weakly supervised semantic segmentation (WSSS) 에서 보통 사용되는 CAM을 활용한 방법에서 CAM의 정확도를 높이고자 제안된 attention mechanism이다.
Abstract
Image-level weakly supervised semantic segmentation 에 대한 논문이다. weakly supervised 에는 다양한 종류가 있으나, image-level이라 함은 이미지에 대한 classification label 만 사용 가능한 경우이다.
이에 대한 대부분의 연구에서 CAM을 통한 솔루션을 내놓았으나 full supervision과 weak supervision의 차이 때문에 CAM이 object mask로서 기능하는데에는 한계가 있었다.
이 논문에서는 self-supervised equivariant attention mechanism (SEAM)을 제안하여 이 gap을 줄이고자 한다.
SEAM은 다음의 관찰을 기반으로 한다.
•
equivariance가 fully supervised semantic segmentation에서의 암시적인 제약이다.
•
equivariance는 data augmentation 시에 input image에 적용되는 spatial transformation이 pixel-level labels에 똑같이 적용된다는 것이다.
•
그러나 이 제약은 image-level supervision으로 학습된 CAM에서는 사라진다. → classification으로 학습되기에 이러한 제약이 사라짐
그래서 다양한 transformed images에서 예측된 CAMs에 consistency regularization을 제안해 네트워크 학습에서 self-supervision을 적용한다.
추가적으로 pixel correlation module(PCM)을 제안해 context appearance information을 이용하고 현 픽셀에 대한 예측을 비슷한 이웃들로 refine한다. 이는 CAMs consistency의 향상을 가져온다.
실험은 PASCAL VOC 2012 dataset에서 이루어졌고 같은 레벨 supervision에서 SOTA를 넘어섰다.
Introduction
semantic segmentation은 필수적인 컴퓨터 비전 task이고 pixel-wise classification을 예측하는 것이 목표이다. 딥러닝이 발전하면서 이에 대한 많은 발전이 있었으나 다른 task보다 라벨을 만드는 것이 어려운 것이 문제였다.
이를 해결하기 위해 많은 노력이 있었고 WSSS는 그 노력 중 하나이다.
WSSS에서 pixel-level label 대신 사용하는 라벨 형식들 1. image-level classification label, 2. scribbles, 3. bounding box 등
이 논문에서는 image-level classification label을 사용했다.
최근 WSSS연구의 대부분은 CAM을 활용했고 이는 image classification labels로 객체를 localize하는데 효과적이다. 그러나 CAMs는 가장 구별 가능한 부분만 커버하여 background에 잘못 activate되기도 한다. 또한 생성된 CAM들은 이미지가 affine transformation이 적용되면 consistent하지 않다. ( Fig. 1 )

rescaling transformation을 적용하자 생성된 CAM들에 매우 심한 inconcsistency가 나타남
이 현상의 근본적 원인은 fully supervised 와 weakly supervised의 supervision gap 때문이다
Contributions
•
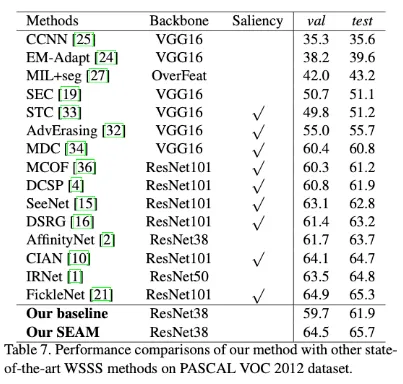
self-supervised equivariant attention mechanism ( SEAM ) 을 제안해 pixel correlation module ( PCM )로 equivariant regularization을 적용했다.
•
siamese network 구조로 equivariant cross regularization (ECR) Loss를 효과적으로 PCM과 self-supervision에 결합했다. 이를 통해 CAM에서 over-activated regions와 under-activated regions를 줄였다.
•
PASCAL VOC 2012에서 실험을 통해 이 알고리즘이 SOTA performance를 달성했음을 확인했다.
Related work
weakly supervised semantic segmentation
self-supervised learning
self-supervised learning은 pretext task를 디자인해 추가적인 manual annotation없이 라벨을 생성한다.
pretext task로 생성된 라벨들은 네트워크가 더 robust한 representation을 학습할 수 있도록 self-supervision을 제공한다.
Approach
1.
motivation
2.
equivariant regularization
3.
pixel correlation module
4.
SEAM Loss design
순으로 설명된다.
Motivation

다음과 같이 정의하였을 때 대부분의 WSSS들은 “와 가 같을 때가 classification과 semantic segmentation의 최적의 파라미터다.” 라는 가설에 기반하기 때문에 classification network를 먼저 학습시키고 pooling function을 제거하는 방식으로 segmentation을 수행한다.
그러나 두 함수 (, )의 특성은 매우 다르다!
affine transform 가 있다고 하면, 이를 각 샘플에 적용을 할 시 segmentation function은 more equivariant한 경향이 있다
⇒
classification의 경우 ⇒ ⇒ invariance에 더 집중한다.
classification에서의 invariance는 보통 pooling 연산 때문에 발생한다. 그래서 이와 같이 equivariant constraint가 존재하지 않기에 두 task가 학습 시 같은 objective를 달성하기 힘들다. ⇒ 추가적인 규제가 필요하다.
self-attention은 네트워크의 추정 능력을 높이기 위해 널리 적용되는 메커니즘이다. context feature dependency를 포착해 피쳐맵을 revise한다. ⇒ 이는 픽셀간의 유사도를 사용해 원래 activation map을 refine한다는 점에서 대부분의 WSSS방법의 아이디어와도 맞는 부분이 있다.
self attention 을 수식으로 나타낸 Eq. (1), (2)

consistent prediction 능력 향상을 위해 self attention과 equivariant regularization을 통합해 SEAM을 제안한다.
Equivariant Regularization
fully supervised semantic segmentation 에서 data augmentation 시 input image와 pixel-level labels는 같은 affine transforms가 적용되어야 한다. ⇒ Implicit equivariant constraint
반면 WSSS에서는 image level label만 사용 가능하기에 이것이 사라진다. 그러므로 equivariant regularization을 적용한다.
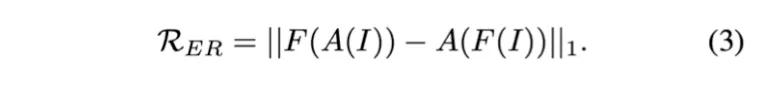
는 rescaling, rotation, flip 같은 spatial affine transformations를 의미한다.
original network에 이를 적용하기 위해 네트워크를 shared-weight siamese structure로 확장시켜 한 브랜치에서는 네트워크 아웃풋에 transformation을 적용하고 한 브랜치에서는 네트워크 입력 전 transformation을 적용했다. 그래서 두 브랜치에서 나온 activation maps가 CAM의 consistency를 보장할 수 있도록 했다. 이는 Loss에서 반영된다.
Pixel correlation module
equivariant regularization의 추가적 supervision에도 오직 convolutional layers만으로 이상적인 equivariance를 달성하는 것은 어려운 일이다.
self-attention module은 context information을 얻고 pixel-wise prediction 결과를 refine하는데에 효과적이므로 이를 CAM refinement에 적용한 것이 Eq. (4) 와 같이 된다.

\hat{y} : original CAM
y : revised CAM
original CAM이 g함수로 residual space에 임베딩되고 각 픽셀은 Eq. (2)에서와 같이 similarity로 통합된다.
세개의 embedding functions 는 각각의 1x1 convolution으로 적용된다.
original CAM을 context information으로 더 잘 refine하기 위해 네트워크 끝에 pixel correlation module (PCM)을 제안한다.
PCM은 self attention mechanism의 핵심파트를 조금 변형하고 equivariant regularization의 지도를 받아 학습된 것이라고 할 수 있다. inter-pixel feature similarity를 연산하기 위해 cosine distance를 사용했다.

여기서 normalized feature space에서의 inner-product를 택해 현재 픽셀 i와 다른 픽셀들의 유사도를 계산했다. 이 f를 조금 변형해 Eq. (1)에 대입하면
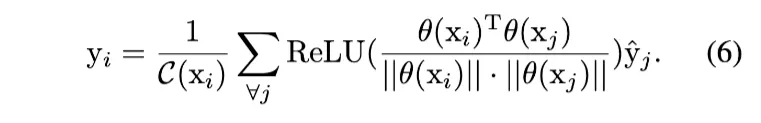
similarities는 ReLU를 통해서 negative values가 억압되도록 activated되고 최종 CAM은 original CAM의 normalized similarities로 weighted된 sum이 된다.
Fig. 3이 PCM 구조를 보여준다.

PCM과 self attention이 다른점
1.
PCM은 residual connection을 제거해 original CAM과 같은 activation intensity를 유지했다.
2.
다른 브랜치가 PCM에 GT만큼 정확하지 않은 pixel-level supervsion을 제공하기 때문에 와 임베딩을 없애서 부정확한 supervision에 대한 overfitting을 막았다.
3.
ReLU activation과 L1 normalization을 통해 상관없는 픽셀들을 제거하고 연관성 있는 영역에서 더 부드러운 affinity attention map을 생성했다.
Loss Design of SEAM
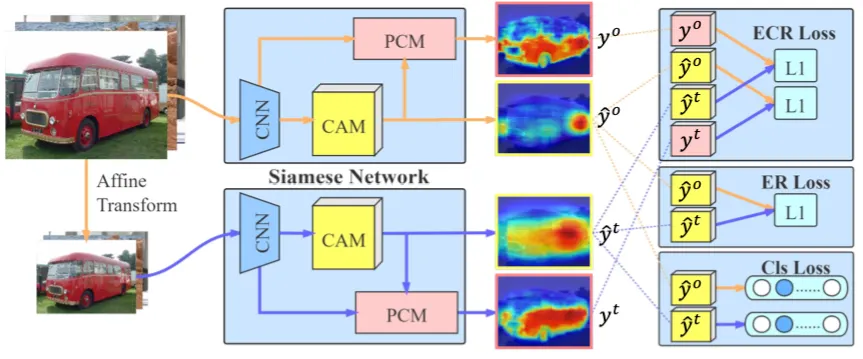
Image level classification label 만이 유일하게 사용 가능한 human-annotated supervision 이기 떄문에 네트워크 마지막 단에 global average pooling으로 prediction vector 를 얻어냈다. 그리고 학습 과정에서 multi-label soft margin loss 를 적용했다.
C-1개의 foreground object에 대한 classification loss

: original image의 CAM (PCM거치지않음)→GAP→
: transformed image의 CAM (PCM거치지않음) → GAP →
두 브랜치에서 classification loss

⇒ 이 classification loss는 object localization을 위한 learning supervision을 제공한다 ( CAM을 통해 pseudo label을 생성하니까 )
origianl CAM에 equivariant regularization 적용을 위한 Equivariant regularization loss ( ER Loss )
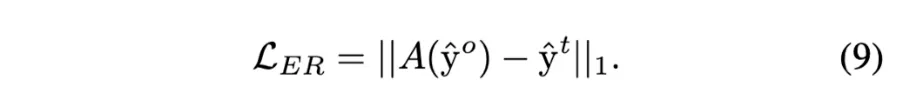
즉 앞에서 설명이 나왔듯 original input의 output을 transform 한 것과 transformed input의 output이 최대한 같도록 만드는 것.
또한 equivariance learning을 향상시키기 위해 shallow layers의 feature와 original CAM이 PCM 모듈로 들어간다 → 원초적 아이디어는 와 를 유사하게 만드는 것인데 PCM 이 모든 픽셀을 하나의 클래스로 예측하는 local minimum에 잘 빠진다는 것을 실험을 통해 알게 되었다.
이를 방지하기 위한 equivariant cross regularization loss ( ECR Loss )

PCM을 거친 original CAM과 PCM 거치지 않은 transformed image의 CAM의 차이
+
PCM 거치지 않은 original CAM과 PCM 거친 transformed image의 CAM의 차이
즉 다른 브랜치에서 나온 original CAM으로 regularized된다.
⇒ 이는 PCM refinement에서의 CAM degeneration을 피한다.
CAM들이 foreground object classification loss로 학습된다 해도 BG pixel들이 매우 많고, 이는 PCM도중에도 무시되지 않는다. original foreground CAMs는 이 background positions에서 zero vectors를 가지고 있고 gradients를 생성하지 않는다. 그래서 그 background pixels간의 feature representation을 유사하게 만들수가 없다. 그래서
이를 해결하기 위한 background score 설계
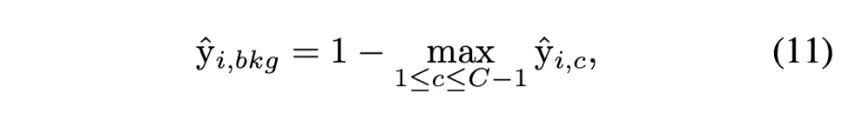
: original CAM의 클래스에 대한 position 에서의 score
각 픽셀의 activation vectors를 foreground non-maximum activations를 0으로 만들고 추가적인 background score를 concatenate 하는 방법으로 normalize한다.
⇒ foreground class에서 최댓값이 아닌 vector (background로 분류된 픽셀에서의 vector)를 0으로 만든 후 여기서 설계한 background score로 대체해준다는 말인 듯 하다!
inference 시에 foreground activations만을 유지하고 background score를 로 세팅해준다. 는 hard threshold parameter이다.
최종 loss는 다음과 같다. ( 모든 Loss term들의 합 )

정리
classification loss : roughly localize objects
ER Loss : narrow the gaps between pixel and image level supervisions
ECR Loss : integrate PCM with trunk of the network → make consistent predictions over various affine transforms
Experiments
Implementation Details
PASCAL VOC 2012 → 21 class annotations (20 foregrounds and background)
1464 training 1449 validation 1456 test
보통의 semantic segmentation protocol을 따름
SBD로부터 추가적인 annotations를 채택해 augmented training set 10582개를 빌드했다
네트워크 학습시에는 image-level labels만을 사용했고 mIOU가 평가 지표로 사용됐다.
ResNet38이 backbone network로 채택되었으며 output_stride=8이었다. ( output feature map 의 H, W가 input의 1/8)
stage 3과 stage 4에서 feature map을 추출하였으며 채널 수를 64와 128로 각각의 1x1 conv로 줄였다.
PCM에서는 이 피쳐들이 concatenated되고 function 로 들어간다. ( 1x1 conv )
이미지들은 긴쪽이 [448, 768] 범위가 되도록 rescaled 되었고 448 x 448로 randomly crop되었다.
TITAN-Xp GPU로 학습되었고 batch size는 8 epoch는 8이었다.
첫 lr은 0.01이고 poly policy를 따라서 로 스케줄링되었다.
ECR Loss에 Online hard example mining(OHEM)이 적용되었으며 최대 20% pixels losses를 남겼다.
학습동안에 gradients를 PCM stream과 trunk of network의 intersection point에서 잘라서 mutual interference를 방지했다.
이 세팅은 PCM을 퓨어한 context refinement module로 단순화했고 backbone네트워크와 동시에 학습이 될 수 있도록 했다.
→ original CAMs의 학습은 PCM refinement 과정에 의해 영향을 받지 않았다
inference 시에는 SEAM이 shared-weight siamese network이기 떄문에 하나의 branch만 restored되었고 pseudo segmentation labels를 생성해 multi-scale and flip test 를 수행하였다.