prototypical network 를 기반으로 한다.
Prototypical Network란
N-way-K-shot
Parametric method
Abstract
semamtic segmentation의 문제점인 1. 많은 annotated images 필요 2. unseen data에 대한 어려움 두가지를 few shot learning을 통해 해결하고자 함.
이를 metric learning 관점으로 접근해 PANet을 제안한다.
PANet은 few support images에서 class-specific prototype representations를 학습한다 → 어떤 embedding space에서
그리고 query images에 대해 segmentation을 수행한다. → 각 픽셀을 학습된 prototypes에 매칭시킴.
non-parametric metric learning을 통해 PANet은 높은 수준의 prototypes를 제공한다. 이 prototypes는 각 semantic class를 대표할만하고 다른 클래스별로 구별도 잘 된다.
또한 support와 query사이에 prototype alignment regularization을 제안한다. 이를 통해 PANetdms support set에서의 지식을 완전히 이용하고 더 나은 일반화 성능을 제공한다.
PASCAL- 에서 1-shot : 48.1%, 5-shot: 55.7% 의 mIOU를 달성. 이는 SOTA보다 높은 수치임.
Introduction
딥러닝은 semantic segmentation을 매우 발전시켰고 다양한 CNN모델들이 나왔다. 그러나 large data가 필요하다는 문제가 있었고 이를 semi-supervised 방식이나 weakly-supervised 방식으로 해결하고자 했음. 그래도 데이터가 많이 필요했다. 거기에 unseen data에 대한 일반화 성능이 부족한 문제도 존재했다. 이를 few-shot learning으로 해결해보고자 한다. 기존 few-shot learning들은 classification연구에 치중되어 있었다.
기존 few-shot semantic segmentation 방버들은 보통 이용하기 쉬운 support images를 학습하고 그렇게 학습된 knowledge를 parametric module에 query를 segmentation하기 위해 parametric module에 전달해주었다.
그러나 이 방식은 두가지 단점으로 인해 일반화 성능이 떨어졌다.
1.
knowledge extraction과 segmentation 과정을 구분하지 않았다. → semantic segmentation model representation이 support의 semantic features와 섞이기 때문에 문제가 될 수 있다.
⇒ 두 파트를 1. prototype extraction과 2. non-parametric metric learning으로 나누는 것을 제안한다.
prototypes는 각 클래스에 대해서 간결하고 robust하게 최적화가 되고, non-parametric metric learning은 embedding space에서 pixel-level matching을 통해 segmentation을 수행한다.
2.
support의 annotation을 masking에만 사용한다
⇒ few-shot learning process에서도 사용할 것을 제안한다.
이 목적을 위해 반대 방향으로 few-shot segmentation을 수행함으로써 새로운 prototype alignment regularization 을 제안했다.
 이말은 즉 query image와 그를 예측한 mask가 새로운 support set으로 여겨지고 이것이 이전의 support images를 segment하기 위해 사용된다는 것이다.
이말은 즉 query image와 그를 예측한 mask가 새로운 support set으로 여겨지고 이것이 이전의 support images를 segment하기 위해 사용된다는 것이다.이를 통해 모델은 support와 query 사이에 더 consistent한 prototypes를 생성하게 된다. (cycleGAN의 모티브와 유사하다고 생각됐다.)
이는 더 나은 일반화 성능을 제공한다.
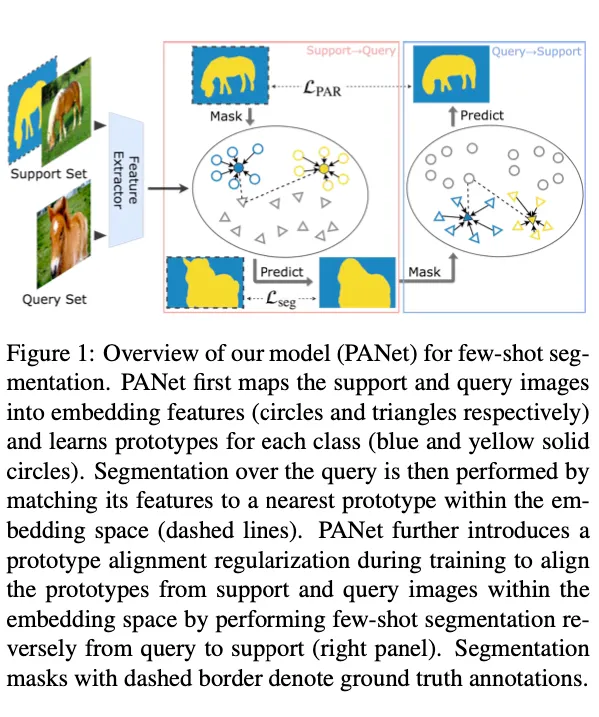
Fig. 1은 PANet의 전체적인 흐름을 나타낸다.
PANet은 1. foreground와 background를 각각 다른 prototypes로 임베딩한다. 이 때 각각의 학습된 prototype은 각 해당 클래스에 대하여 대표할 수 있으며 다른 클래스와 구분이 가능하다. 2. query의 각 픽셀은 embedding representation에서 가장 가까운 class-specific prototype으로 라벨링된다.
실험 결과 하나의 support set( 1-shot ) 에서도 좋은 성능을 보였다고 한다.
그림의 Query→Support가 prototype alignment regularization이라 할 수 있겠다. query image와 그에 해당하는 예측 mask로 새로운 support set을 생성한다. 그리고 original support set에 대해 segmentation을 수행한다. → Query에서 생성되는 prototypes와 Support에서 생성되는 prototypes가 정렬되도록 한다
training시에만 regularize가 적용된다는 것을 명심해야한다. query images는 testing images와 헷갈려서는 안된다는 것도 명심해야 한다.
feature extractor는 그 어떠한 fullyt convlution network를 사용해도 된다. 또한 bounding box나 scribbles같은 약한 annotation으로도 학습이 잘 됐다고 한다.
contributions
•
prototypes를 사용해 metric learning을 사용하고, 이는 parametric classification 아키텍쳐를 사용하는 기존 연구들과 다른 점이다.
•
새로운 prototype alignment regularization을 제안하며 이는 few-shot learning을 향상시키기 위해 support knowledge를 완전히 활용한다.
•
few examples with weak annotations에 바로 적용이 가능하다.
•
SOTA보다 높은 성능을 달성했다.
3. Method
3.1. Problem setting
few annotated images로 같은 클래스 의 이미지들에서 segmentation을 수행하는 것을 빠르게 학습할 수 있는 모델을 제안하는 것이 목표였다.
https://arxiv.org/pdf/1709.03410.pdf 와 training / test protocol을 똑같이 적용했다고 한다.
이 논문에서 사용한 데이터 구성은 다음과 같다.
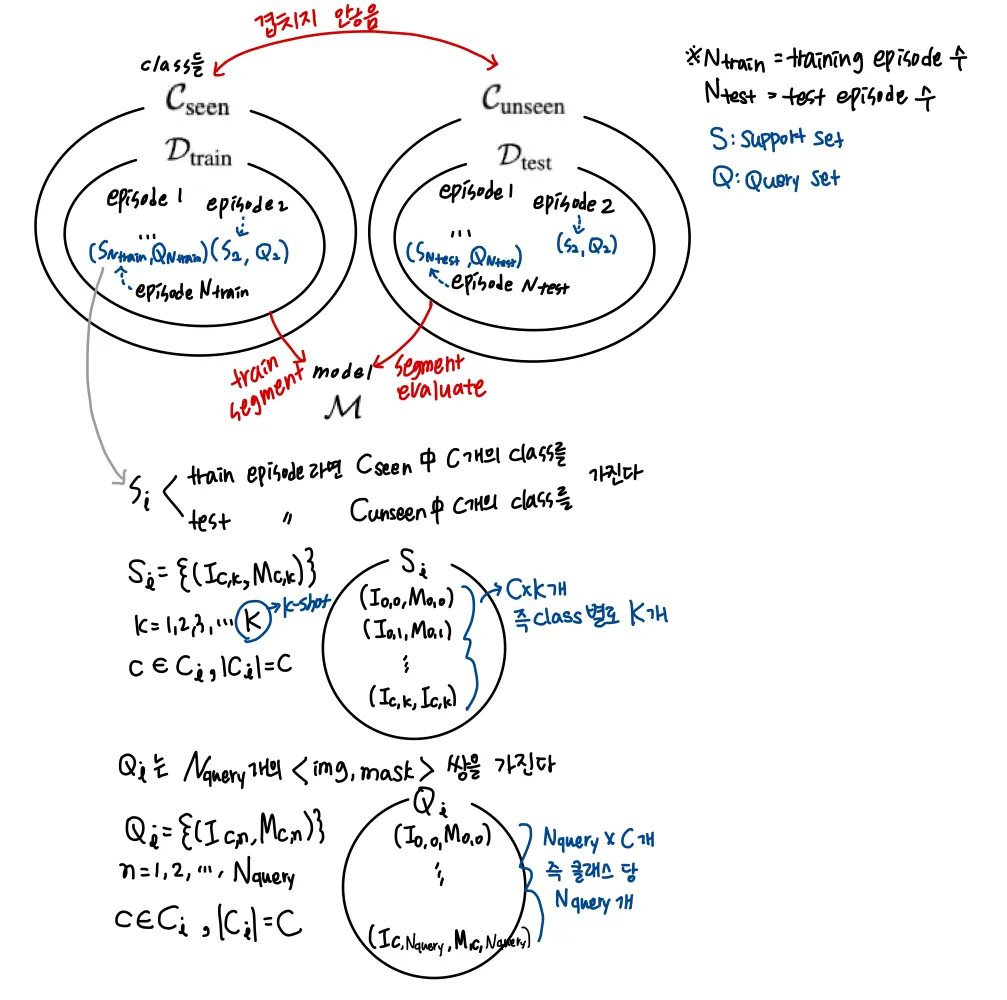
모델은 먼저 support set의 C개의 클래스에 대해서 knowledge를 추출하고 그렇게 학습된 knowledge를 적용해 query set에서 segmentation을 수행한다.
각 episode는 다른 semantic classes를 가지기에 모델은 잘 일반화하도록 학습된다.
training set 으로부터 segmentation model 이 얻어지면 에서 모든 episodes에 대해 few-shot segmentation을 평가한다. ⇒ 주어진 support set 가 주어진 query set 에 대해 평가함.
3.2. Method overview
기존 방식 : 추출된 support features와 query features를 parametric way로 퓨전시켜서 segmentation을 수행함.
PANet: embedding space에 각 클래스에 대한 compact and robust prototype representation을 정렬 및 학습
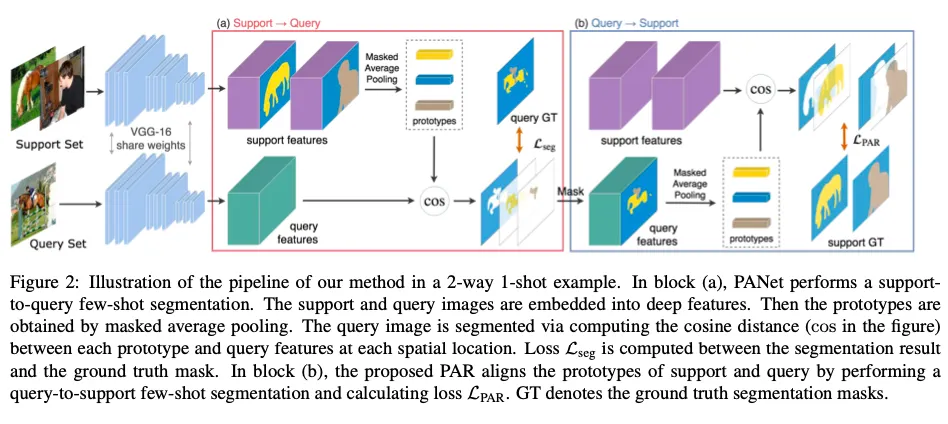
Fig. 2:
각 에피소드에서 support , query images를 deep features로 임베딩한다. 이는 shared VGG16 network로 수행된다. 이후 masked average pooling을 수행하면 그것이 prototype이 된다. prototype은 support images에 대해서만 생성된다. query에서는 deep features만 뽑는다.
Query images에 대한 segmentation은 각 픽셀을 가장 가까운 prototype의 클래스로 라벨링하는 것으로 수행된다.
새롭게 제안하는 prototype alignment regularization(PAR)은 모델이 support 와 query에 대해서 consistent embedding prototypes를 학습할 수 있도록 해주는 역할이다. 추가적인 파라미터는 피룡하지 않다.
⇒ 즉 PANet은 VGG16을 consistent embedding space를 찾을 수 있도록 end-to-end로 학습해 weights를 최적화시키는 것이다.
VGG16은 좀 변형해서 사용했다.
1.
첫 5개의 conv blocks는 유지함
2.
다른 conv blocks는 제거함
3.
maxpool4의 stride는 1로 설정해 large spatial resolution을 유지함
4.
conv5 block은 dilated conv with dilation set to 2로 대체함.
3.3. Prototype learning
masked average pooling : 전체 이미지에 대해 average하는게 아니라 support images의 mask annotations를 사용하는 것. 목적은 foreground와 background 각각에 대해서 prototypes를 학습시키기 위해서이다.
segmentation masks를 사용하는 방식은 두가지 전략이 있음
1.
Early fusion
: support images를 feature extractor에 feed하기 전에 mask한다.
2.
Late fusion
: feature extractor를 통해 추출된 feature에 바로 mask한다. 그를 통해 foreground/background 에 대해 각각의 features를 생성해낸다.
PANet은 late fusion strategy로 적용했다. → shared feature extractor의 input consistency를 지키기 위해서다 ( support set이든 query set이든 이미지만 넣는 것이 feature extractor의 작동이 잘 되도록 할 수 있음 )
support set의 class c에 대한 k번째 이미지 는 shared feature extractor의 입력으로 들어가 feature map output 를 출력한다. 그로부터 class c에 대한 prototype을 masked average pooling으로 생성한다. 이에 대한 식이 (1)이다.
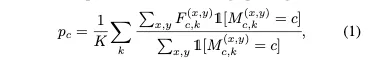
이 식을 설명하면, ground truth가 c인 영역의 feature map 값들의 합을 ground truth가 c인 영역의 픽셀 수로 나누고 ( 평균을 내는 것 ) 이를 K개의 이미지에 대해 수행하여 합한 후 K로 나누어 평균을 내준다.
추가적으로 어떠한 클래스에도 속하지 않는 영역에 대해서 background라고 생각하고 background에 대한 prototype은 다음과 같이 계산했다.
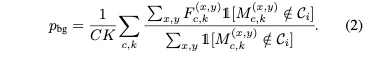
이 prototypes는 end-to-end로 최적화된다.
3.4. Non-parametric metric learning
최적의 prototypes를 학습해 segmentation을 잘 수행하기 위해 non-parametric metric learning방식을 적용했다.
segmentation 은 각 픽셀마다의 classification으로 볼 수 있다. 그래서 각 픽셀 위치의 query feature vector와 prototype간의 거리를 계산한다. 그리고 이 거리들에 대해서 softmax를 적용해 class들에 대한 probability map () 를 생성한다. (background를 포함하는 클래스들)
: distance function (논문에서는 cosine distance에 factor를 곱한 것으로 사용했다. squared Euclidean distance보다 성능이 더 좋았다고 한다.)
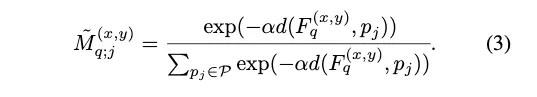
이 식을 자세히 설명하면,
•
즉, 각 클래스와 background에 대한 프로토타입들과 query image를 shared feature extractor에 통과시켜 얻은 피쳐맵의 픽셀별 피쳐 ( 각 픽셀당 채널 성분 )간의 거리를 계산한다.
•
예를 들어 클래스가 2개 + bg class라고 하면,
◦
과 피쳐맵 각 픽셀 성분들 사이 거리
◦
과 피쳐맵 각 픽셀 성분들 사이 거리
◦
과 피쳐맵 각 픽셀 성분들 사이 거리
이렇게 세개의 거리를 계산하고, 이 거리들에 대해서 softmax를 수행해 유사 확률로 0~1 사이 값으로 만들어 줍니다.
•
따라서 결과물은 semantic segmentation model의 output처럼 input의 해상도를 갖는 class 개수만큼의 채널의 map이 됩니다. 각 채널은 각 클래스에 대한 해당 픽셀의 score값을 갖게 됩니다.
•
그리고 그를 argmax를 적용해주면 최종 예측 segmentation mask가 됩니다.
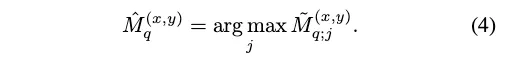
Loss function
loss fuction은 다음과 같다.
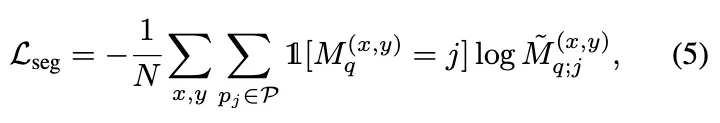
: ground truth segmentation mask
: predicted truth segmentation mask
: total number of spatial locations
→ GT에서 j class인 영역에 대해서 score의 -log값을 sum한 후 N으로 나눠줌 ( cross entropy )
Prototype alignment regularization (PAR)
이전 연구들에서 support annotation은 오직 masking에만 쓰였다. few-shot learning에 적합하게 쓰이지 않은 것이다. 이를 더 잘 이용하고 few-shot learning을 더 잘 가이드하여 일반화 능력을 향상시키기 위해 제안하는 것이 PAR이다.
직관적인 아이디어는
모델이 support set에서 추출된 prototype들로 segmentation이 잘 됐다면 query set에서 학습된 prototypes로도 support images를 잘 segmentation할 것이다.그래서 PAR은 few-shot learning을 반대 방향으로 수행하는 것이다. query와 예측 mask를 새로운 support set으로 여기고 support images를 segment하는 것을 학습하는 것.
⇒ 이는 support 와 query 의 prototypes간의 상호적인 정렬을 시켜주고 support로부터 더 풍부한 지식을 학습하게 된다.
그리고 당연하게도 이는 training시에만 적용된다. Fig.2 에 잘 나타나있다.
예측 segmentation mask 생성까지 앞에서의 원래 학습 과정과 동일하다. support set과 query set만 바뀌었을 뿐.
여기서 예측된 segmentation mask와 ground truth segmentation mask를 비교해 PAR Loss를 연산한다.
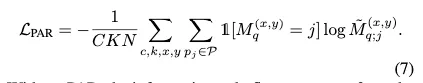
PAR이 없으면 정보가 오직 support set → query set으로만 흐르기 대문에 반대방향으로도 흘려주어서 모델이 consistent embedding space를 갖도록 해준다. query와 support의 prototypes가 정렬되는 효과가 있다. 이에 대한 실험도 수행하였다
total loss
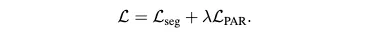
( = 1 )
3.6. Generalization to weaker annotations
PANet은 일반적이고 다른 annotation types에 바로 적용이 가능하다.
weaker annotations를 support set에 적용 (scribbles / bounding box ) 하였을 때 실험 결과 여전히 robust prototypes를 추출했다. 그리고 query images에 대해서 segmentation 결과가 잘 나왔다.
Experiments
•
dataset : PASCAL-5i (created from PASCAL VOC 2012 with SBD augmentationd)
◦
20 categories → 5 categories( 4분할됨 )
◦
모델은 3개의 split에서 학습하고 나머지 하나의 split에서 평가됨 ( cross validation )
•
evaluation metrics : mIOU
•
implementation details
◦
VGG16은 ILSVRC에서 pretrained된 weights로 초기화됨.
◦
input image는 (417, 417)로 resize됨.
◦
random horizontal flipping augmentation이 수행됨
◦
SGD oprimizer로 momentum은 0.9 사용, 30000iteration 학습
◦
초기 lr은 1e-3, 10000 iterations마다 0.1배 줄어듬.
◦
weight decay 0.0005, batch size 1
[1-shot과 5-shot 학습에서의 SOTA모델과의 비교]
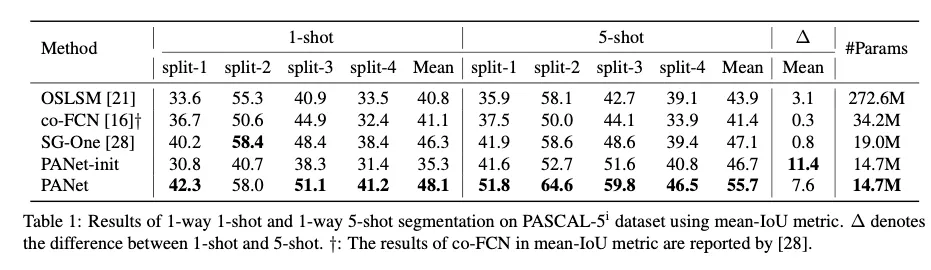
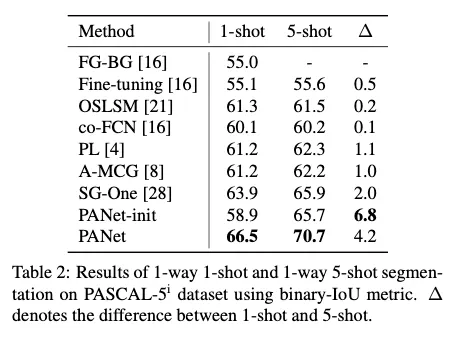
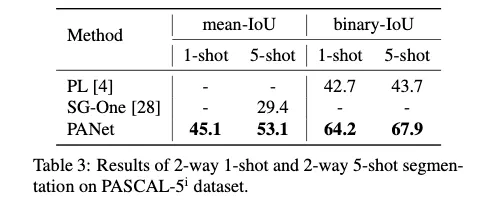
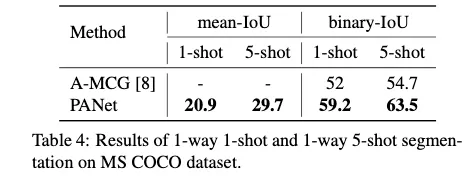
[성능 시각화]


[PAR 에 대한 ablation study, weaker annotation 실험]