
Introduction
•
DCGAN(2016) 이전에 나온 논문으로, CNN 기반이 아닌 MLP 기반 모델이다.
•
GAN은 많은 난해한 probabilistic computations를 근사화하는 어려움을 피하기 위해 생성 모델을 훈련하기 위한 대안 프레임워크로 도입됨. Markov chains가 필요하지 않은 장점이 있으며 backpropagation만이 gradient를 구하기 위해 사용된다.
•
GAN은 SOTA log-likelihood estimates와 realistic samples를 생성할 수 있다.
•
GAN의 conditional version이라고 할 수 있다. y라는 조건/추가정보(e.g. class label )을 G와 D에 준다.
•
MNIST 데이터로 실험했으며
•
multi model 모델 학습의 활용을 보여주고 이 접근방식(CGAN)이 training labels의 일부가 아닌 descriptive tags를 생성하는 방법을 보여주는 image tagging에 대한 적용예시도 보여준다
3. Conditional Adversarial Nets
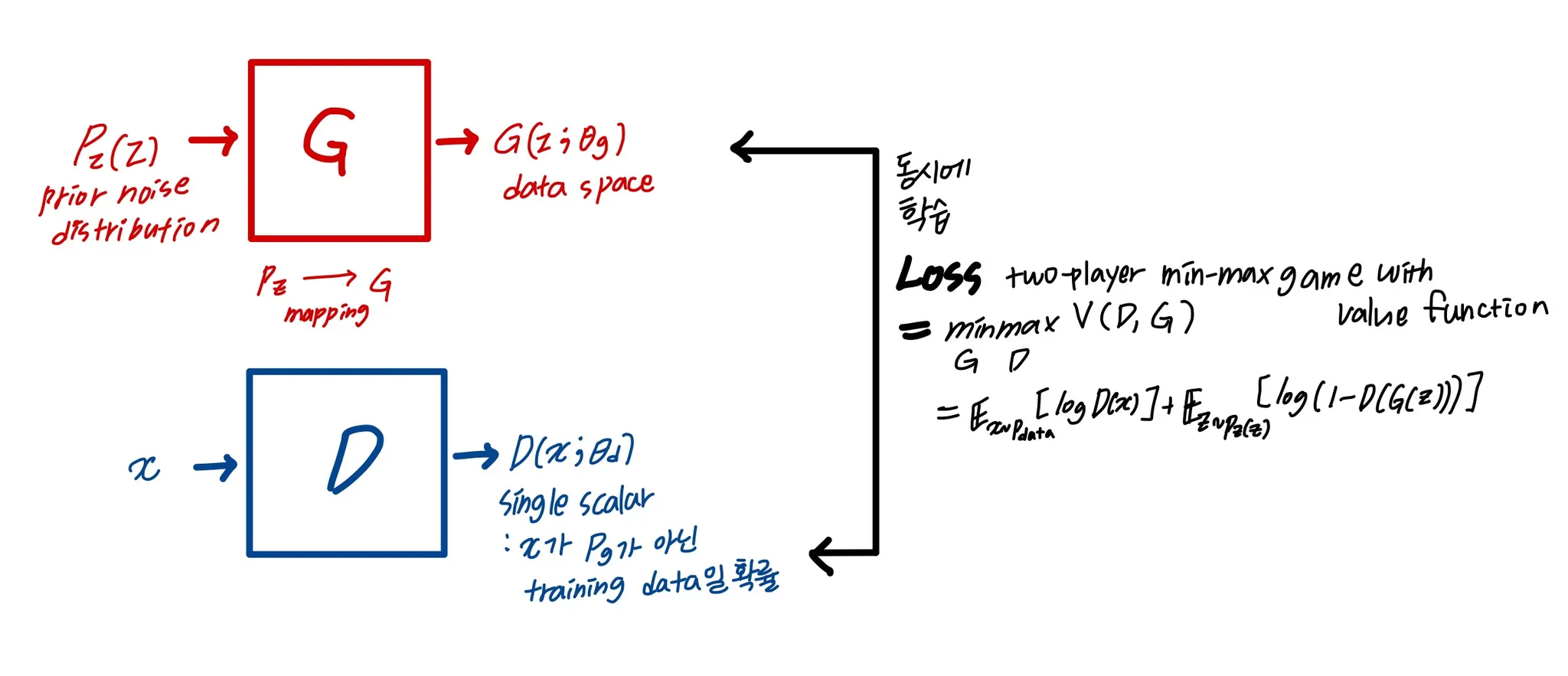
3.1 GAN
G : data distribution을 capture
D: sample이 G가 아니라 sample data에서 왔을 확률을 예측
G와 D는 non-linear mapping function일 수 있다 ( multi-layer perceptron처럼 ( MLP처럼 ) )
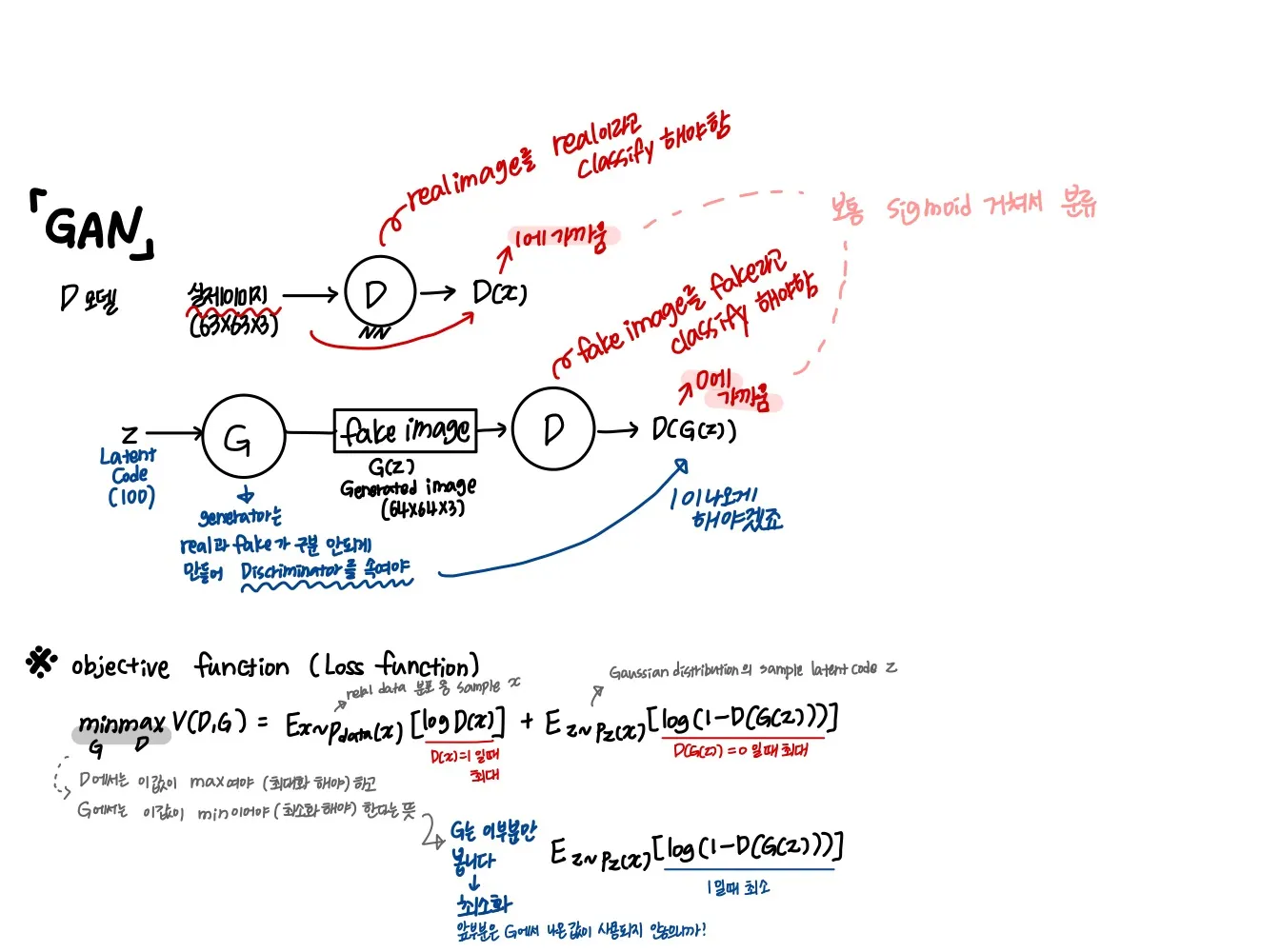
3.2 CGAN
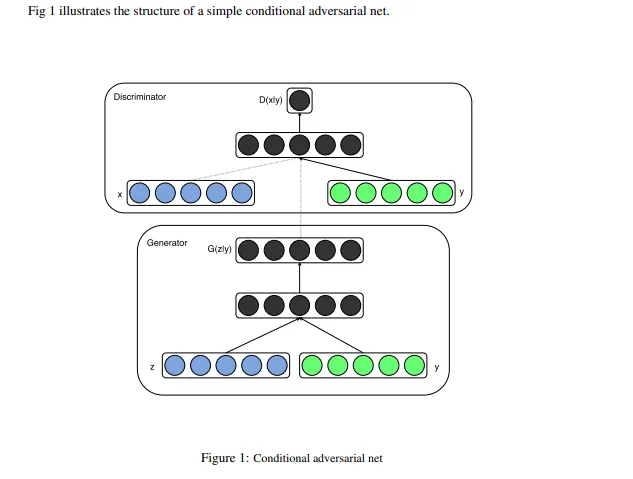
GAN의 conditional model로서의 확장
G와 D가 몇 extra information인 y로 conditioned되었을 경우
•
y : 어떤 종류던간에 추가 정보 (auxiliary information) (e.g. 다른 modalities에서 나온 class labels)
y를 D와 G에 추가 input layer로 넣어줌으로써 구현
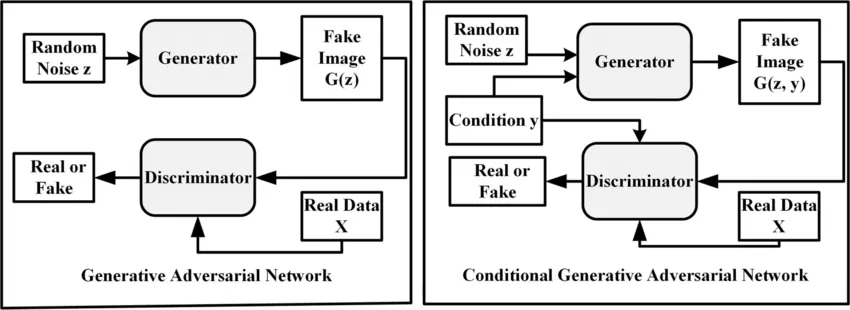
G에서 prior input noise 와 y는 joint hidden layer 에서 합쳐진다
이 hidden representation을 구성하는 방법은 adversarial training framework에 의해 상당한 유연성이 허용됨
D에서는 와 가 input으로 표현되고 discriminative function으로 들어간다. (이때는 MLP에 의해 다시 embodied된다)
4. Experimental Results
4.1 Unimodal
•
MNIST 데이터로 실험
•
one-hot encoding한 class label로 conditioning ( y로 들어감 )
in G
: 100 dimensions, drawn from uniform distribution within the unit hypercube
1.
와 는 각각 200차원, 1000차원 ReLU hidden layer 로 매핑
2.
이후 1200차원 hidden layer + ReLU 로 합쳐짐
3.
마지막엔 sigmoid unit layer (784차원의 MNIST sample을 생성하기 위한 output 레이어) ⇒ 784차원으로 변환된다 ( MNIST 이미지가 크기 )
in D
input → maxoutlayer(240 units, 5pieces) 매핑
→ maxoutlayer(50 units, 5 pieces) 매핑
1.
두 hidden layer는 joint maxout layer( 240 units, 4 pieces ) 로 매핑되고
2.
sigmoid 레이어 들어감
[ training ]
•
SGD사용
•
batchsize 100
•
initial learning rate 0.1 , decay factor 1.00004로 exponentially decreased down to 0.000001
•
momentum 은 initial value가 0.5, 0.7까지 증가
•
Dropout은 probability 0.5로 G와 D 모두에 적용
•
validation set에서 log-likelihood가 최대인 예측이 stopping point
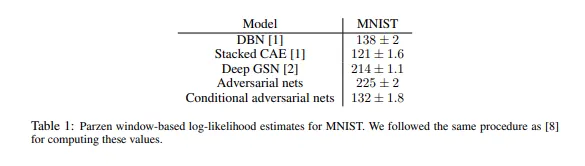
비교실험
CGAN이 성능 좋았다
이러한 결과를 efficacy(효능)의 입증보다는 proof-of-concept(개념 증명)으로 제시하며, hyper parameter space과 아키텍처의 further exploration이 있기 때문에 conditional 모델이 non-conditional 결과와 일치하거나 초과해야 한다고 믿는다고 언급

Fig2를 통해 y에 따라 다른 결과가 나온다는 것을 알 수 있다.
4.2 multimodal
여러 이미지들에 대해 사람이 직접 넣은 태그와 CGAN이 생성해낸 태그를 비교한 테이블
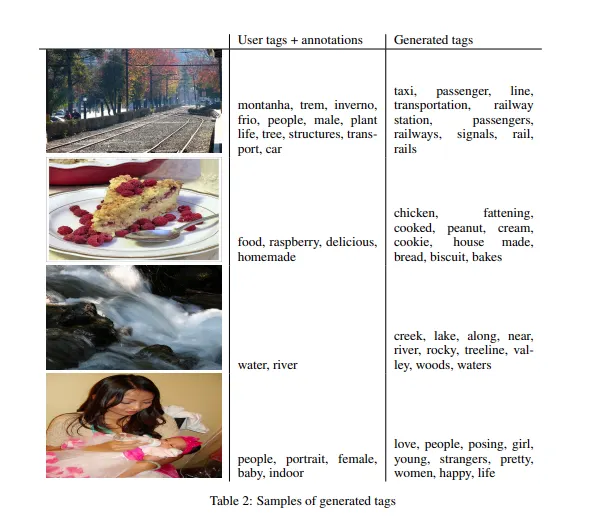
CGAN을 활용해 multi-label prediction으로 image를 automated tagging하는것을 증명한다.
여기서 CGAN은 image feature가 조건으로 들어가는 tag-vectors의 분포를 생성한다
image features : ImageNet으로 pretrain된 conv 모델에서 마지막 4096 units의 fully connected layer를 통과한 image representations
1.
world representation을 위해 처음으로 먼저 YFCC100M 데이터 세트 메타데이터에서 사용자 태그, 제목 및 설명을 결합하여 텍스트 corpus(말뭉치)를 수집한다.
2.
텍스트를 전처리하고 청소한 후 단어 벡터 크기가 200인 skip-gram model[14]을 교육.
3.
단어에서 200번 미만의 단어를 생략하고 247465 크기의 사전을 만들었습니다.
Adversarial Net을 훈련하는 동안 convolution 모델과 language model을 고정시킨다.
1.
실험을 위해 MIR Flickr 25,000 데이터 세트[10]를 사용하고 위에서 설명한 컨볼루션 모델과 언어 모델을 사용하여 이미지 및 태그 features를 추출한다.
2.
태그가 없는 이미지는 실험에서 생략되었고 주석은 추가 태그로 처리되었습니다.
3.
처음 150,000개의 샘플이 training set로 사용되었으며. 각 associated tag마다 multiple tag 이미지가 훈련 세트 내에서 한 번씩 반복되었습니다.
<test>
1. 평가를 위해 각 이미지에 대해 100개의 샘플을 생성하고 각 샘플에 대한 어휘의 벡터 표현의 코사인 유사성을 사용하여 가장 가까운 상위 20개의 단어를 찾는다.
2.
100개의 샘플 중에서 가장 일반적인 10개의 단어를 선택합니다.
가장 성능이 좋았던 G는
1.
100 size의 Gaussian noise를 받고 500 dimension의 ReLU 레이어로 매핑한다. 그리고 4096차원의 이미지 feature vector를 2000 dimension의 ReLU hidden layer로 매핑
2.
두 레이어 모두 200차원의 linear layer라는 joint represntation으로 매핑됨. 이것이 generated word vector인 output이다
D는
1.
500(for word vectors) 그리고 1200(for image features)의 차원의 ReLU hidden layers
2.
+ maxout layer( 1000 units, 3pieces )(join layer)
3.
+ single sigmoid unit
<training>
•
SGD 사용
•
batch size 100
•
initial lr 0.1, 0.000001까지 exponentially decrease, decay factor 1.00004
•
momentum 은 0.5에서 0.7까지 증가
•
0.5 확률로 dropout ( both G and D)
•
hyper parameter와 architecture 선택은 cross-validation 과 mix of random grid search, manual selection(albeit over a somewhat limited search space)로 결정
