self supervision이라는 개념은 아주 예전부터 있었던 개념이지만 BERT등으로 인해 매우 HOT 해진 주제이다
해진 주제이다
해진 주제이다Why self-supervised learning
딥러닝은 supervised setting에서 아주 강력하다.
즉, 정답을 알고있는 상태 + 충분한 데이터양 존재 의 상황에서 매우 강력한 성능을 보인다.
그러나 라벨링된 large dataset 구축은 매우 힘들다. → 기본적으로 비싸고, 특정분야 ( medical 등 )의 데이터는 annotation 자체가 매우 힘들다.
labelled data가 별로 없을 때의 문제를 해결하기 위해 나온 방법들이 unsupervised learning, self supervised learning, meta learning, transfer learning, few-shot learning 등이다.
Facebook, youtube, google 등만 검색해봐도 unlabeled images / videos 는 넘치고 넘친다. 그러니 이를 사용해보자 라는 것이 self supervised learning이다. ( SSL이라 칭하겠다 )
What is SSL
unlabeled data에서의 representation learning
즉 input의 특징을 잘 담고있는 representation을 추출하도록 학습이 되는 것이다.
unlabeled data이기에 스스로 어떠한 목적을 지정해서 supervision한다. ( 여러가지 방식이 있다. )
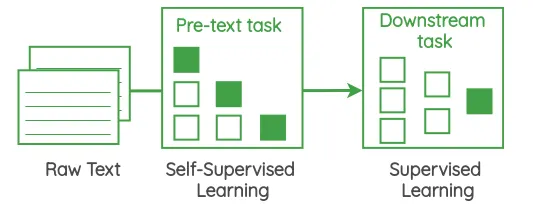
SSL을 사용해 어떠한 task를 위한 모델을 생성할 때에는 보통
1.
pretext tasks : unlabeled data에서 유용한 feature representation을 추출하는 것이 목적
⇒ SSL
2.
downstream tasks : pretext tasks에서 학습되어 추출된 feature representation을 더 향상시켜 어떠한 task에 적용
두가지 단계로 나누어진다.
unsupervised learning과의 비교
•
unsupervised learning은 unlabeled data에서 어떠한 패턴을 찾아내는 것이다
•
clustering / density destimation / dimension reduction 등
transfer learning과의 비교
•
transfer learning은 unlabeled data에서 이뤄지는 SSL과 달리 완전한 supervision환경에서 이루어진다.
•
보통 source task와 target task로 이루어지는데, 이러한 문제 설정에서 차이가 있다.
•
source task는 데이터가 매우 많고 일반적인 상황이며 target task는 레이블이 없거나 적은 상황이다.
•
보통 target task에만 관심이 있다.
•
참고로 source task와 target task에서 모두 잘되기를 바라는 상황은 continual learning이다.
semi-supervised learning과의 비교
•
이 분야는 소수의 labeled data + 비교적 대량의 unlabeled data를 사용해 학습하는 방법이다.
•
pretext - downstream framework가 성능이 매우 좋아져서 최근 많이 쓰이지 않게 되었다고 한다.
이제 NLP와 Vision 분야에서 쓰이는 SSL의 예시들을 살펴보겠다.
SSL in NLP
1.
Center Word Prediction
window 크기를 정해둔 후 문장에서 window를 움직여가면서 가운데 단어를 가리고 가운데 단어를 맞추는 것으로 self supervision 수행 *word2vec의 continuous bags of words에서 사용
2.
Neighbor Word Prediction
1과 유사하나 반대로 가운데 단어만 보고 양쪽 단어를 맞추기 *word2vec의 skip-gram에서 사용
3.
Neighbor Sentence Prediction
3개의 연속된 문장을 가져와서 (previous - center - next ) center 문장만 보고 previous와 next 문장을 맞추기 *skip-thought vector paper에 나온 방식인데 사용은 많이 안한다고 한다.
4.
Auto-regressive Language model
이전 단어에서 다음 단어 예측
예를 들어서 Hi everyone. Today is my birthday!라는 corpus가 들어오면
Hi를 보고 everyone을 예측하고 Hi everyone을 보고 today를 예측하고 Hi everyone. Today를 보고 is를 예측하고 ….를 반복하는 방식
반대로 corpus뒤에서 시작해서 이전 단어를 맞추는 방식으로 진행할 수도 있다. * GPT에서 사용되었으며 많이 사용되는 방식이다.
5.
Masked Language Modeling
text 내의 단어들이 랜덤하게 masked되고 그 masked word를 맞추는 방식이다.
마치 영어문제의 빈칸 맞추기와 유사하다.
BERT에서 사용되어 유명한 방식이다.
6.
Next Sentence Prediction
연속적인 문장들을 넣어주고 랜덤한 문장을 두개 고른다. sentence1, sentence2라고 하면
sentence2가 sentence1뒤에 올 문장인가?를 yes or no로 판단하는 문제이다. 한 문장을 선택한 후 다른 문장들을 돌아가면서 sentece2로 지정하며 학습하면 될 것이다.
masked language modeling만으로는 단어와 단어간의 관계만을 파악할 수 있으므로 이를 통해 문장과 문장 사이의 관계도 파악하고자 했다. *이 또한 BERT에서 사용되었다.
7.
Sentence Order Prediction
6이 너무 쉽다고 하여 나온 방법이다. document 내의 두 문장을 뽑아 이게 올바른 순서인지 아닌지를 판단하는 식으로 학습한다. *ALBERT에서 6을 대체해 사용했다.
8.
Sentence Permutation
문장을 랜덤한 순서로 바꾼 다음에 원래 순서로 고치는 식으로 학습한다. *BART에서 사용되었다.
9.
Document Rotation
특정 word (token)을 rotation point로 잡아서 그 point 앞 부분, 그 point + 뒷부분을 rotate한다. (point가 시작 단어가 되도록) 그리고 이를 복원하는 방식으로 학습이 된다. *BART에서 사용되었다.
10.
Emoji prediction
이 방법은 위의 방식들과 조금 달라보인다. emoji가 감정을 표현한다는 특징에서 아이디어를 얻어왔다. (트위터의 문장들 사용 )
예를 들어 “I’m so happy”라는 문장이 있다면 I’m so happy가 input, 가 라벨이 된다.
”라는 문장이 있다면 I’m so happy가 input, 가 라벨이 된다.문장 다음에 올 emoji를 예측하는 방식으로 학습이 된다. *Deepmoji라는 paper에서 사용이 되었다. 1.2bilion개의 tweets를 사용하였다고 한다. downstream task로 감성분석, hate speech detection, insult detection을 실험했다.
11.
Gap Sentence Generation
문장 여러개가 있으면 그 중 중요한 문장을 mask한 후 그 masked senteces를 생성하는 방식으로 학습이 된다. *PEGASUS paper
SSL in Computer VIsion
1.
Relative Positioning
중심 패치를 하나 정한 후 8개의 이웃 패치를 정한다. 그래서 중심 패치와 랜덤하게 뽑은 하나의 이웃패치를 입력으로 넣어주면 이웃패치의 위치가 어디인지를 결정하는 8 class classification 문제로 학습된다.
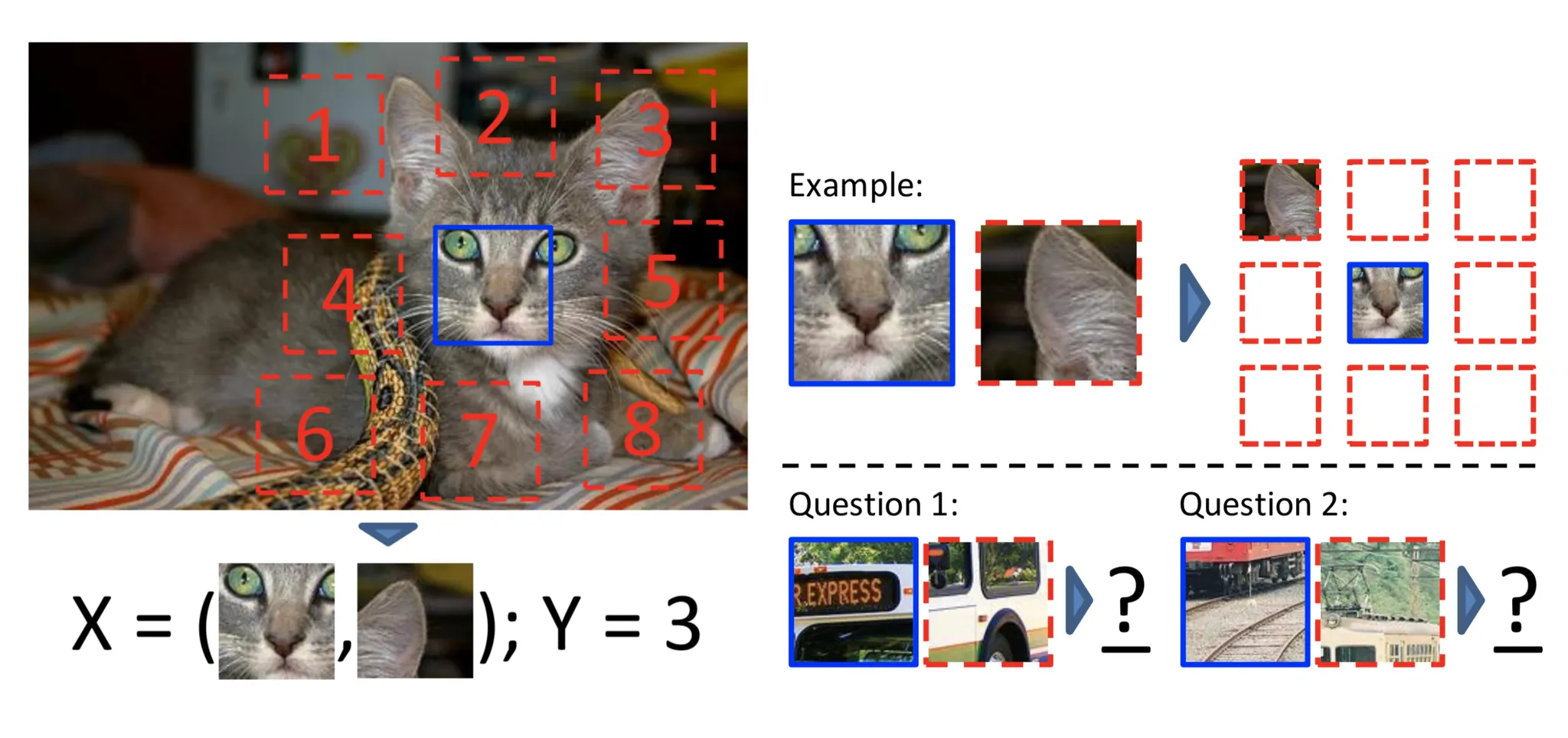
2.
Jigsaw puzzles
255 x 255 크기의 랜덤한 윈도우를 잘라서 75x75크기의 3x3개 패치로 나눈다.
75x75의 패치를 → 64x64크기로 랜덤하게 잘라낸다. 이 64x64 패치들로 학습을 진행한다.
그래서 이 패치들을 올바른 순서로 다시 정렬해주는 방식으로 학습이 되는데, 이는 9!의 경우의 수가 나오므로 64개의 경우의 수를 골라 그 중 하나로 분류하는 64-class classification으로 학습이 진행된다.

3.
Image colorization
이름처럼 흑백사진을 준 후 색을 입히는 방식으로 학습이 된다. CIE Lab* color space를 활용해 진행한다. ( L만 준 후 a와 b를 예측한다 )
4.
Rotation
Geometric transformation recognition을 위한 것인데, 각 이미지를 0°, 90°, 180°, 270°로 회전시킨 후 몇도 돌렸을까요?로 4-class classification으로 학습이 수행된다.
5.
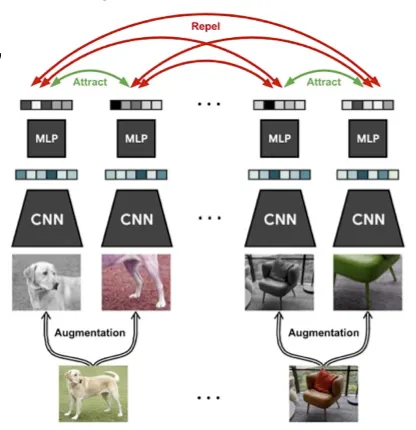
Contrastive Learning
최근 많이 사용되는 방식으로 metric learning등에서 많이 쓰인다. 거리를 측정해 서로 가까운지 먼지를 결정한다. 대표적인 예시로 SimCLR이 있는데, mini-batch를 뽑아 각 이미지에서 랜덤한 부분을 크롭한다.
크롭한 영상들을 augmentation을 다르게 해서 같은 이미지에서 나온 피쳐끼리는 거리가 가깝게, 다른 이미지에서 나온 피쳐끼리는 거리가 멀게 만들어 준다.
classification으로 학습이 되어 CNN + MLP로 학습이 되는데 학습이 끝난 후 downstream task에서는 MLP는 제거하고 사용이 된다.
같은 클래스 내의 다른 이미지는 고려하지 않고 오직 한 이미지 내에 있는가 없는가만 학습한다.
CNN을 freeze한 후 뒤에 MLP만 좀 붙여서 ImageNet classification을 학습했더니 성능이 좋았다!
⇒ linear layer만 새로 학습해도 새로운 task에 좋게 적용할 수 있었다!
대신 학습에 시간이 좀 오래 걸리는 방식이다.
대표적인 SSL 모델들
GPT-3
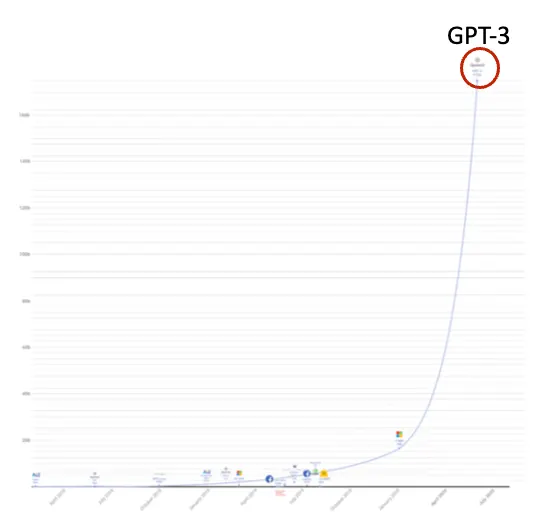
그래프에 보이는 것 처럼 매우매우매우매우매우 많은 파라미터 수를 가지고(175B) 500B개의 토큰으로부터 학습됐다.
language understanding / language generation ( e.g. QA, translation, text writing 등 )을 위한 알고리즘이다. (Generative Pretrained Transformer)
GPT as a few-shot learner
앞서 말했듯 너무나도 큰 모델이라서 finetuning이 어렵게 됐다.
따라서 inference 시 few-shot learner로 작동한다.
예시) 불어→영어 번역을 하고 싶다
불어-영어 쌍 n개를 support set으로 주고 불어문장을 query로 준다. 그러면 이를 영어로 번역을 해준다.
일종의 conditioning
ViT
컴퓨터 비전에 transformer를 적용
BERT와 동일한 아키텍쳐를 사용 → CNN보다 좋은 성능
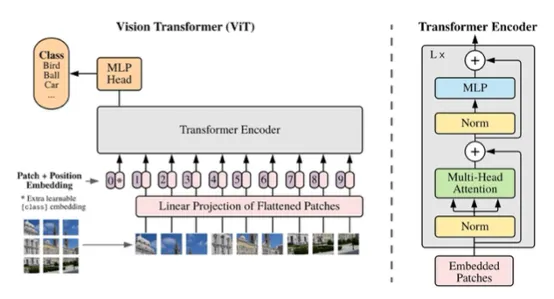
대신 데이터셋이 엄청 많이 필요하다
CLIP
Multi modal model 로 나와 각광을 받았으며, 성능이 매우 좋았다.
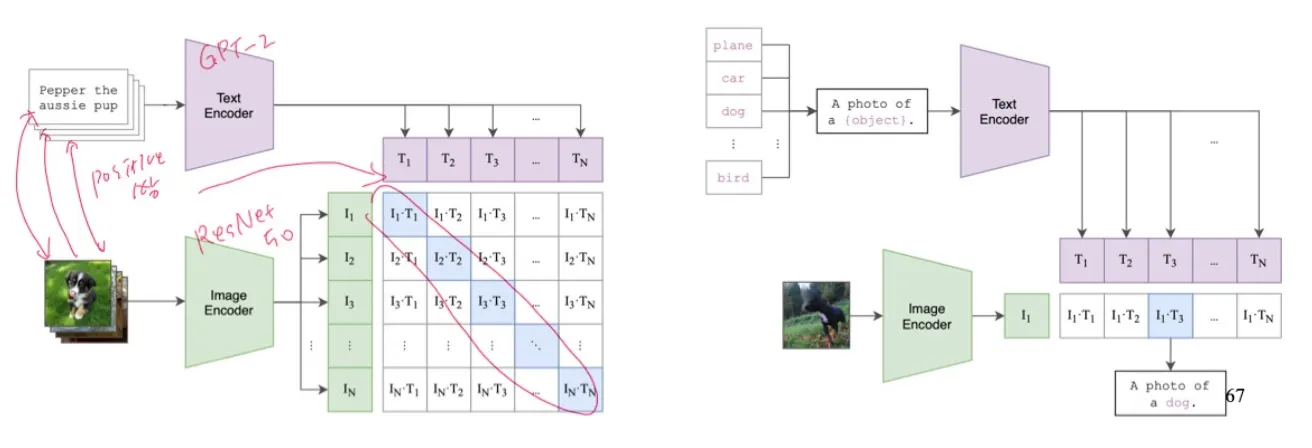
이미지와 텍스트를 joint embedding space로 project한다.
test time시에는 zero-shot transfer로 작동하여 photo of {object}에 분류하고자 하는 클래스들을 넣은 문장들과 image embedding의 similarity를 연산해서 어떤 클래스인지 분류한다.
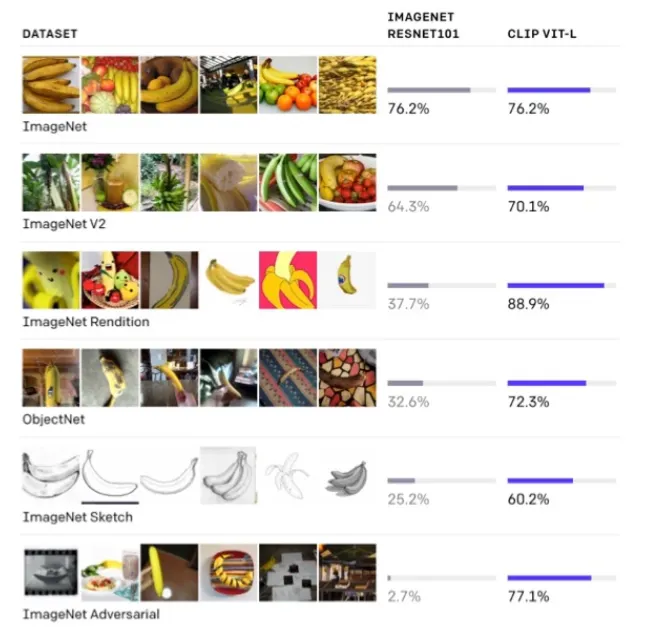
domain이 달라도 성능차이가 크지 않다.
Masked Auto Encoder (MAE)
MAE의 아이디어는 BERT에서 먼저 사용되었으나 vision에서의 발전이 더뎠다.
autoencoder와 개념은 거의 유사하며 encoder보다 decoder를 단순하게 써라 등의 시사점이 있다.
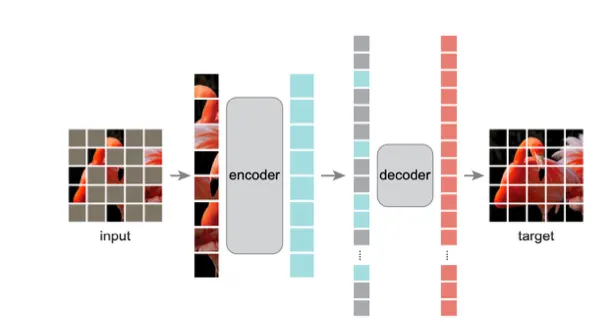
그림처럼 랜덤한 패치를 마스킹하고 (약 75%) masking되지 않은 패치들만 encoder에 들어간다. 그리고 그 encoder에서 나온 tokens에 masking tokens를 추가하고 decoder에 입력해준다. 그렇게 해서 masking된 패치들을 예측하는 식으로 학습이 진행된다.
pretrain이 끝나면 decoder는 제거되고 encoder를 이용해 downstream tasks를 수행한다.
