
*random variable : 확률 변수
확률 모형과 함께 등장하는 모수 추정, MLE, Log likelihood 등의 용어들을 정리해봅니다
확률모형이란
•
확률 모형은 수집된 / 관측된 데이터의 발생 확률 혹은 분포를 잘 근사하는 모형입니다.
•
Probabilistic model(확률모형), Statistical model(통계모형), Probability distribution(확률분포)
•
•
는 확률 모형을 정의하는 parameter(모수) 입니다. (descriptive measure 요약 통계량이기도 하다)
모수 추정
•
데이터의 이상적인 실제 확률 분포 (모집단의 분포) 가 이라면 이 분포 내에서 X를 수집한다고 이해할 수 있다.
•
모수를 추정한다 함은 를 최대한 잘 근사하는 수학적 모형을 찾는 것이다.
•
근사화된 모델을 사용하는 이유는 당연하게도 실제 데이터의 확률이나 실제 파라미터 를 정확히 알 수는 없기 때문이다.
•
즉, 임의의 확률 모형 를 가정하고, 그 모형이 데이터를 잘 설명할 파라미터 를 찾는 과정이 모수 추정이다.
•
만약 정규 분포를 가정했다면, 에서 의 값을 찾는 것이다.
◦
여기서 는 식에서 볼 수 있듯 평균과 표준편차이다.
◦
정규분포라는 가정 하에 최적의 평균과 표준편차 찾기
Maximum Likelihood Estimation (MLE)
그래서 모수추정을, 그니까 데이터를 잘 설명하는 모형을 어떻게 만드느냐
•
그 모형 안에서 관측된 데이터 의 발생확률이 전체적으로 최대로 만드는 것
⇒ 이것이 MLE다.
•
위의 가 Likelihood function(가능도함수 or 우도 함수)로, 확률 모형을 나타내는 함수이다.
•
는 X가 아닌 에 대한 함수임을 명심해야 한다. 는 고정되어 있는 데이터이며, 가 변하면서 likelihood가 변하게 된다.
•
이 때 를 통해서 의 확률값이 최대가 되도록 하는 것이 목적이다.
◦
주어진 에서 X의 발생확률을 최대로
•
독립항등분포 (iid;Independent and identically distributed random variables)를 가정하였을 때 전개
정규분포라는 가정하에 직관적으로 살펴보기
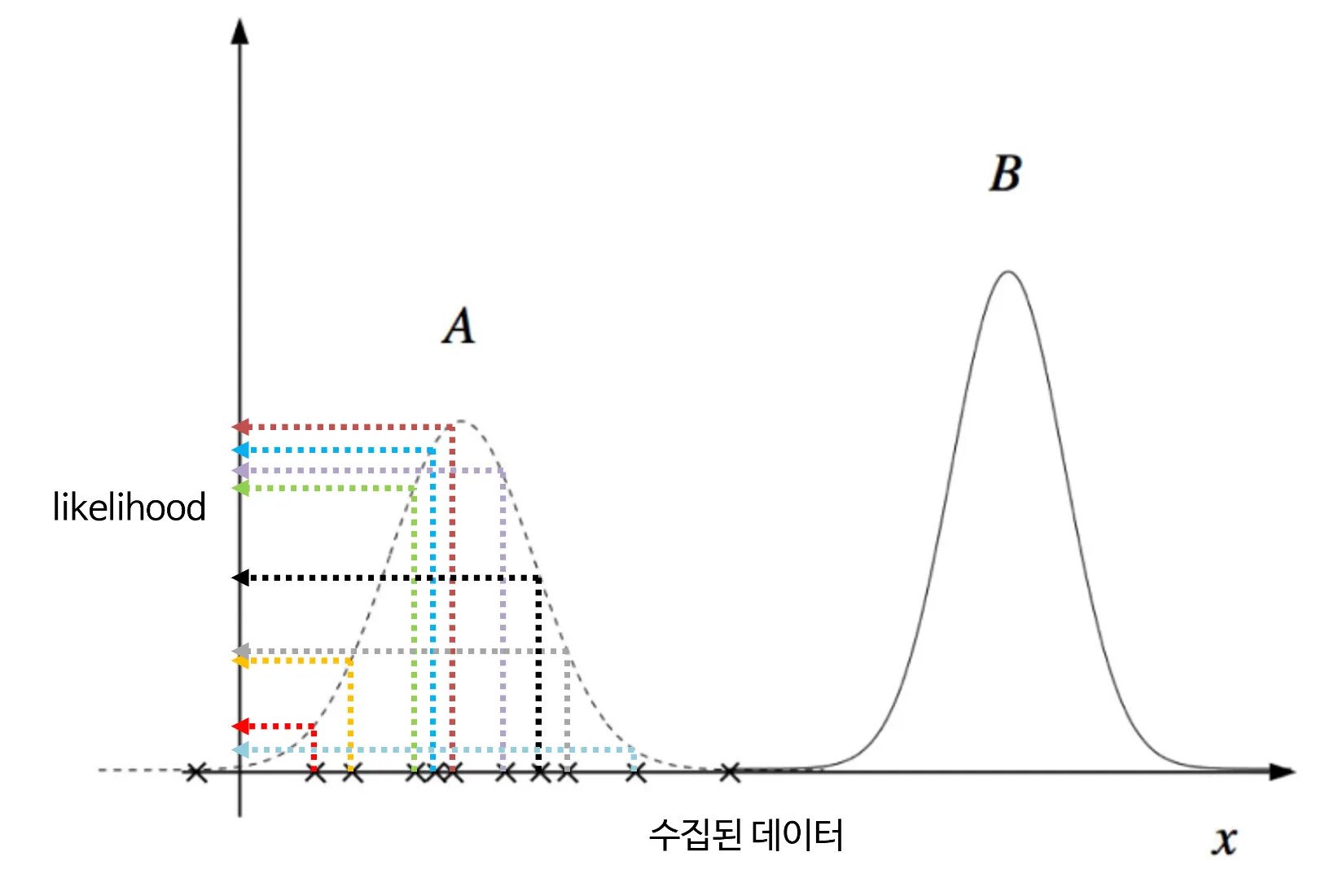
•
앞에서 정규분포를 가정하였다면 평균과 표준편차가 라고 했다.
•
서로 다른 로 A와 B라는 분포가 있다면, 무엇이 데이터를 더 잘 표현하는 분포일까?
•
앞에서 iid를 가정하였기에 X의 likelihood를 연산하기 위해서는 각 데이터의 확률들을 모두 곱하면 된다.
•
B의 경우 0에 수렴하게 되고 A의 경우 비교적 높은 likelihood를 갖게된다.
Log likelihood function
•
likelihood에 log가 붙었다. 왜일까?
•
MSE 추정시 앞에서 보았던 것처럼 각 데이터의 likelihood를 모두 곱하였는데, 1보다 작은 수가 계속 곱해져 수가 매우 작아지므로, 합으로 표현하기 위해 log를 씌워준다.
•
•
log는 증가함수기에
◦
(최댓값에 해당하는 를 구하는 데에는 영향이 없음)
•
합을 최대로 만드는 \theta를 구하는 것과 평균을 최대로 만드는 \theta를 구하는 것은 동일하므로
•
최종적으로 전개된 마지막 식을 empirical expectation이라고 부른다.
