
VGG모델은 2014년 ImageNet Challenge 에서 top-5 테스트 정확도를 달성했다. (92.7%)
16~19 레이어의 깊은 신경망 모델 학습에 성공했다. 이는 AlexNet(2012) 8레이어의 두배가량이다.
모든 conv 레이어에서 3x3 필터만을 사용한 것이 깊은 신경망을 가능하게 한 요인이다
주로 VGG16만을 다루겠다
VGG16
•
13 Convolution Layers + 3 Fully-connected Layers
•
3x3 convolution filters
•
stride: 1 & padding: 1
•
2x2 max pooling (stride : 2)
•
ReLU
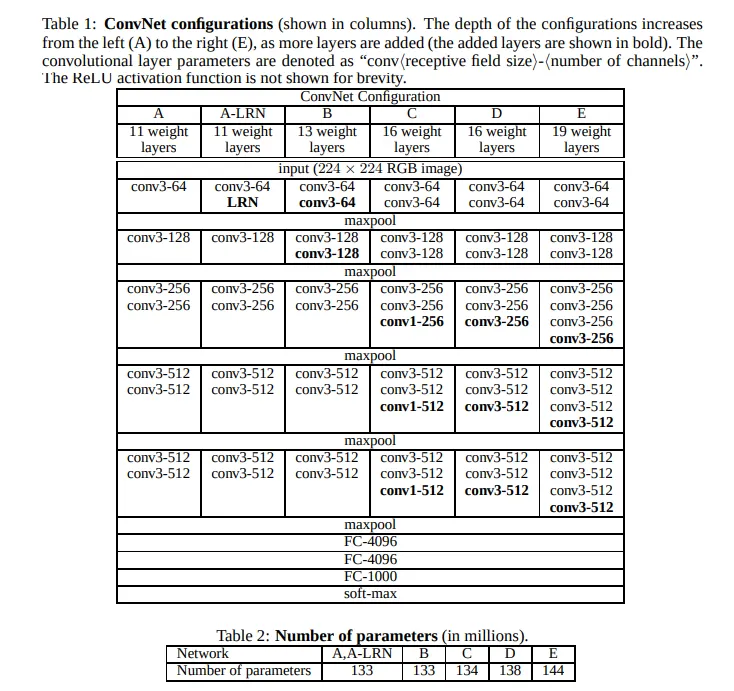
conv3 = 3x3 필터 conv레이어
conv1 = 1x1 필터 conv레이어
conv{ } - number of channels(==필터 개수) 형식
마지막 3개의 FC 레이어 : 각각 4096, 4096, 1000 개의 유닛 구성
출력층 1000은 class 수이다. → softmax로 들어감 (classification위해)
D 모델이 vgg16이다
Batchnorm 이 들어가면
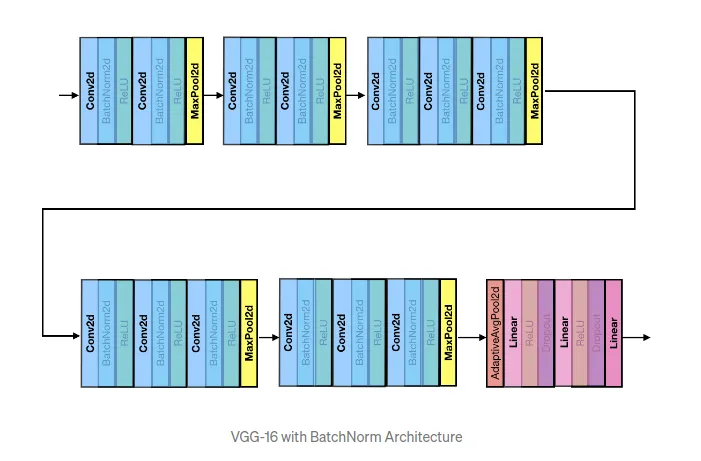
이런 형식이 되는데, 이 버전이 많이 사용된다
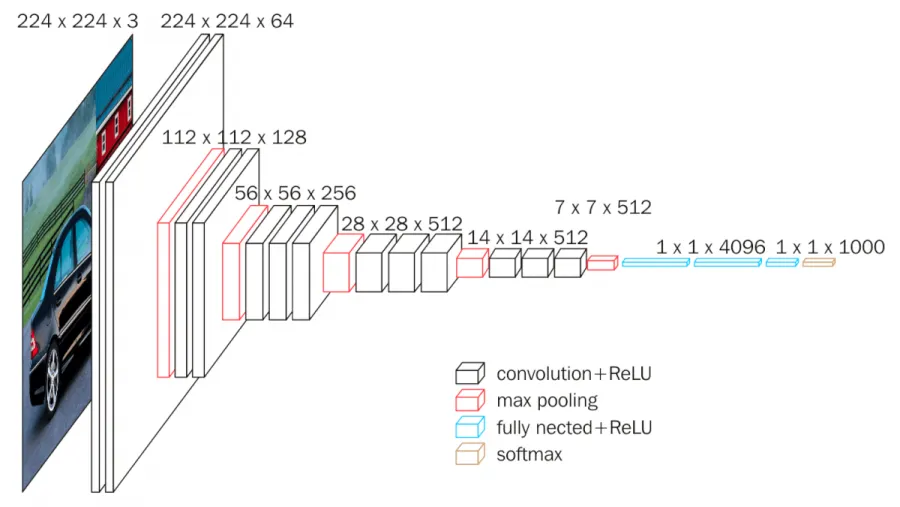
VGG16
3x3필터
VGG 이전에 성능이 좋았던 CNN의 경우 큰 receptive field 갖는 11, 7 필터를 사용했는데, vgg모델은 3크리 필터로 성능을 향상
이유가 뭘까? - 간단히 말하면, 3x3필터를 여러번 사용하면 큰 크기의 필터의 효과를 낼 수 있다. 다음 그림이 설명해준다
7x7필터의 경우
3x3 을 반복한 경우
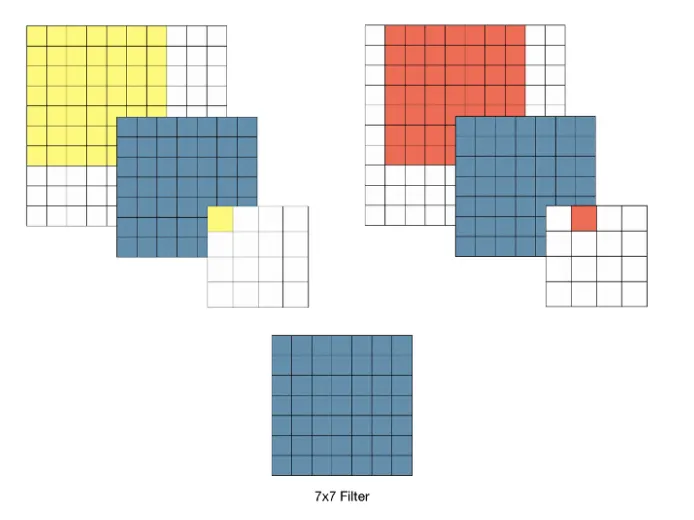
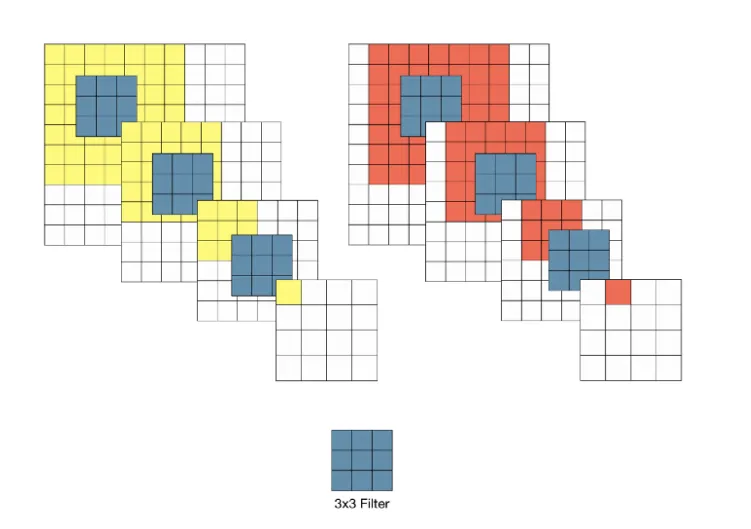
두 경우 모두 최종적인 receptive field는 같아진다 (stride가 1일 때)
그렇다면 차이는 뭘까?
3x3필터 와 7x7 필터의 차이
각 conv연산은 이후 ReLU라는 acrivation function을 포함하게 된다.
7x7필터 한번 사용보다 3x3 필터 어려번에서 ReLU가 여러번 적용되는 것이다. 즉, 레이어가 증가함으로써 비선형성이 증가하게 된다. 이는 모델의 특징을 식별하는 성능의 향상으로 이어진다.
그와 동시에 당연히 파라미터 수도 줄게된다 (7x7 = 49, 3x3x3 = 27)
그러나
여러 레이어를 거친 feature map은 동일 Receptive Field를 갖는 것과는 별개로 더 추상적인 정보들을 담게되기 때문에 여러 레이어를 거치는 것이 꼭 항상 좋다고만은 할 수 없다.
Training
VGG-16 원문에서는 학습 시 다음과 같은 최적화 알고리즘을 사용하였다:
•
Optimizing multinomial logistic regression
•
mini-batch gradient descent
•
Momentum(0.9)
•
Weight Decay(L2 Norm)
•
Dropout(0.5)
•
Learning rate 0.01로 초기화 후 서서히 줄임
가중치 초기화
딥러닝에서 신경망 가중치의 초기화는 학습 속도 및 안정성에 큰 영향을 줄 수 있기 때문에 어떤 방식으로 초기화할 것인지는 중요한 문제 중 하나이다.
VGG 연구팀은 이러한 문제를 보완하고자 다음과 같은 전략을 세웠다:
•
상대적으로 얕은 11-Layer 네트워크를 우선적으로 학습한다. 이 때, 가중치는 정규분포를 따르도록 임의의 값으로 초기화한다.
•
어느 정도 학습이 완료되면 입력층 부분의 4개 층과 마지막 3개의 fully-connected layer의 weight를 학습할 네트워크의 초기값으로 사용한다.
논문 제출 후 Glorot&Bengio (2010)의 무작위 초기화 절차를 이용하여 사전 훈련 없이 가중치를 초기화하는 것이 가능하다는 것을 알아냈다.
학습 이미지 크기
모델 학습(Training) 시 입력 이미지의 크기는 모두 224x224로 고정하였다.
학습 이미지는 각 이미지에 대해 256x256~512x512 내에서 임의의 크기로 변환하고, 크기가 변환된 이미지에서 개체(Object)의 일부가 포함된 224x224 이미지를 Crop하여 사용하였다.

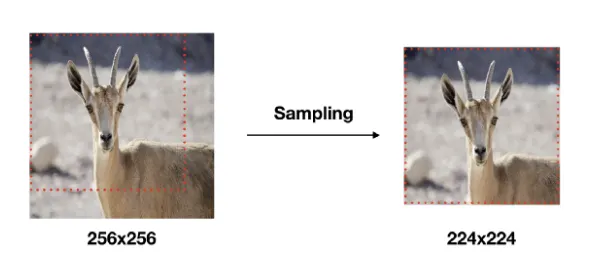


이러한 형식으로 데이터를 사용하면 좋은 것
1.
Data Augmentation의 효과
2.
하나의 객체에 대해 다양한 측면을 학습에 반영 가능
3.
변환된 이미지 작다 - 개체의 전체적인 모습 학슴
변환된 이미지 크다 - 개체의 특정 부분 학습 반영
( sliding window 개념과 비슷하다고 생각하면 될 것 같다)
⇒ 모두 Overfitting을 방지
Testing시에는 3개의 FC레이어를 conv 레이어로 변경
fc1 ⇒ 7x7 conv
fc2, fc3 ⇒ 1x1 conv
=⇒ Fully Convolutional Networks
conv레이어로만 이뤄지면 입력이미지 크기의 제약이 없어지기 때문에 하나의 입력 이미지를 다양한 스케일로 사용한 결과를 앙상블해 이미지 분류 정확도를 개선할 수도 있다.
Fully Convolutional Networks 매우 중요한 개념
결론
VGG 연구팀의 실험 결과를 통해 네트워크의 깊이가 깊어질수록 이미지 분류 정확도가 높아지는 것을 확인할 수 있었다.
실험에서 네트워크의 깊이를 최대 19 레이어(VGG-19)까지만 사용한 이유는 해당 실험의 데이터에서는 분류 오차율이 VGG-19에서 수렴했기 때문이다. 학습 데이터 세트가 충분히 많다면 더 깊은 모델이 더 유용할 수도 있다.
