•
트라이는 문자열을 저장하고 효율적으로 탐색하기 위한 트리형태의 자료구조입니다.
•
자동완성 기능, 사전 검색 등 문자열 탐색에 특화되어있습니다.
유용한 경우 예시)
문자열 리스트가 주어졋을 때 “ap”로 시작하는 서로 다른 문자열의 수 구하기
# 주어진 문자열
words = ["app", "apple", "apply", "apart", "ban", "banana"]
# 찾고자 하는 문자열 (prefix)
target = "ap"
Python
복사
 반복문 사용할 경우 (시간복잡도 )
반복문 사용할 경우 (시간복잡도 )# 찾고자 하는 문자열의 길이
m = len(target)
cnt = 0
for word in words:
# prefix가 target과 일치하는 경우라면
# 수를 세어줍니다.
if word[:m] == target:
cnt += 1
print(cnt)
Python
복사
트라이를 사용하면 로 줄일 수 있습니다.
트라이는 다음과 같은 구조를 가진 트리입니다.
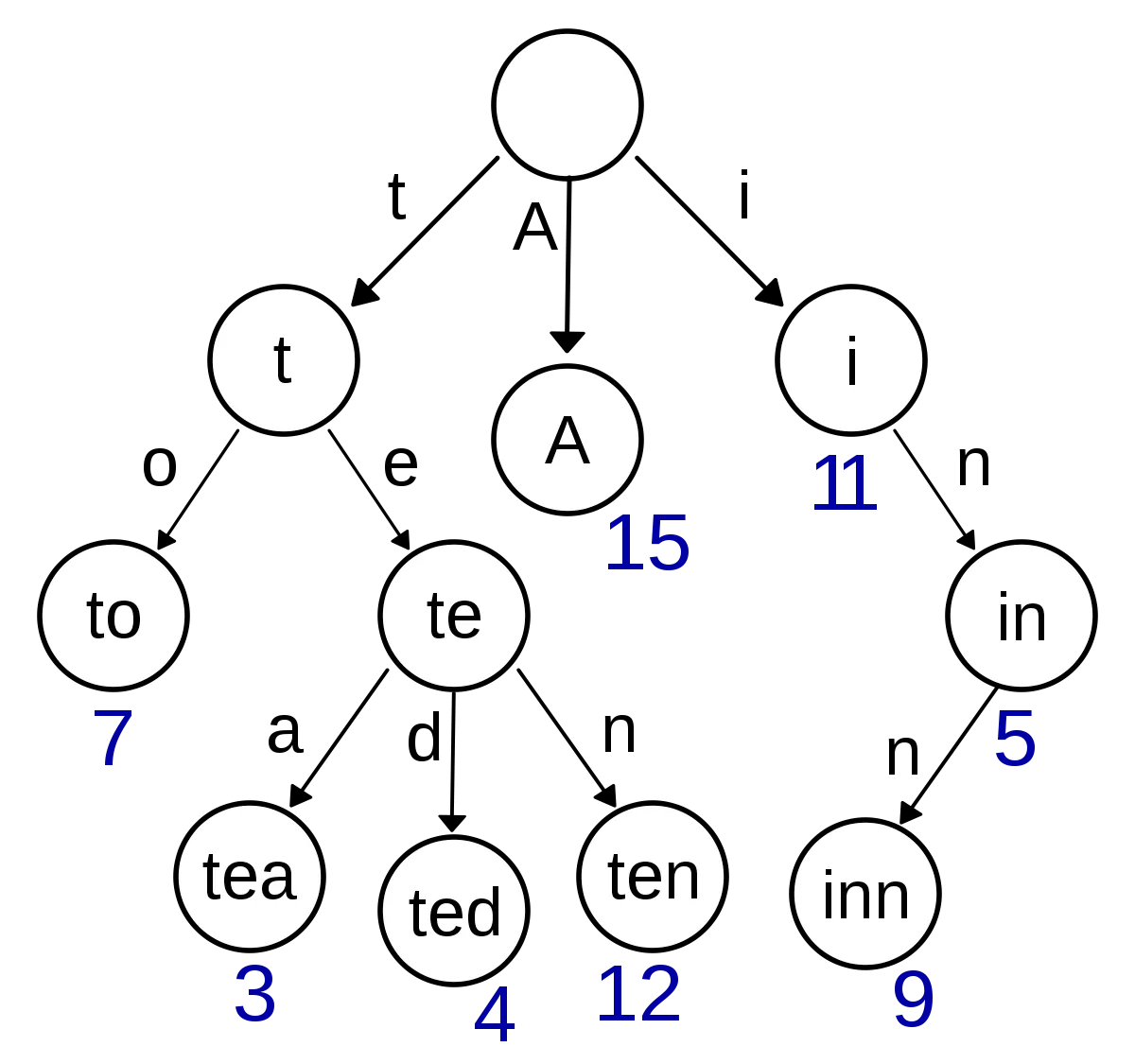
Root에서 시작하여 문자열 내 문자 순서대로 각 문자를 간선으로 하여 트리를 만들어나갑니다.
각 노드에 특정 문자열의 끝인지를 표시해두면 문제 풀이에 유용하게 사용할 수 있습니다.
ex) “app”과 “apple”을 순서대로 추가하였을 때
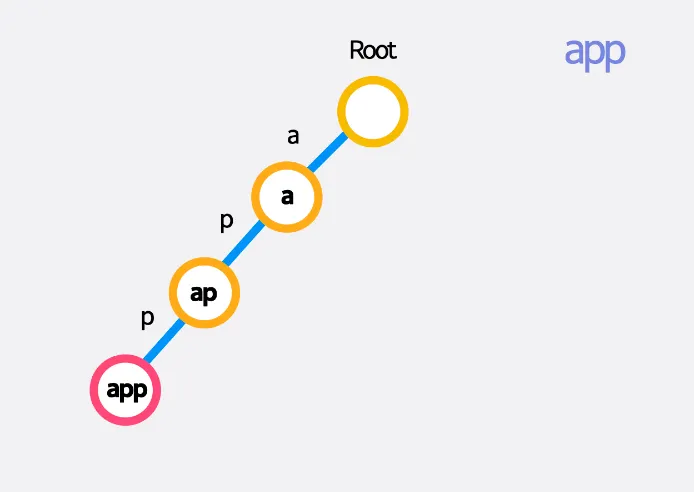
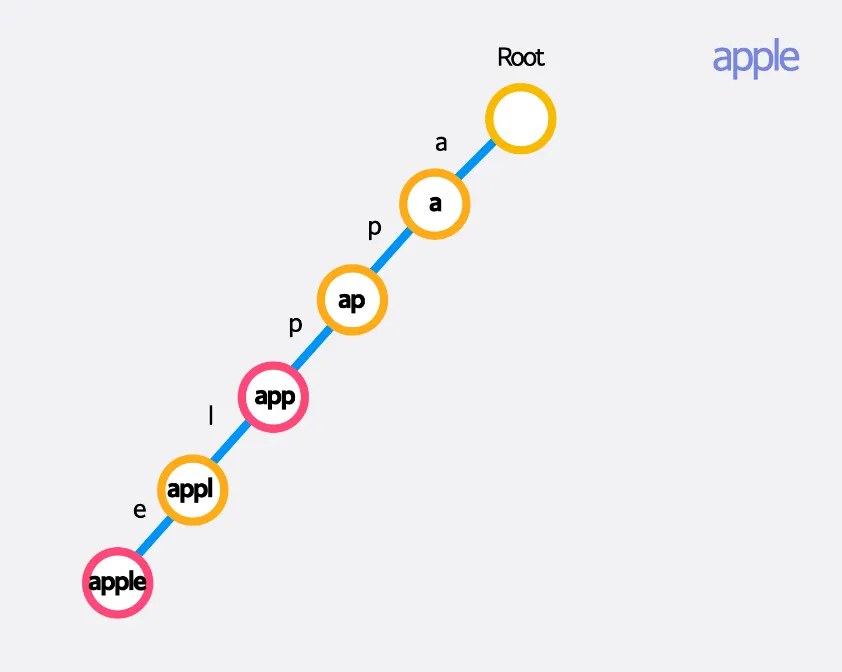
트라이를 만들기 위해서는 문자열 내 문자를 한 번씩만 순회해주면 되기 때문에 모든 문자열 길이 합을 L이라 했을 때 시간복잡도 로 구축할 수 있습니다.
•
Trie에 사용되는 노드를 TrieNode라는 클래스로 구현해보겠습니다. 각 노드는 자식 26개(”a” ~ “z”)를 관리하게 됩니다. (0 ~25의 인덱스 활용)
•
또한 문자열의 끝임을 표시하는 is_end라는 인스턴스 변수를 갖습니다.
class TrieNode():
def __init__(self):
self.is_end = False
self.children = [None] * 26
Python
복사
이 클래스를 통해 words내의 문자열들을 트라이 자료구조로 구축해보겠습니다.
words = ["app", "apple", "apply", "apart", "ban", "banana"]
root = TriNode()
def insert_word(s):
t = root
for char in s:
# 문자열 내의 문자 순서대로 따라갑니다.
index = ord(char) - ord("a")
# 해당 노드가 없다면 새로운 노드 생성
if t.children[index] is None:
t.children[index] = TrieNode()
t = t.children[index]
# 문자열을 추가한 마지막 위치 노드에 문자열의 끝임을 표시
t.is_end = True
for word in words:
insert_word(word)
Python
복사
구축한건 알겠는데, 그럼 이걸가지고 어떻게 빠르게 탐색할까요?
•
트라이 자료구조에서 “ap”의 위치를 찾는데에는 O(2), 즉 O(비교문자열길이)만큼이 필요합니다.
•
그럼 “ap”로 시작하는 서로 다른 문자열은 “ap”노드의 자손 중 is_end가 True인 노드의 개수입니다.
•
트리 노드의 수는 L개가 되기 때문에 O(L)의 시간을 들여 TreeDP를 통해 각 노드마다 자손 중 is_end인 자손이 몇개인지 미리 구해놓을 수 있습니다.
•
그러면 결국 “ap”로 시작하는 서로 다른 문자열 개수 찾기에는 O(2L)의 시간 복잡도가 필요하게 됩니다.
