
Abstract
weak-to-strong consistency framework를 다시 고려한다. 이 방식은 2020년도에 발표된 FixMatch라는 semi-supervised classification 방식으로 유명하다. 이는 weakly perturbed image에 대한 예측으로 strongly perturbed image을 학습하는 방식이다. 이를 이 이 연구에서는 semantic segmentation 시나리오로 가지고 왔다. 이전 연구에서의 성능은 직접 디자인한 strong data augmentation에 매우 많이 의존했는데, 이는 넓은 perturbation space를 탐색하기에는 매우 한정되고 적합하지 않다. 이를 문제라고 생각하여 보조적인 feature perturbation stream을 보조로 제안해 perturbation space를 확장시켰다. 한편 original image-level augemtation을 충분히 탐색하기 위해서 dual-stream perturbation technique를 제안한다. 이는 두개의 string views가 동시에 common weak view를 가이드하도록 해준다.
이렇게 제안하는 Unified Dual-Stream Perturbations approach (UniMatch)는 Pascal, Cityscapes, COCO 벤치마크들에서 기존 방식들의 성능을 뛰어넘었다. remote sensing interpretation과 medical image analysis에서도 우수성을 입증하였다.
Introduction
기존 semi-supervised learning 방식들은 크게 다음과 같이 발전했다.
GAN-based → consistency regularization framework → self-trainig pipeline
이 연구는 consistency regularization 에 집중했다.
FixMatch
FixMatch에서 쓰인 weak-to-strong 방식은 unlabeled image를 wekly pertured image ()가 strongly perturbed image()를 지도하며 이를 다음 그림과 같이 표현할 수 있다.

직관적으로 봤을 때 에 대한 예측이 잘 나와야 가 모델 학습에 저 효과적일 것이다. 이것에 의해 성능이 많이 좌우된다. 왜냐하면 strong perturbation이 confirmation bias를 완화시키는 추가적인 정보를 제공하기 때문이다.
적절한 strong perturturbations가 주어진다면 FixMatch 방식은 semantic segmentation 시나리오에 가져와도 뛰어난 일반화 성능으로 SOTA를 뛰어넘는다. 이는 아래 Fig. 1에서 확인할 수 있다.

Image-level strong perturbations
Image-level strong perturbations에 대해서 탐구한 결과, FixMatch방식을 semi-supervised semantic segmentation에 적용해 강력한 성능을 내는데에 큰 역할을 한다는 것을 발견했다. 이는 Table 1. 의 결과에서 나타난다.

strong perturbation을 강하게 적용할 수록 성능향상이 이루어진다. 본 연구에서는 이를 두가지 관점에서 발전시켰다.
•
perturbation space 확장
•
original perturbations의 효과 충분히 적용
Color Jitter와 CutMix같은 image-level perturbations는 FixMatch에 추가 사전정보를 도입해 consistency regularization의 장점을 취하게 되는 heuristic biases가 포함된다.
이 perturbations가 적용되지 않으면 FixMatch는 성능이 떨어진다.
Feature-level perturbation
이 효과에도 불구하고 이는 image-level에 한정되고 모델이 더 넓은 perturbation space를 탐색하지 못하게 하여 다양한 수준에서의 consistency를 고려하지 못하게 한다. 이 때문에 perturbation space 확장을 위해 raw image와 그로부터 추출된 features에 대해 unified perturbation framework을 설계했다.
raw image에 대해서는 FixMatch와 유사하게 미리 정의된 image-level strong perturbations가 적용되고, weakly perturbed image로부터 추출된 features에는 간단한 channel dropout이 적용된다.
이러한 방식으로 이들의 모델은 이미지와 임베딩 레벨 모두에서 unlabeled images의 예측의 equivalence를 추구한다. 두 perturbation levels는 상호보완적인 역할을 한다.
perturbations의 각 레벨을 독립적인 스트림으로 두어 학습이 원활하도록 했다.
반면 현재 FixMatch framework는 각 unlabeled image에 오직 하나의 strong view만 사용하고 이는 미리 정의해둔 perturbation space를 탐색하기에 충분하지 않다. 따라서 랜덤하게 두개의 독립적인 strong view를 사용하는 방법을 택했다. 이 view들은 student model에 평행하게 들어가고 동시에 weak view에 의해 지도된다.
이러한 작은 변조들이 FixMatch baseline을 강력한 SOTA framework로 만들었다.
⇒ UniMatch는 두개의 strong view를 weak view에 가깝게 함으로써 strong view 사이 거리를 최소화하며 이는 contrastive learning의 개념과 장점을 공유한다.
contributions
•
적절한 image-level strong perturbations와 결합헤 FixMatch가 semantic segmentation 시나리오로 전환될때 여전히 강력하도록 한다.
•
FixMatch를 기반으로 더 넓은 perturbation space를 활용하기 위해 image-level 및 feature-level perturbation을 독립적인 스트림으로 통합하는 a unified perturbation framework을 제안한다.
•
pre-defined perturbation space를 완전히 탐색하고 discriminative representation을 위한 contrastive learning의 장점을 적용하기 위해 dual-stream perturbation strategy를 설계한다.
•
위 두 구성요소를 통합한 프레임워크 UniMatch는 Pascal, Citiscapes, COCO의 모든 평가프로토콜에서 기존 방법을 능가하며 의료영상 분석과 remote-sensing 해석에서도 우위를 보인다.
Method
unlabeled images:
labeled images:
supervised loss : , cross-entropy loss
supervised loss : , unsupervised loss
objective function : +
student model :
teacher model :


는 와 사이의 entropy연산을 의미하며, 는 일정 threshold 보다 probability값이 큰 에 대해서만 loss를 연산한다.
Unified Perturbations for Images and Features
•
의 features에 perturbation을 추가
•
모든 레벨 (image-level, feature-level)의 perturbations를 독립적인 스트림으로 구성해 student가 각 스트림에서 목표로하는 consistency를 바로 달성할 수 있도록 함
수식 :
: encoder
: decoder
: feature perturbations (e.g. dropour or adding uniform noise)

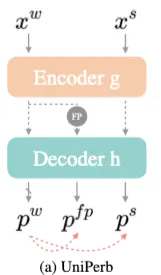
왼쪽의 그림처럼 각 unlabeled mini-batch에서
여기서 unsupervised loss는 다음과 같다

식 (2)와 같지만 와 사이의 entropy를 최소화하는 목적이 추가됐다.
이를 통해 student가 image level 과 feature level 에서 unified perturbations에 대해 consistent하게 학습하게 된다. 논문에선 이를 UniPerb로 이름지었다.
•
각 perturbation의 스트림을 나누는 것이 중요
•
feature level perturbation이 image level perturbation을 보완
Dual-stream perturbations
최근 연구들에 따르면 unlabeled data input의 여러 views를 사용하는 것이 perturbations를 더 잘 사용할 수 있다.
•
SwaV의 multi-crop
•
ReMixMatch의 multiple strong augmentation
그래서 하나만 넣어주는 대신 다르게 strongly perturbed된 input 과 를 input으로 넣어준다
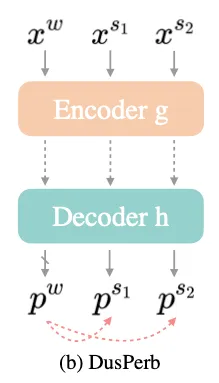
왼쪽 그림이 이를 나타낸다.
이렇게 strong views를 shared weak view로 규제하는 것은 이 두 strong views 사이의 consistency를 강제하는 것으로 볼 수 있다.
•
가 예측한 클래스(pseudo label)에 대한 classifier weight :
•
과 의 features: 각각 ,
•
cross entropy를 적용했을 때 에 대한 의 비를 최대화하는 것이 됨
여기서
•
결국 , 의 유사성을 최대화하는 것이 되므로 InfoNCE loss를 만족하게 된다.
식으로 나타내면 다음과 같다.

이는 contrastive learning의 목적을 공유하게 되어 discriminative representations를 학습할 수 있게 된다.
UniMatch
요약하자면 unlabeled images에 대한 두개의 중요 기술을 제안하며, UniPerb, DusPerb로 이름지었다.
두 방식을 합친 것이 UniMatch로 다음과 같다.


에 feature perturbation을 적용하고, multi-view learning이 적용된 걸 확인할 수 있다. 최종 unsupervised loss는 다음과 같다.

본 연구의 실험에서 로 사용됐다.
Experiments
Implementation Details
•
model : DeepLabv3+
•
initial learning rate: 0.001, 0.005, and 0.004 for Pascal, Cityscapes, and COCO respectively
•
SGD optimizer.
•
The model is trained for 80, 240, and 30 epochs under a poly learning rate scheduler.
•
:color transformations from ST++ [68] and CutMix [71] to form
•
A raw image is resized between 0.5 and 2.0, cropped, and flipped to obtain its weakly augmented version .
•
The training resolution is set as 321, 801, and 513 for these three datasets(Pascal, Cityscapes, and COCO).
•
By default, we adopt a channel dropout of 50% probability (nn.Dropout2d(0.5) in PyTorch) as our feature perturbation, which is inserted at the intersection of the encoder and decoder.
Results
Pascal dataset


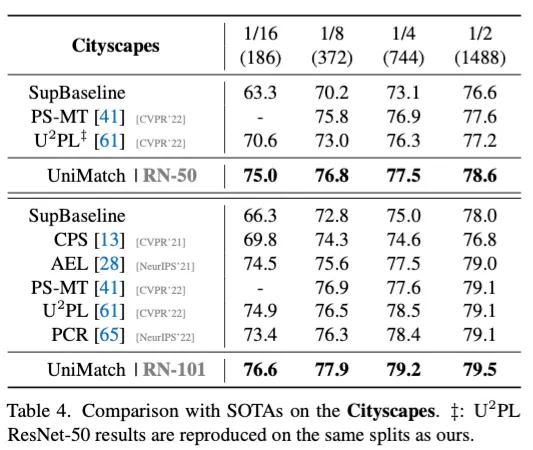
Cityscapes dataset
COCO dataset

제안 방법들의 효과 연구 (ablation)

