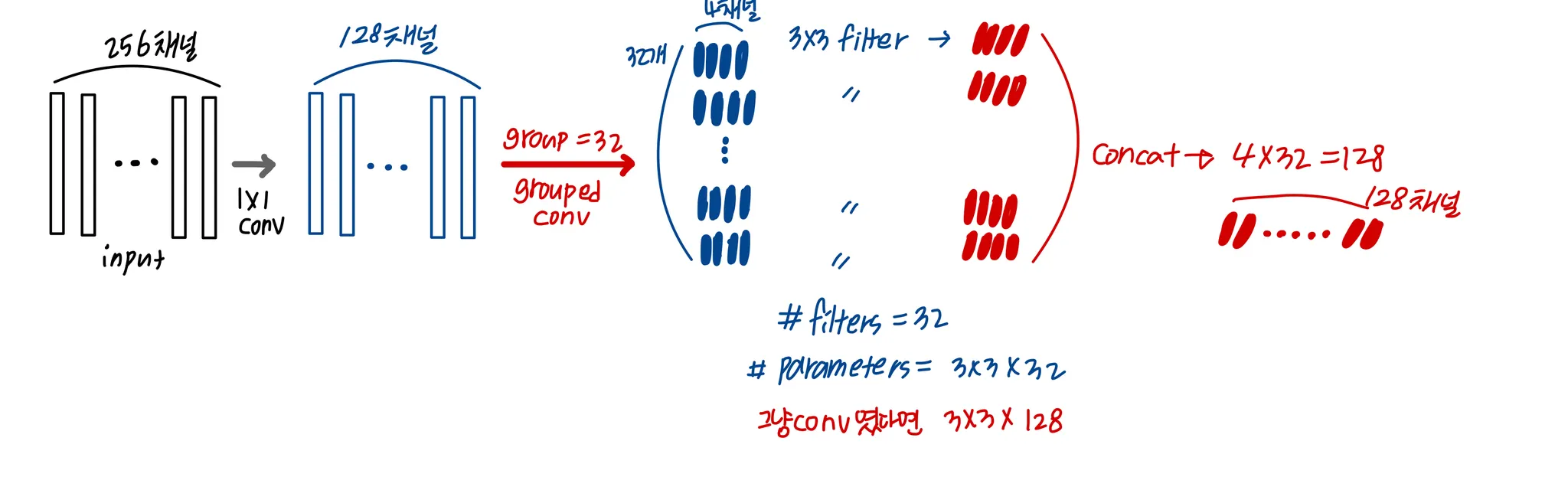
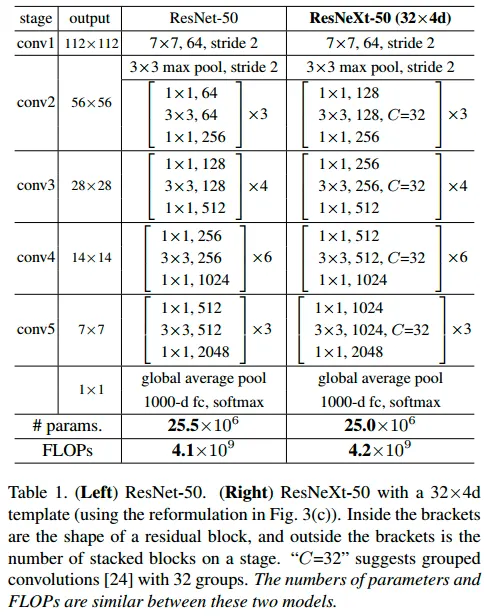
ResNet의 bottleneck을 다음과 같이 수정
여기서 group 은 hyper parameter로, 조정 가능한 파라미터 입니다. ( cardinality라고 함 )
이는 VGG Net에서 gpu의 한계로 채널수를 두개로 쪼개 연산했을 때

이렇게 서로 다른 특징에 집중해 학습이 된 점에서 영감을 받은 방법입니다.
bottleneck에도 위에서 보인 그림과 같이 grouped cov로 수정하였을 때 성능이 향상되었다
( filter 수 증가보다 효과적이었다고 함 )
width/depth 를 증가시키는 방법과의 비교
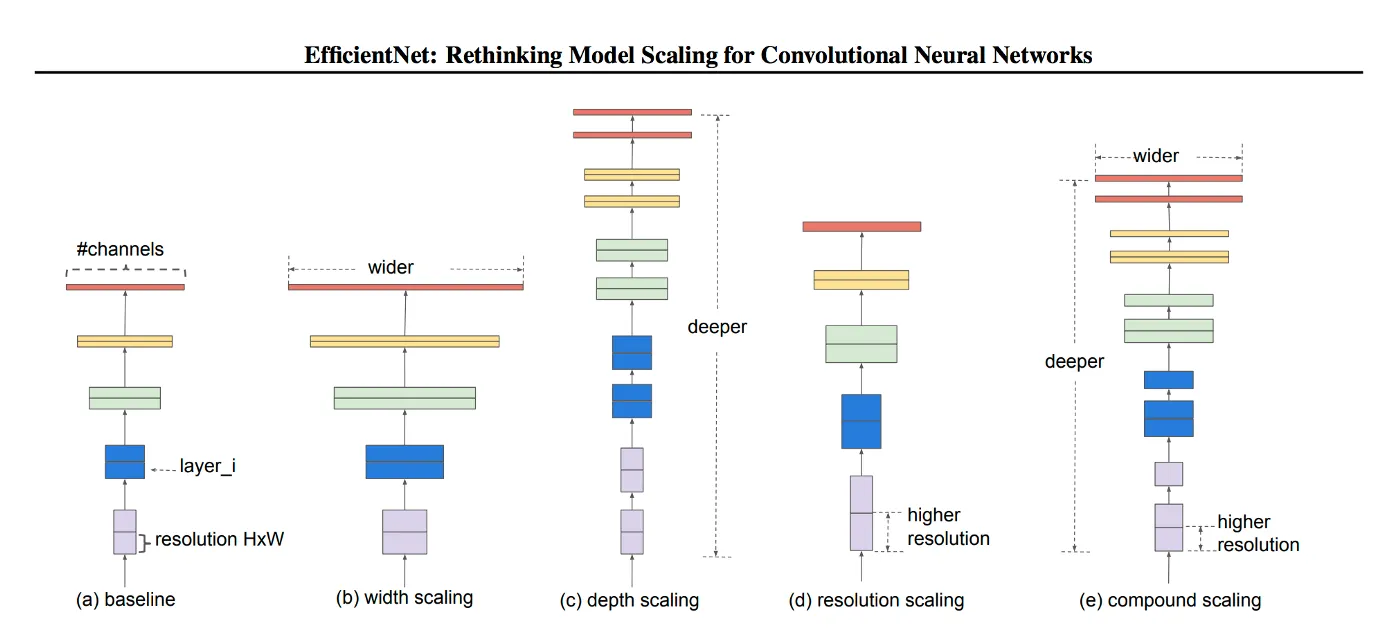
efficientnet의 자료. model scaling 의 방법 정의들
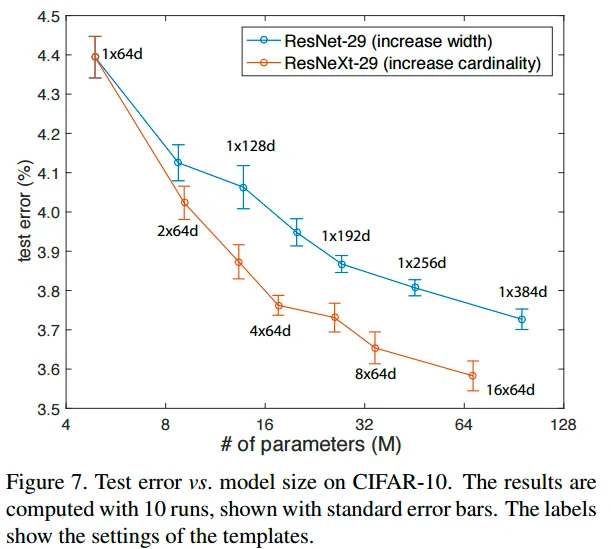
WRN(wide residual network)에서 width의 증가가 성능의 향상으로 이어진다는 것을 증명했으나, cardinality를 증가시키는 것이 더 효율적 ( 동일한 파라미터 수, 같은 성능 ) 이라고 말함
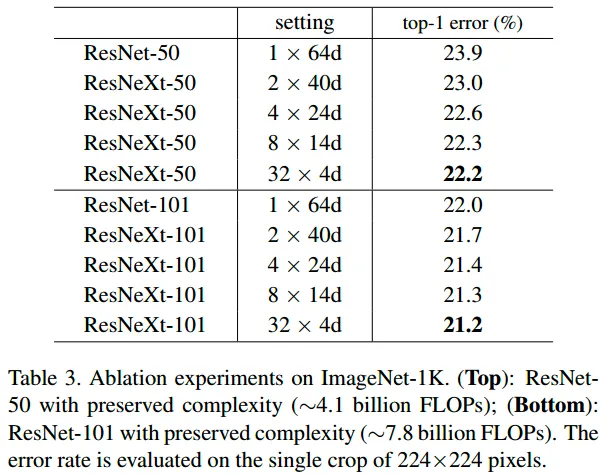
최적의 그룹수는 32이다
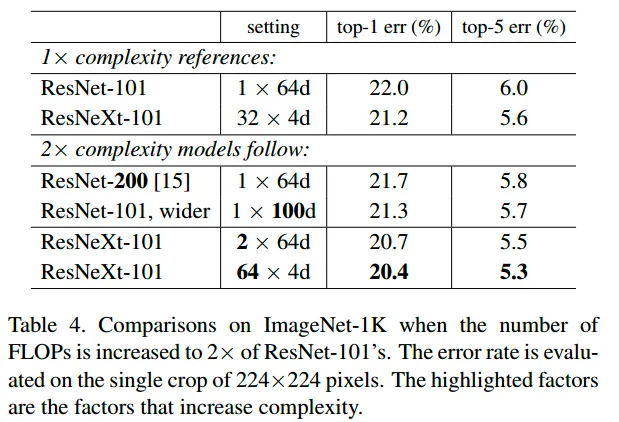
[성능 비교 ] ResNet-200 < ResNet-101 wider < ResNext-101
depth < width < cardinality 의 결과가 나왔습니다
ResNext Architecture
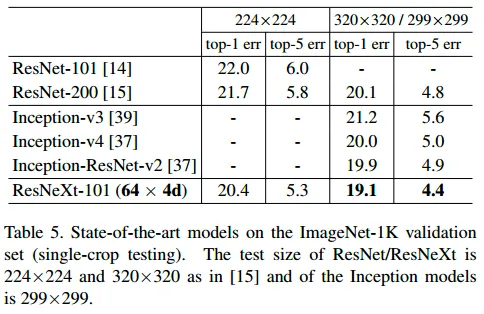
SOTA 모델과의 비교
•
input의 해상도가 증가할수록 에러 감소
•
inception 계열 모델들보다 에러 감소
•
Deeper ResNet 모델보다 에러 감소
•
동일한 depth의 ResNet-101과는 꽤 많이 차이가남( 다른 모델들보다 상대적으로 )
