
input image / feature / network perturbation을 활용한 consistency learning이 semi-supervised semantic segmentation에서 좋은 성능을 보였으나 이 논문에서는 다음과 같은 문제를 제기한다.
•
cross entropy loss는 overfit이 잘 되므로 confirmation bias(확증편향)을 가질 수 있다. ( loss를 줄이기 위해 다 같은 클래스로 예측하는 등의 문제 )
•
이 불확실한 예측에 적용된 perturbations는 잘못된 예측을 이용해 학습을 진행하게 되어 (잘못된 pseudo label 사용) consistency learning의 성능을 하락시킨다.
이 문제의 해결을 위해 PS-MT에서는
1.
mean teacher 기법 사용 : 보조 teacher를 사용하며 기존에 mean teacher (MT) 기법에서 사용되던 MSE Loss를 confidence weighted cross entropy loss (Conf-CE) 로 대체
⇒ input image, feature, network perturbation 들을 결합해 더 어려운 perturbation을 사용할 수 있게 되었고 이는 consistency learning의 일반화 성능을 향상시켰다.
2.
새로운 형식의 adversarial feature perturbation을 제안하여 student model 에 적용되는 perturbation을 virtual adversarial training from teachers ( T-VAT )를 통해 학습했다.
[전체 모델 흐름도]

combination of input dat, feature and network perturbations
network perturbation
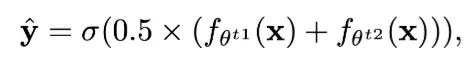
위 식과 같이 teacher model 두개의 평균을 예측값으로 사용함으로써 수행 ( : softmax function)
feature perturbation
T-VAT를 통해 수행
input image perturbation
weak-strong augmentatino pairs에 기반.
weak augmentations ( image flipping, cropping and scaling)이 teacher models에 의해 처리되는 이미지들에 수행되고
strong augmentations(colour jitter, randomise grayscle and blur)가 student model에 수행된다.
⇒ 일반화 성능 향상
stroing augmentation에서는 CutMix와 Zoom In/ Out도 활용했는데
CutMix에서는 teacher이 생성한 pseudo label의 artifacts를 포함하지 않기 위해 cutmix 대상인 각각 이미지를 teacher로 예측해 그 결과를 cutmix하는 방식으로 pseudo label을 생성한다.
Conf-CE Loss
전체 Loss 식


Conf-CE 식
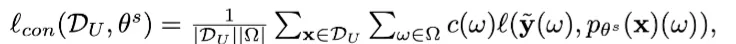
labeled data에 대해서 일반 CE Loss 적용하고 unlabeled data에 대해서 Conf-CE Loss 를 적용한 것이다.
는 onehot 처리 된 teacher의 예측 결과 ( pseudo label )이다.
식을 보면 CE Loss에 가 추가된 것이므로 가 핵심이라고 볼 수 있다.
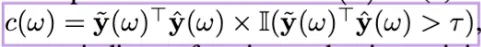
보면 는 bold체가 아니다. 즉, 스칼라값이라는 이야기 이다. 그래서 다음과 같이 연산된다.

위와 같이 연산된 값이 값 이하라면 0이 되는 것이다. (loss에 반영되지 않음)
일반적인 teacher-student 방식과 같이 student만이 이 loss들을 통해 업데이트되고 teacher들은 EMA를 통해 업데이트 된다.
T-VAT
T-VAT는 student의 예측을 다음과 같이 사용함으로써 이루어진다.

encoder의 output에 라는 feature perturbation을 주는 것이다
는 다음과 같이 teacher models의 앙상블의 결과값으로 예측된다.
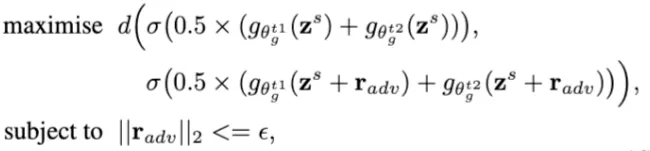
d() 함수는 pixelwise KL divergence의 합이기 때문에
•
teacher 1, 2의 decoder에 ( student model encoder output) 를 넣은 결과의 평균
•
teacher 1, 2의 decoder에 를 넣은 결과의 평균
둘 사이의 거리를 최대화하는 를 구한다.
즉 feature perturbation으로 인해 output이 많이 변해야 하는 것이다.
# r_adv 연산 코드
# from https://github.dev/yyliu01/PS-MT/tree/main : official code
def get_r_adv_t(x, decoder1, decoder2, it=1, xi=1e-1, eps=10.0):
# x는 student model 의 encoder의 output
# stop bn
decoder1.eval()
decoder2.eval()
x_detached = x.detach()
with torch.no_grad():
pred = F.softmax((decoder1(x_detached) + decoder2(x_detached))/2, dim=1)
# perturbation 없을 때 mean teacher output
d = torch.rand(x.shape).sub(0.5).to(x.device)
# [0, 1) 사이 값 갖는 정규분포에서 0.5를 빼서 [-0.5, 0.5) 값 갖는 정규분포 d 정의
d = _l2_normalize(d) # 이를 l2 normalize
# assist students to find the effective va-noise
for _ in range(it):
d.requires_grad_()
pred_hat = (decoder1(x_detached + xi * d) + decoder2(x_detached + xi * d))/2 # perturbation한 encoder output에 대한 mean teacher 결과
logp_hat = F.log_softmax(pred_hat, dim=1) # log softmax 적용
adv_distance = F.kl_div(logp_hat, pred, reduction='batchmean') # kl divergence Loss 연산
adv_distance.backward() # 역전파
d = _l2_normalize(d.grad) # d의 gradients를 l2 normalize 해줌
decoder1.zero_grad() # decoder는 업데이트 하지 않고 zero_grad로 초기화
decoder2.zero_grad()
r_adv = d * eps
# reopen bn, but freeze other params.
# https://discuss.pytorch.org/t/why-is-it-when-i-call-require-grad-false-on-all-my-params-my-weights-in-the-network-would-still-update/22126/16
decoder1.train()
decoder2.train()
return r_adv
Python
복사
Details
PASCAL VOC 2012, Cityscapes에서 실험하였으며
ImageNet pretrained backbone + DeepLabv3+ head를 사용하였다.
