
Deeplab은 세그멘테이션(segmentation) 문제를 해결하기 위한 딥러닝 기반 모델 중 하나로, 이미지에서 각 픽셀을 해당하는 객체 또는 배경으로 분류하는 작업을 수행합니다. 이 모델은 컴퓨터 비전 분야에서 주로 활용되며, segmentation, object detection, video detection 등의 응용에 사용될 수 있습니다.
Deeplab 모델은 초기 버전부터 여러 발전을 거쳐 왔으며, 아래는 주요 발전 단계와 각 모델에 대한 간단한 설명입니다:
이 글에서는 Deeplab계열의 모델에 대해서 전체적인 발전 과정을 살펴보고 간단히 정리합니다.
1.
Deeplab v1:
Deeplab의 초기 버전으로, 2014년에 소개되었습니다. 이 모델은 기본적인 Convolutional Neural Network (CNN) 구조를 활용하며, atrous convolution(또는 dilated convolution)을 도입하여 입력 이미지의 다양한 scale에서 정보를 추출하도록 했습니다. 이는 객체 경계를 잘 인식하는데 도움이 되었습니다.
2.
Deeplab v2:
2016년에 발표된 Deeplab v2는 ASPP (Atrous Spatial Pyramid Pooling) 레이어를 사용하여 다양한 스케일의 정보를 효과적으로 수집하고, 이미지에 존재하는 다양한 객체의 크기에 더 잘 대응할 수 있도록 하였습니다.
3.
Deeplab v3:
Deeplab v3는 2017년에 발표되었으며, ResNet 아키텍쳐에 발전된 ASPP (Atrous Spatial Pyramid Pooling) 레이어를 도입하여 객체 경계를 더 잘 인식할 수 있도록 개선하였습니다.
4.
Deeplab v3+:
Deeplab v3+는 2018년에 소개된 모델로, Encoder-Decoder 구조를 채택하여 이전 버전보다 더 정확한 세그멘테이션을 가능하게 했습니다. Depthwise separable convolution과 skip connection 등을 사용하여 더욱 정교한 segmentation을 수행하며, 성능과 속도 면에서 좋은 결과를 얻을 수 있습니다.
Deeplab v1
deep convolutional neural network (DCNN)을 semantic segmentation에 적용하고자 했습니다.
이 당시 DCNN들은 classification에 초점이 맞추어져 있었기 때문에 고려해야하는 점이 몇가지 있었습니다.
•
다양한 크기의 객체를 인식하기 어려움
•
피쳐맵 해상도가 점점 줄어드는 형태라서 localization accuracy가 감소함
◦
spatial information의 손실
⇒ max-pooling을 줄이고 atrous convolution (Dialted convolution)를 사용하여 효율적으로 넓은 공간을 탐색합니다. (receptive field를 확장시킴)

위 그림과 같이 atrous convolution은 downsampling + convolution + upsampling보다 더 효율적으로 넓은 receptive 영역에서 features를 추출해냅니다.
후처리로 Dense Convolutional Random Field를 적용합니다.
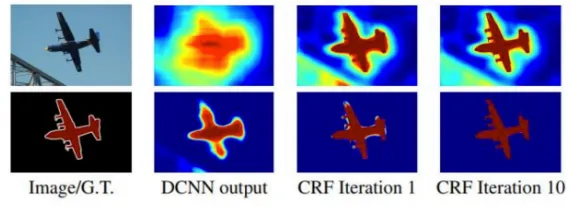
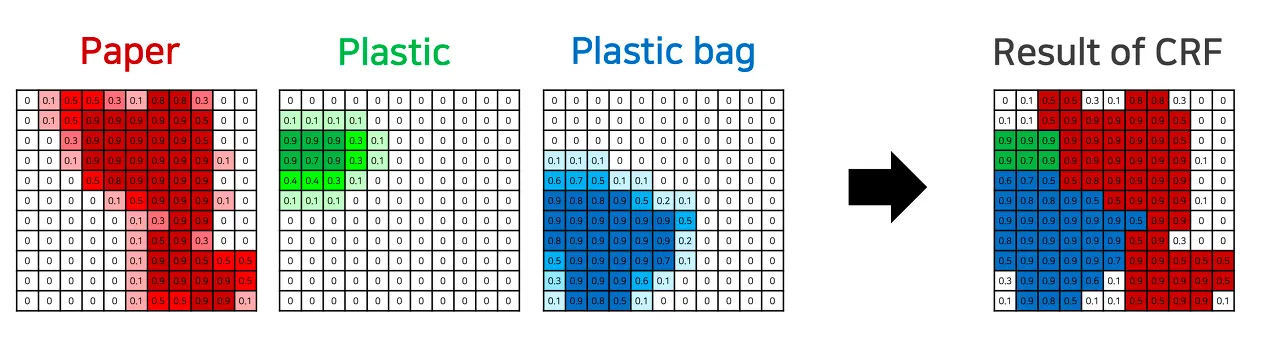
이 글은 deeplab계열 모델의 전체적인 발전을 살펴보는 것이 목적이므로 dense CRF에 대한 설명은 생략하고 설명이 잘 되어있는 링크를 남깁니다.


Deeplab v2
Deeplab v2도 v1과 거의 유사합니다.
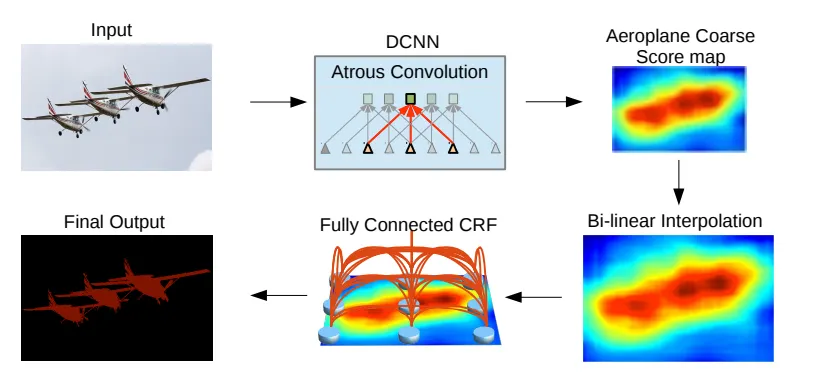
atrous convolution을 적용한 DCNN으로 score map을 예측하고 bilinear로 키운 score map을 CRF를 통해 디테일을 살려냅니다.
Deeplab v1과의 차이는 ASPP 모듈의 사용입니다.
Atrous Spatial Pyramid Pooling
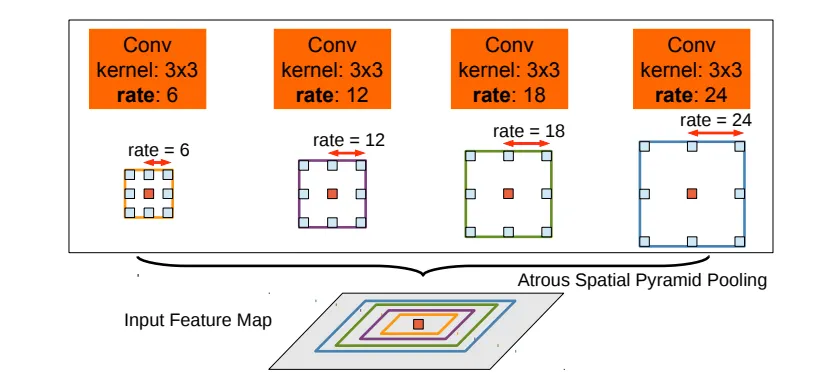
위 그림은 주황색 픽셀을 분류하기 위해서 4개의 다양한 dilation rate를 적용한 convolution을 사용한다는 내용입니다. 다양한 receptive field에서의 피쳐를 추출함으로써 주변 context를 더 잘 고려하게 되겠죠? 이를 구체적으로 어떻게 적용한 것인지 밑의 figure를 보면 알 수 있습니다.
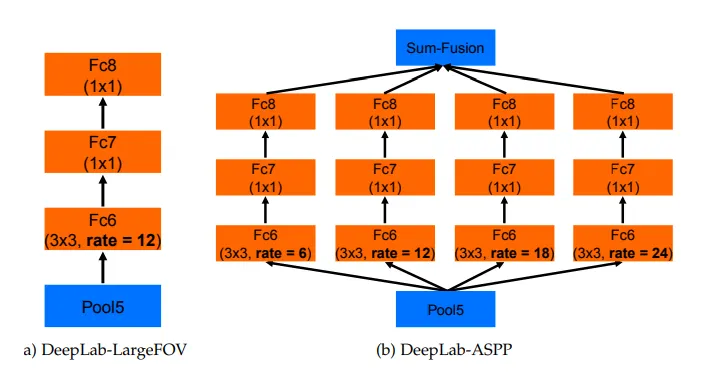
여기서 a는 Deeplab v1의 구조인데요, VGG16의 pool5 뒤에 dilation rate 12의 3x3 convolution을 적용하고 1x1 convolution으로 classification을 수행했습니다.
반면 b의 경우 Deeplab v2의 구조로, pool5 이후에 a와 같은 과정을 dilation rate 6, 12, 18, 24로 개별적으로 수행한 후 모두 sum을 해줍니다.
이는 multi scale의 객체들에 더 잘 대응하게 해줍니다.
그러나 diation rate가 커지면 유혀한 weight ( zero padding이 아닌 실제로 feature 영역과 연산되는 weight)가 줄어든다는 단점이 있습니다.
Deeplab v3
Deeplab v3에서는 ImageNet pretrained ResNet backbone을 backbone으로 적용하고 block 4의 뒤에 ASPP를 추가합니다.
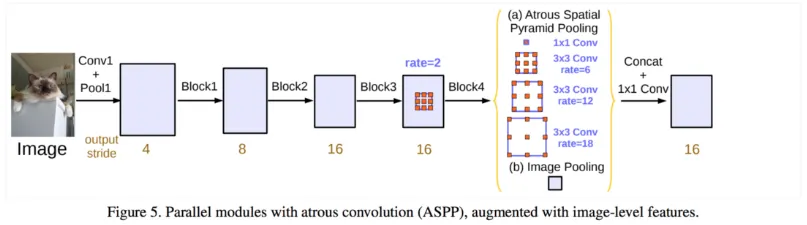
자세히 보면 Deeplab v2와 ASPP의 구성이 조금 다릅니다. dilation rate 6, 12, 18의 convolution과 global max pooling을 적용해 이것들을 sum fusion이 아닌 concatenate합니다. sum보다 더 풍부한 정보를 사용할 수 있겠지만 연산량이 증가했겠네요. 이후 1x1 convolution으로 classification을 진행하는 것은 동일합니다.
밑의 output stride는 input size의 output size에 대한 비율입니다.
output stride가 작을 수록 segmentation이 정교하겠지만 연산량이 매우 많아집니다.
추가적으로 Deeplab v2에서는 ASPP의 convolution 이후에 batch normalization 이 수행되지 않았는데 Deeplab v3에서는 batch normalization이 추가되었습니다.
Deeplab v3 +
Deeplab v3 + 에서는 v3에 depthwise separable convolution을 추가하고, ASPP를 발전시켰으며 CRF 후처리를 사용하지 않았습니다.
encoder-decoder architecture

지금까지는 (a)처럼 encoder에서 점진적으로 resolution이 작아지고, ASPP를 적용한 score map을 upsampling하는 방식을 사용했는데요, 이 과정에 문제가 있다고 판단했습니다. 실제로 upsampling으로 인해 발생하는 모호한 경계문제를 DenseCRF 후처리로 처리해오기도 했고요. DenseCRF는 시간이 오래 걸리는 단점도 있습니다.
따라서 (b)와 같이 decoding 과정에서도 점진적으로 upsample해가는 방식을 택했습니다.
밑의 그림이 더 자세히 설명해줍니다.

•
encoder에서 최종 feature map을 4배 upsample
•
encoder 중간 feature map을 1x1 conv를 통해 채널 수 축소
•
위의 두 feature map을 concatenate
•
concatenated features에 3x3 conv + 1x1 conv를 적용해 output을 생성
•
마지막으로 4배 bilinear upsampling을 수행해 원래 input size와 동일하게 만들어 준다.
다양한 backbone network
Deeplab v3에서는 Xception과 ResNet-101을 backbone으로 사용했습니다. Xception에서 조금 더 나은 성능이 나왔는데, Xception에서는 Atrous separable convolution 적용을 위해 모든 pooling을 depthwise separable sonvolution으로 대체했습니다.
