
참고하면 좋을 곳

SRGAN에서 소개한 Loss이다.
VGG Loss라고도 함
VGG network의 high level feature maps와 discriminator를 결합한 새로운 perceptual loss
MAE, MSE
Mean Absolute Error, Mean Square Error
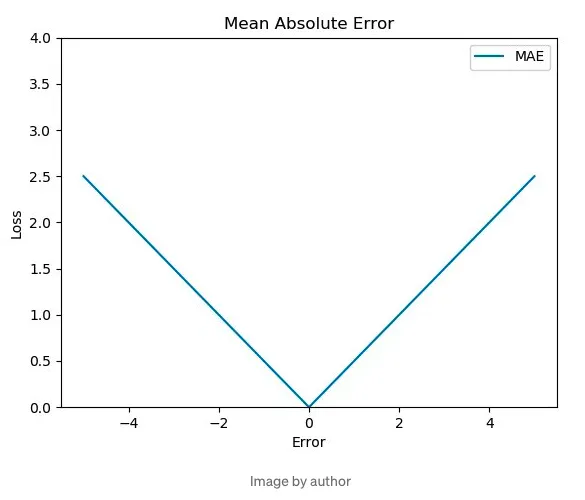
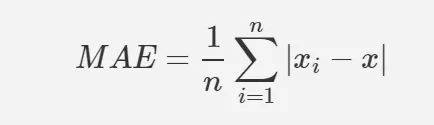
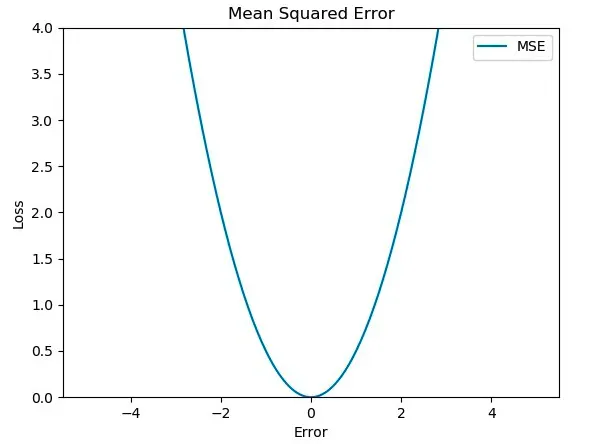
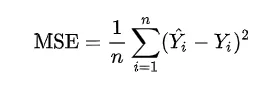
둘 다 평균에 기반한 error 함수이므로,
generator의 목표 : 실제 이미지에 가까운 이미지 만들어내기
그런데 MSE나 MAE같은 평균 기반 오차를 사용하게되면 실제같은 이미지 하나( a라고 하자 )를 만들어내기보다는 데이터의 평균 ( a + b + c+ d / 4 ) 정도를 크게 벗어나지 않는 이미지를 만들어내는 것을 목표로 하게된다. 그래서 매우 흐릿한 결과를 야기한다(high frequency값 부족). 대신 데이터들의 평균적인 형체를 반영하기 때문에 형체는 잘 보존이 된다.
그래서 GAN Loss 같은 경우에는 평균에 근접하지 않아도 되고, 그저 D에게 real data로 분류만 되면 되기 때문에 이러한 현상은 발생하지 않는다. 그러나 data들의 평균적인 형체(골격)은 반영하지 않기 때문에 data의 형체가 잘 보존되지 않을 수도 있다.
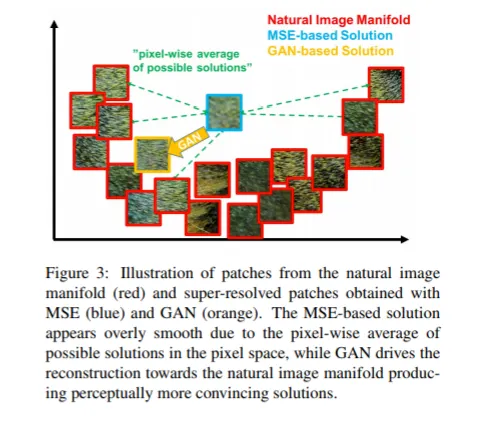
manifold
SRGAN의 task는 super resolution이기에,
목표는 low resolution input image → high resolution input : 변환이다
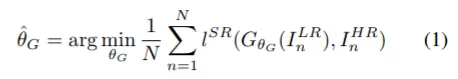
objective
이 이 SRGAN에서 제안하는 perceptual loss이다.

content loss는 feature map을 그대로 사용하고,
style loss 는 Gram matrix 연산을 한번 거쳐 Loss 를 계산
content loss
•
pixel-wise MSE loss
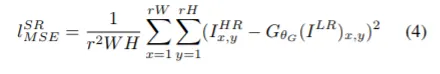
high PSNR(MSE와 역수관계)은 얻을 수 있으나, 너무 smooth되어 high frequency에서는 문제가 될수도
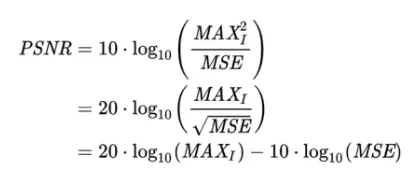
•
VGG Loss(based on ReLU activation layers of pre-trained 19 layer VGG Network)를 정의
이것이 SRGAN의 content loss가 된다.
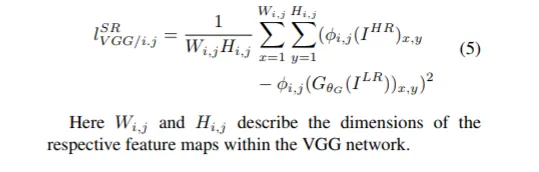
: VGG Network에서 i번째 maxpooling 레이어 이전에 j번째 convolution (after activaton)에서 얻어진 feature map
: 의 feature representation (VGG feature map) 의 euclidean distance
pretrained VGG_19 Net에서 i번째 maxpooling layer 전 activation(ReLU) 후 j번째 convolution에 의해 얻어진 featuremap 에서의 유클리디안 거리를 계산하는 것이다.
reconstructed image(G에 의해 생성된 이미지)와 reference image(정답 이미지)(high resolution image)의 feature map 사이 거리를 구하는 것
→ 각 픽셀값이 아닌 perceptual similarity에 집중 → detail에 더 집중 → edge 부분이 더 잘 살아남
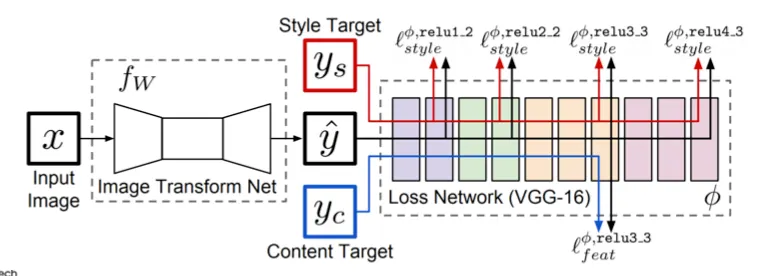
Loss Network
Adversarial loss function
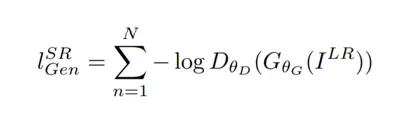
discriminator network를 속임으로써 natural image와 비슷하게 generating
보면 -log(D가 G가 생성한 이미지를 HR 이미지 즉 정답이미지로 구별할 확률) 이므로 real로 구분할 확률이 높을수록 낮은 loss 값이 나오겠다.
최종 perceptual loss
위에서의 vgg loss( content loss )와 adversarial loss를 더하면 perceptual loss가 된다.
보면 adversarial에는 이 곱해져 작게 반영된다

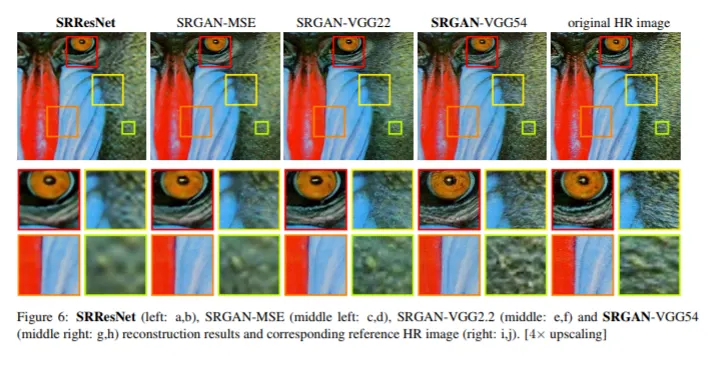
figure 6을 보면 vgg loss를 적용한 이미지가 더 선명하게 생성된다~~
