
NLP는 잘 모르는 분야라 잘못된 설명이 있을 수 있습니다
•
self-attention 은 image / language 위한 generative model에 유용하다.
이 논문에서는
1.
매우 가벼운 weight의 conv연산으로 현 best self attention 에 맞먹는 효과를 내보겠다 ( 2019 기준 )
2.
self attention 보다 더 효과적이고 심플한 dynamic conv를 소개한다
여기서 self attention 은 “Attention is All You Need“ 논문의 transformer구조에 나오는 attention을 말한다.
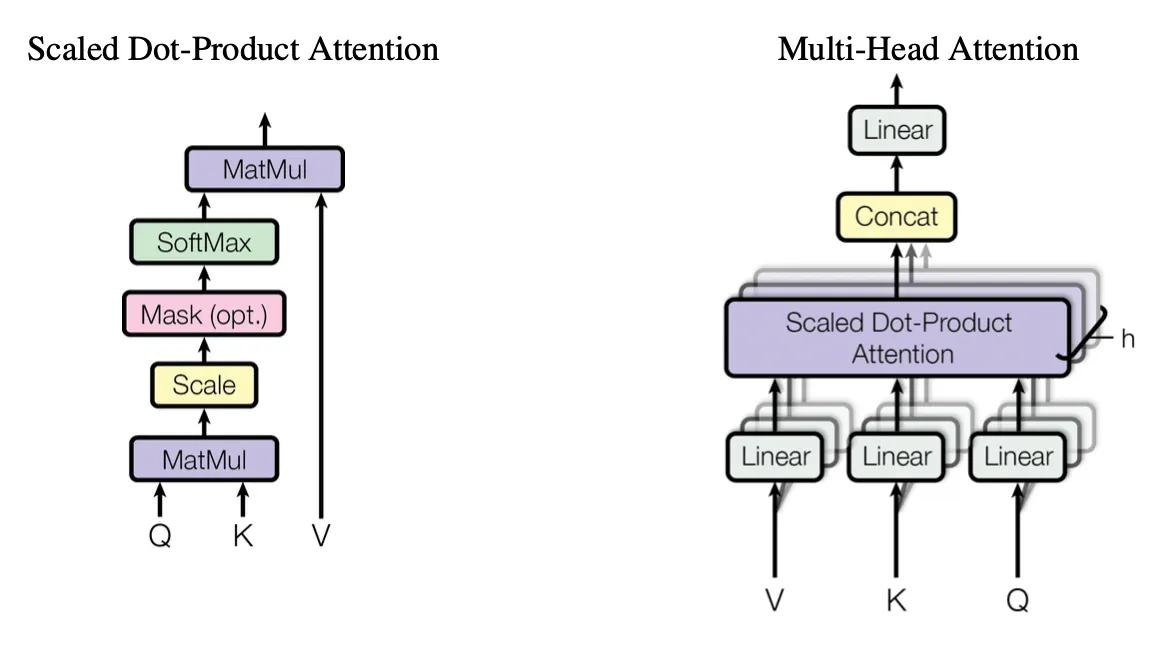
“Attention is All you Need”의 Attention
Self attention은
•
attention weights가 현 time step에서 context내의 모든 요소들과 비교해 계산된다
•
제한되지 않은 context sizes에서 비교를 연산할 수 있는 능력이 주요 특징이다
◦
이 부분은 Sequence modeling된 모델들은 순차적으로 입력이 들어가기 때문에 문장이 길다면 hidden state가 충분한 정보를 담지 못할 수도 있고, 메모리도 많이들기 때문에 무리가 된다. 이부분과 비교하는 부분인 듯 하다
그러나 self attention 의 능력이 long range dependencies일지라도 무한한 context size는 quadratic complexity때문에 연산적으로 매우 어려움의 문제가 있다.
이 논문에서는
depth-wise separable conv, softmax-normalized, 채널간 weights공유를 사용한 lightweight convolution을 소개한다
결과적으로 더 적은 weights가 일반 conv보다 더 일반화가 잘 됨을 보여주고, 현 time step에 상관없이 context 요소들에 대해 같은 weights를 다시 사용한다.
Dynamic Convolution은 이 lightweight convolution으로 이뤄졌고 모든 time step에서 다른 kernel을 학습한다. 이 kernel은 전체 context에 대한 맥락인 self attention과 반대로 현 time step 의 함수이다
Dynamic conv는 모든 position에서 변한다는 점에서 locally connected layers와 유사하다
그러나 training이후 fixed되는 것이 아닌 model 에 의해 dynamically generated된다는 점이 다른점이다.
Sequence to Sequence learning

가 을 구할 때 사용되기 때문에 결국 h_t는 이전의 정보를 모두 함축하고 있는 것이다
그러나 h는 길이가 정해진 embedded vector이기에 문장이 길어지면 정보가 손실될 가능성이 높아지고 성능의 bottleneck이 발생한다.
그래서 모든 state를 decoder로 보내거나 attention을 적극적으로 활용하는 방향으로 발전했는데, 여기서 나온 것이 강력한 Transformer이다.
self attention

depthwise convolution
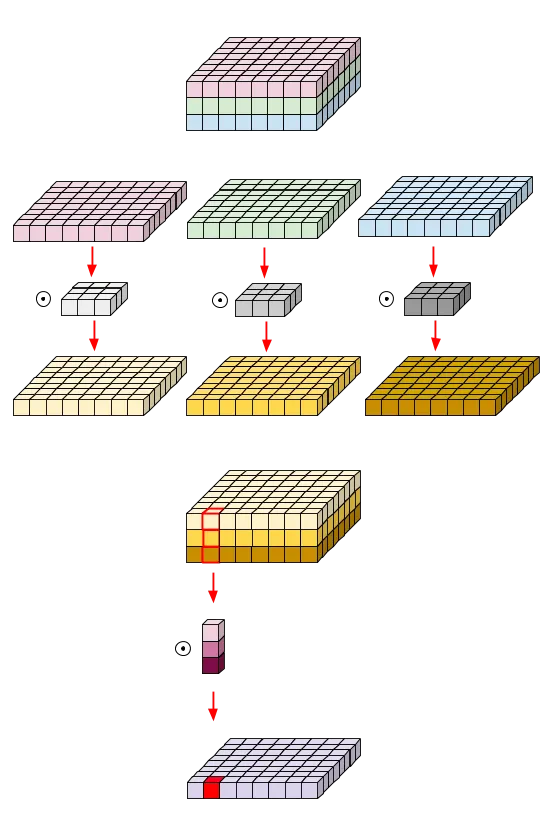
원래 3채널에서 3채널을 만드려면 3채널 필터 3개가 필요한데, depthwiseconv는 각채널마다 따로 conv연산을 해서 3채널의 필터 하나로 3채널을 만들 수 있다.
Light weight Convolution
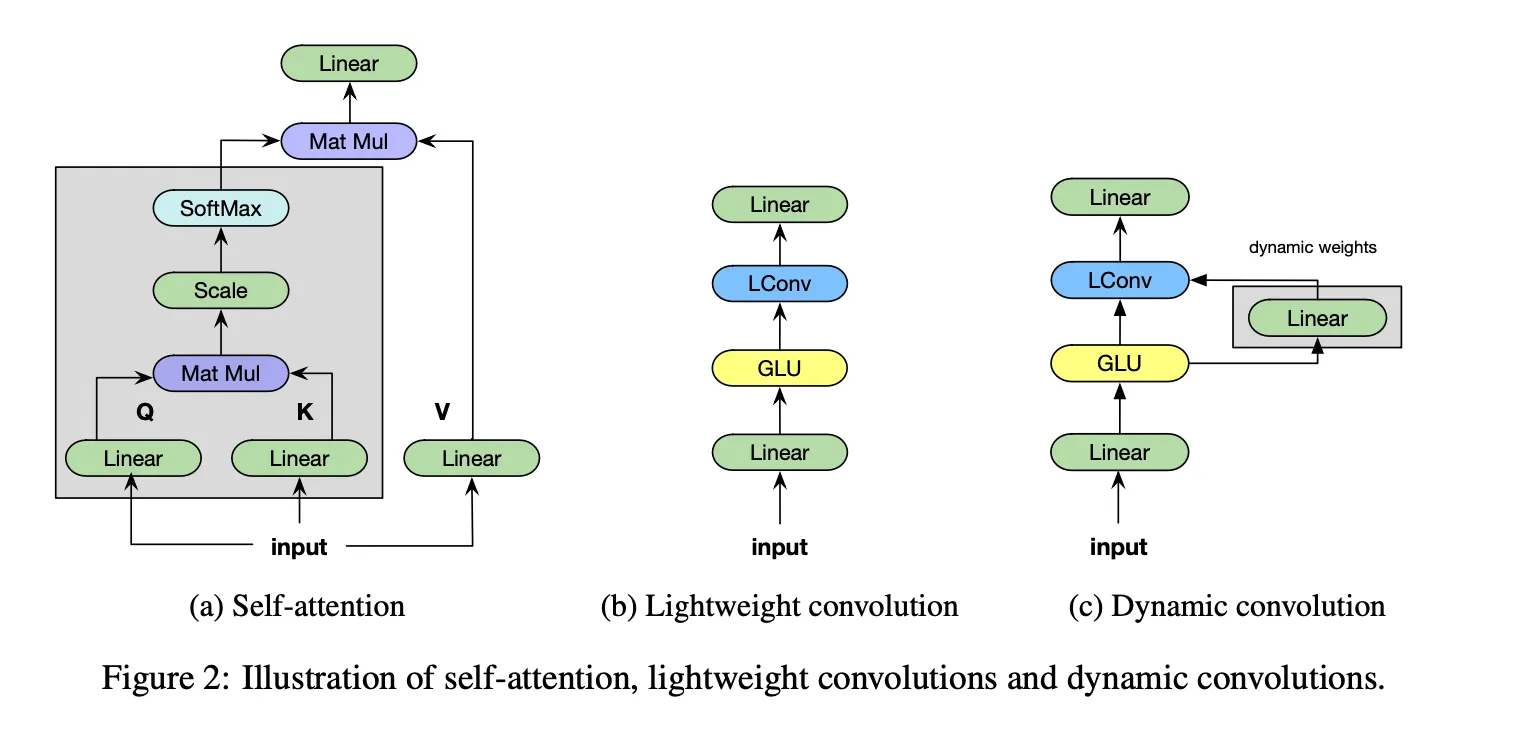
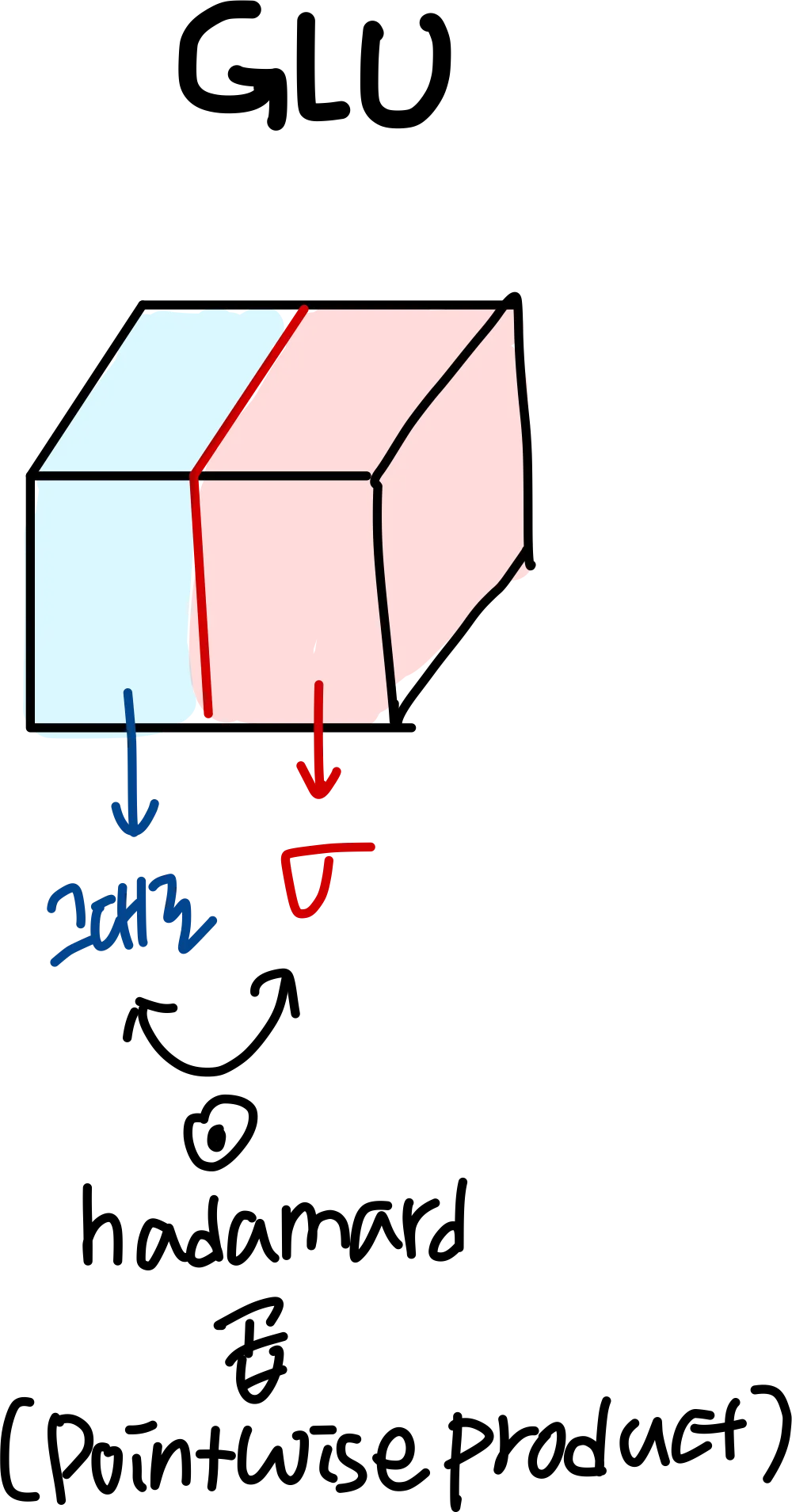
self attention과 다르게 Lconv는 고정된 context window를 가지고 있고 timestep이 지나도 변하지 않는 weigts로 context elements의 중요성을 결정한다
이를 적용하면 일반 conv에 반해 더 잘 일반화됨을 보여주고 SOTA self attention model에 견줄만하다는 것을 보여줄 것이라고 한다
이를 통해 효과적인 dynamic conv를 구성할 수 있었다.

weight sharing
모든 발생하는 채널마다 파라미터들을 묶었다. 그래서 factor로 파라미터를 줄일 수 있었다.
일반 conv : 개 weights 필요
depthwise separable conv : 개 weights필요
d=1024, k=7, H=16이라
개의 112개의 파라미터밖에 안필요했다고 한다. 이렇게 파라미터를 매우 줄인게 현재 하드웨어에서 dynamic conv를 가능하게한 이유라고 말함
softmax normalization
개의 파라미터를 softmax로 normalize했다고 한다 ( dimension 에 대해)
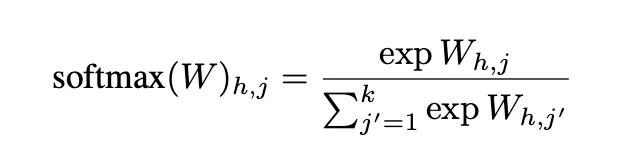
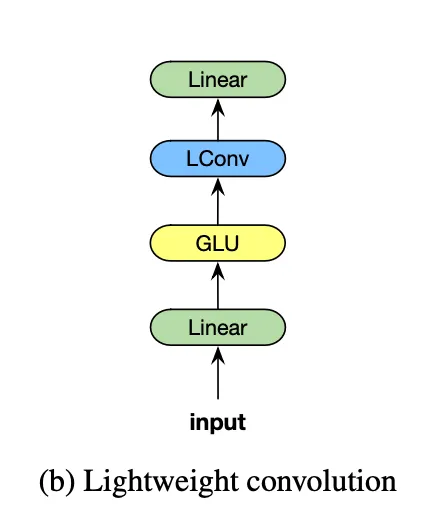
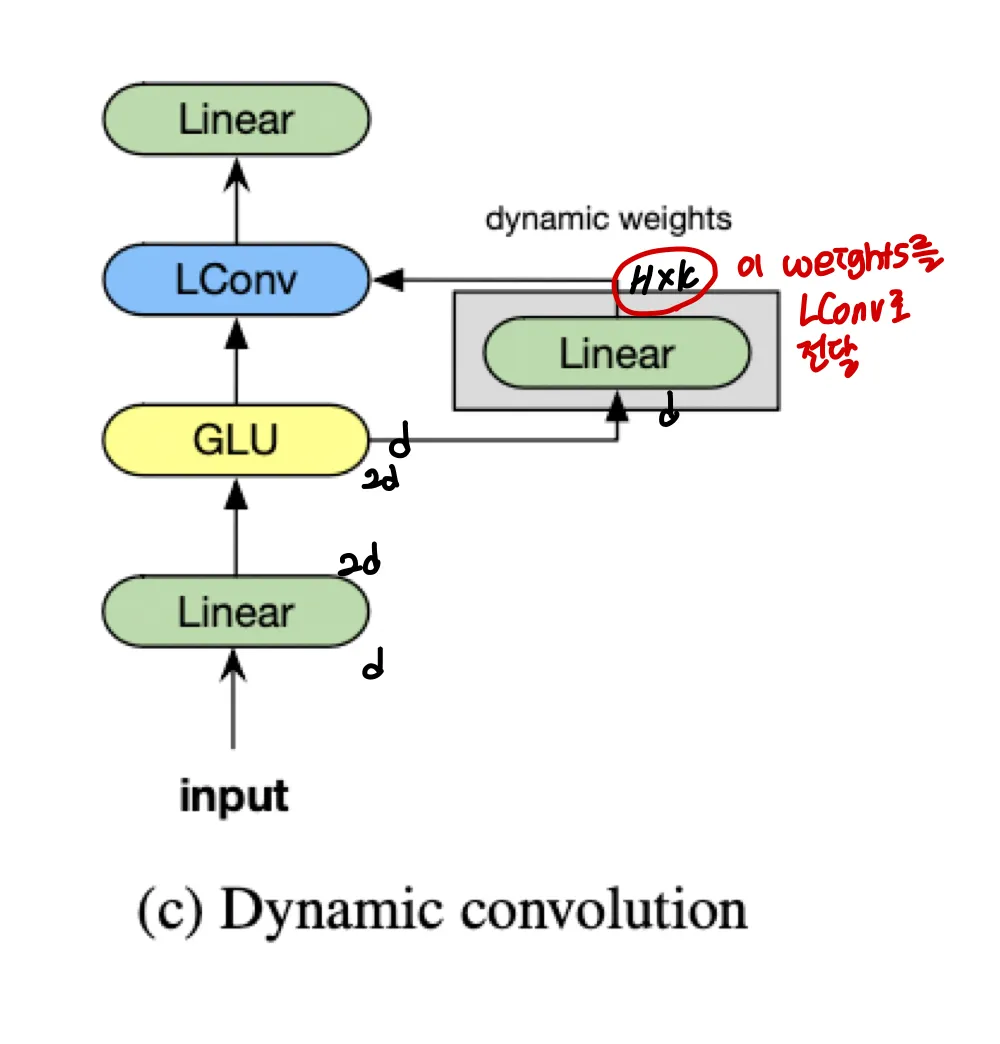
Module
Figure 2b는 LightConv를 통합한 모듈의 그림이다.
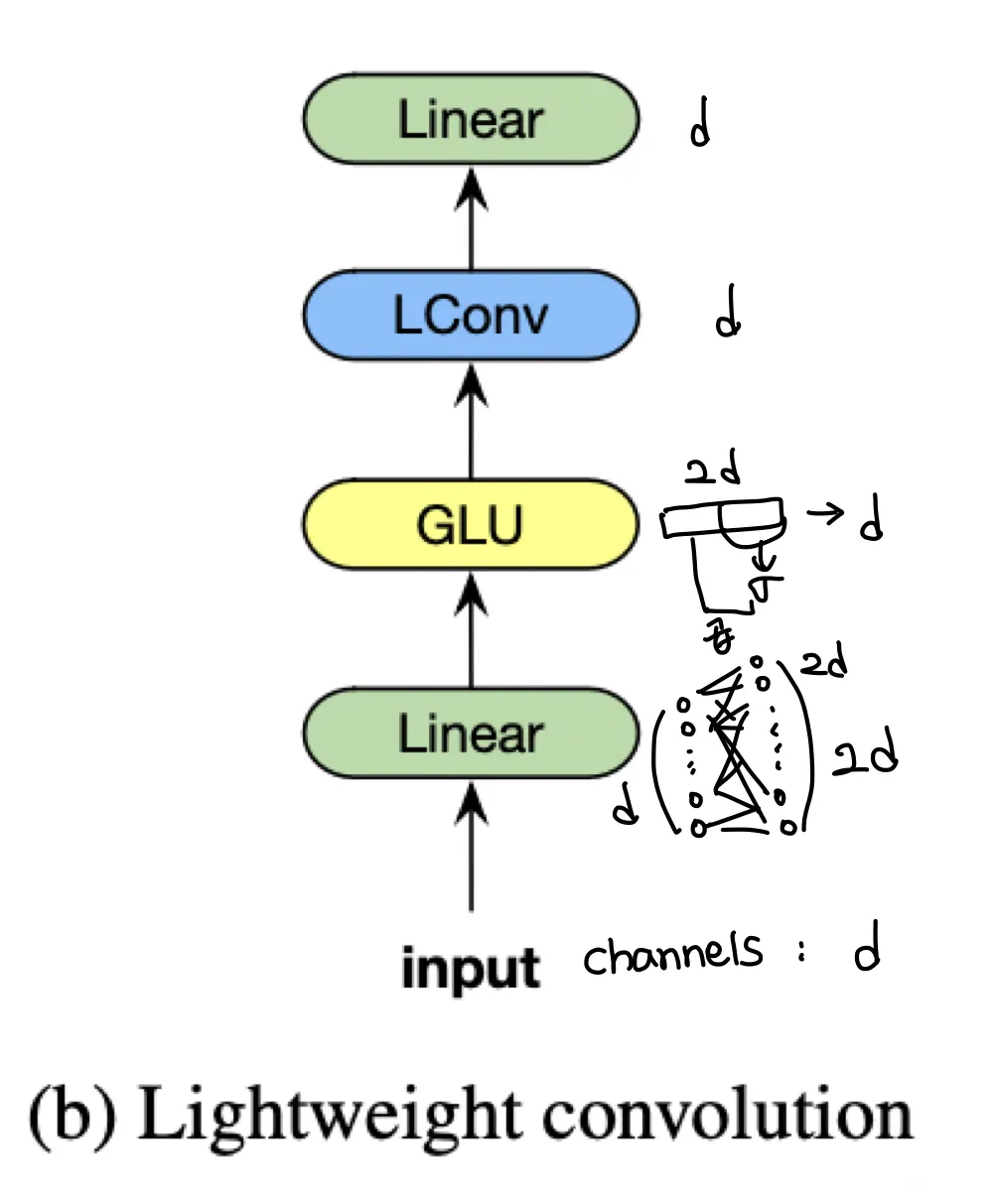
마지막 Linear가 d→d 로 가기때문에 Weight가 차원이라고 말하고 있다 ( )
Regularization
Dropconnection이 LightConv에 좋은 DropConnection이라는 것을 알았다고 합니다.
•
Dropconnection : recurrent 계층에서의 Dropout이라 생각할 수 있다.
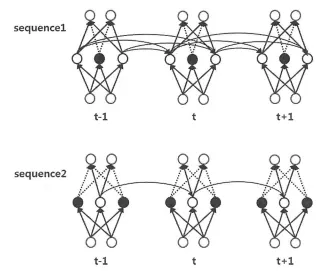
그림과 같이 연결선의 일부를 제거
모든 normalized weights 를 의 확률로 drop하고 training동안 로 나눴다고 한다
이는 채널내의 일부 temporal information을 제거하는 것과 같다고 한다.
Implementation
컨볼루션을 위한 기존 CUDA primitive는 LightConv를 구현하는 데 잘 수행되지 않았고 짧은 시퀀스에서 다음과 같은 해결책을 더 빨리 발견했다.
•
normalized weights 를 의 band matrix로 copy하고 확장
: batchsize
•
그 이후 batch matrix multiplication 수행
code
Dynamic Convolutions
dynamic convolutions는 각 time step에서 학습된 함수가 시간이 지나면서 달라지는 kernel을 가진다
dynamic version of standard convolution은 현존하는 GPU에 실용적이지 않을 수 있다. 큰 메모리가 필요하기 때문이다. 이 문제를 LightConv로 구성함으로 해결했다. 파라미터수를 대폭 줄일 수 있었다.
Dynamic Conv는 LightConv와 같은 form을 가져가지만 time-step dependent kernel을 사용한다.
이 kernel은 다음과 같은 함수로 연산된다
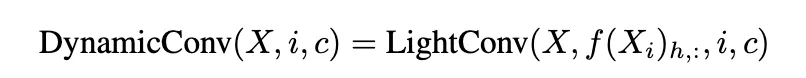
를 심플한 Linear module로 모델링 했다. 이 linear module은 학습된 weights 로 이뤄져있다.
i.e.
self attention 과 유사하게 DynamicConv는 시간이 지남에 따라 context elements에 할당되는 weigths들을 변화시킨다
하지만 DynamicConv의 weights는 모든 context에 의존하지 않고 현재 time step에만 관련이 있는 함수이다.
self attention은 sentence 길이가 늘어남에 따라 attention weights를 연산하기 위해quadratic number of operations가 필요하지만 dynamic kernels for DynamicConv의 연산량은 sequence 길이에 대해 선형적으로 증가한다
code
실험결과
•
Dynamic Conv를 사용한 모델이 SOTA모델의 성능과 동일하거나 더 높았다
◦
SOTA모델은 context-based self attetion을 사용한 모델들
•
이것은 자연어 처리(NLP) 응용 프로그램에서 content-based self-attention의 중요성에 대한 일반적인 직관성에 도전한다.
Experimental Step
Model Architecture
•
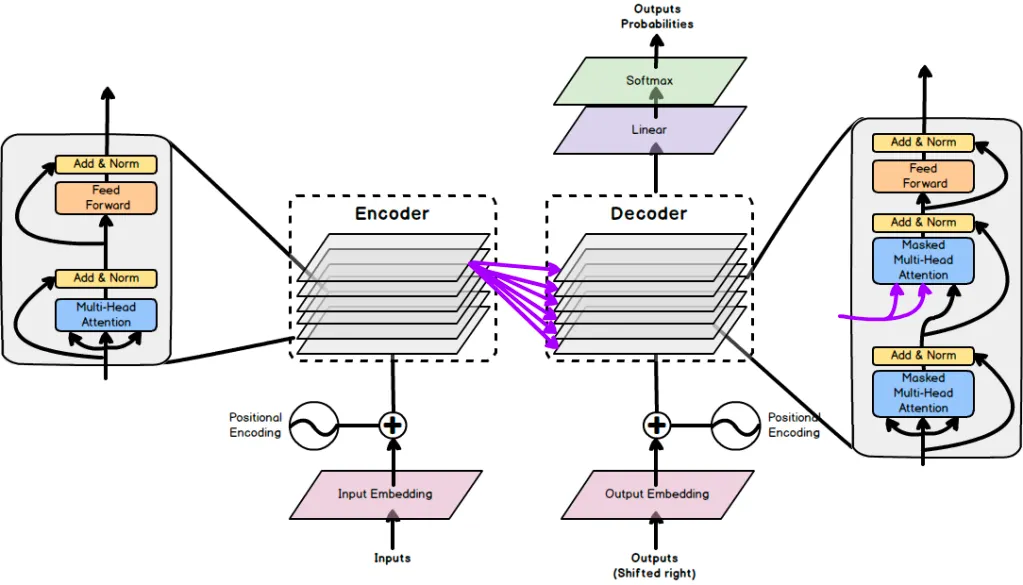
Seq to Seq 학습에서 사용된 encoder-decoder 구조를 사용


•
거의 Transformer구조 따름
•
이 논문의 self attention baseline은 fairseq re-implementation of Transformer Big Archtecture
•
encoder / decoder 네트워크는 각각 N개의 block을 가진다
◦
Encoder block : 2개의 sub-blocks
1.
self-attention module or LightConv module or DynamicConv module
2.
feed-forward module ( )

3.
subblocks는 residual connections와 layer normalization으로 둘러싸여있다.
◦
Decoder block : encoder와 일치하지만 추가적인 source-target attention subblock이 self-attention 과 feed forward block 사이에 존재한다.
▪
source target attention block은 self attention module과 동일하지만 value와 key projections 가 각 source word의 encoder output에서 연산된다
•
단어들은 차원으로 embedding되어 encoder-decoder 네트워크로 들어가고 sinusoidal position embeddings를 추가해 sequence 내 각 word의 절대적 위치를 인코딩한다
•
모델은 decoder output을 변환해서 vocaburary 에 대해 분포를 연산하고 이 변환은 linear layer + 로 이뤄진다
•
LightConv와 DynamicConv는 self attention이 fixed or dynamic convolutions로 교체된다는 것 제외하고 Transformer Big과 동일
◦
더 적은 파라미터 갖기 때문에 N=7로 늘리고 ( 이렇게 하면 Transformer Big과 파라미터 비슷)
◦
◦
LightConv와 Dynamic Conv 의 encoder/decoder kernel size는 3, 7, 15, 31x4 for each block respectively
◦
decoder의 top three layer만 kernel size 31
