proposed DINO(self-distillation with no labels)는 unlabeled data로부터 self-supervised learning, self-knowledge distillation을 통해 객체의 segmentation 영역을 찾아낸다.
Introduction
Transformer (Attention is all you need)논문이 2017년 발표되어 NLP를 주도했고 ViT논문이 2021년 ICLR에서 발표되면서 vision 분야에도 영향을 미치기 시작했다.
그러나 왜 잘 되는지 이유가 뚜렷하지 않고, 피쳐들이 특별한 특성을 담고있지 않기 때문에 Transformer의 성능이 BERT 나 GPT같은 self-supervised pretraining에서 온 것인지 저자들은 알고 싶었다고 한다.
self supervised pretraining : pretext tasks 생성해 supervised보다 풍부한 learning signal 제공
따라서 self supervised learning 이 ViT에 어떤 영향을 미치는지 연구하였다.
supervised ViT와 convnets에서 나타나지 않는 self-supervised ViT의 특별한 특성:
1.
scene layout을 포함한다. (object boundaries) 이 정보는 마지막 블럭의 self attention modules에서 바로 접근 가능했다.
2.
basic k-NN과 잘 작동한다. (finetuning, linear classifier, augmentation 없이)
1번은 self sueprvised 방식들에서 공통적으로 나타났으나 2번은 DINO의 momentum encoder와 multi-crop augmentation을 더했을 때만 나타나는 특별한 특성이라고 한다.
DINO
framework

•
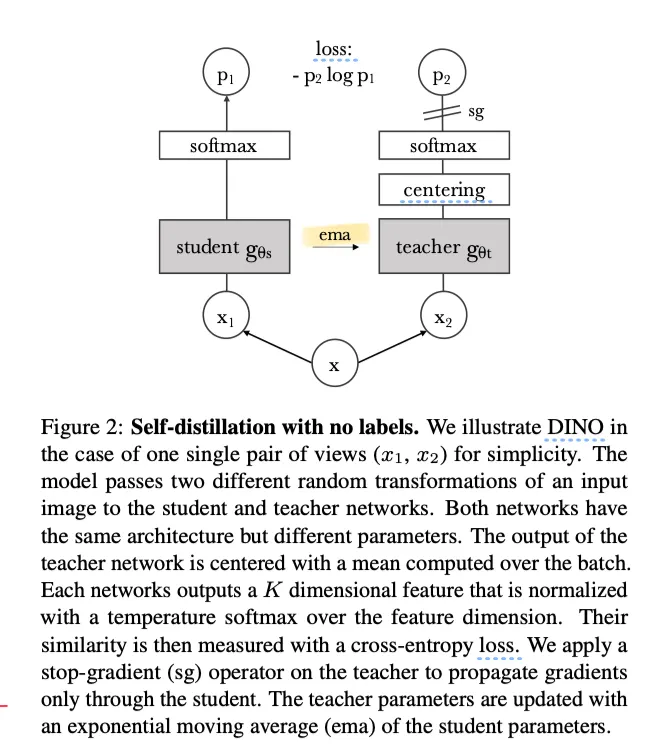
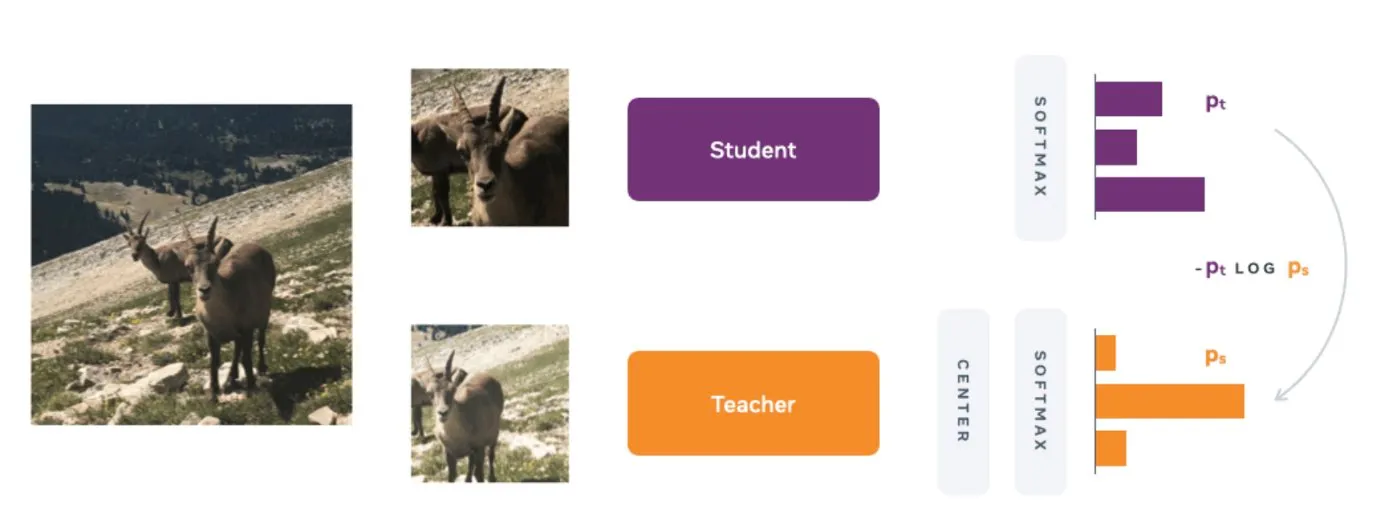
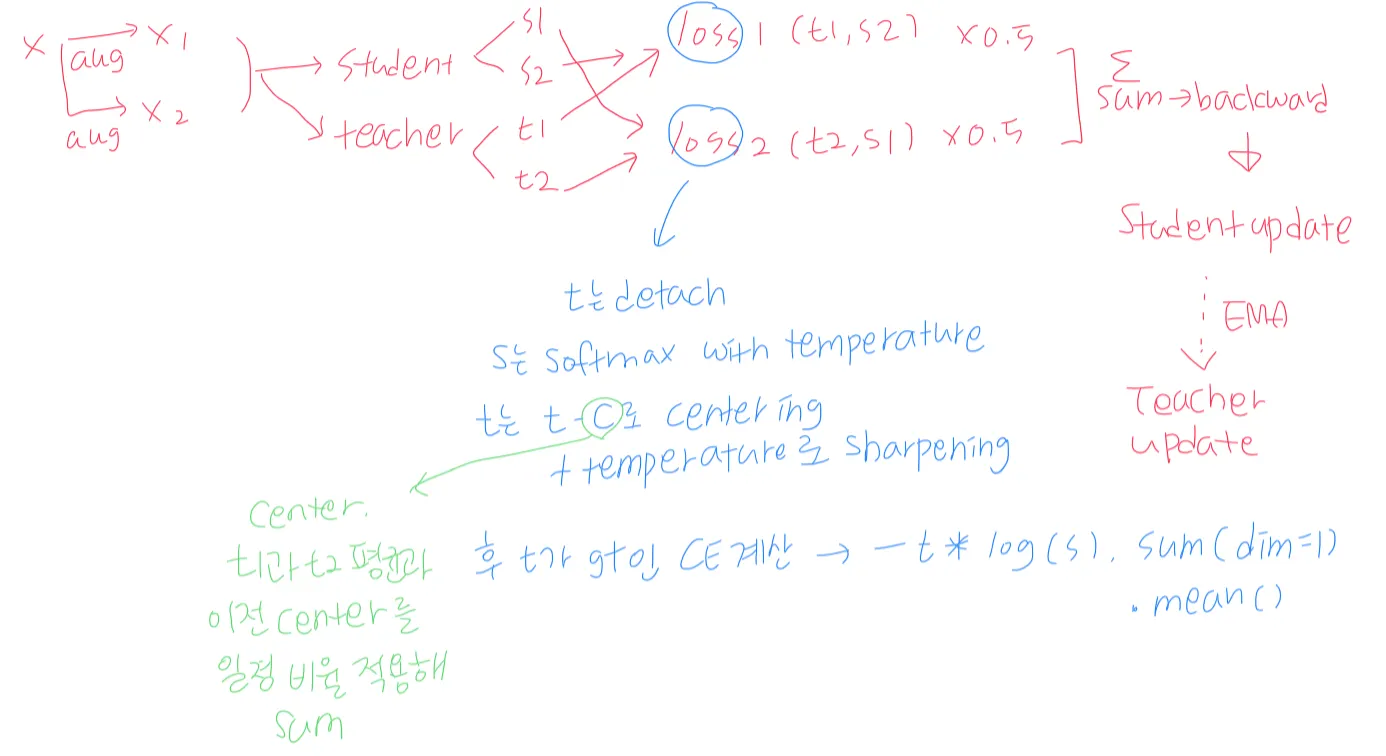
DINO는 기본적으로 KD(knowledge distillation)이다.
•
KD는 student가 teacher의 output을 따라가도록 하는 방식이다.
•
teacher는 backpropagation을
•
DINO에서 각 네트워크의 output은 softmax with temperature를 통해 normalize된다. (sharpening)
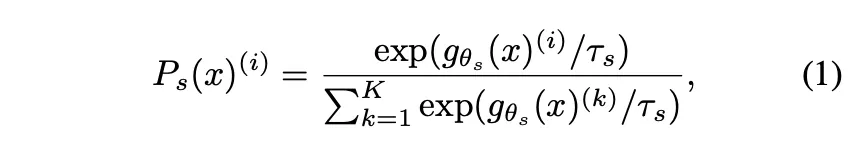
•
teacher은 sharpening에 더해 centering도 수행한다 (algorithm 1의 t = softmax((t-c)/tpt, dim=1))
•
fixed teacher (EMA로 업데이트 되는 teacher)를 통해 student와 teacher의 distribution을 맞추기 위해 cross entropy loss 를 사용한다.
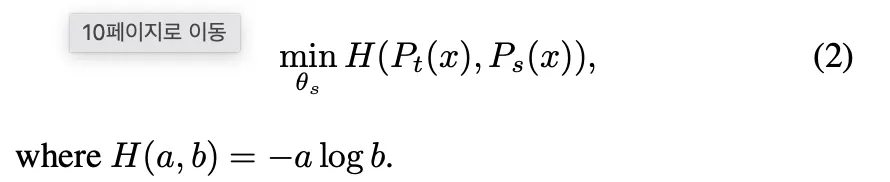
그렇다면 self KD를 어떻게 적용했을까?
일단 이미지를 multi crop strategy를 사용해 여러 다른 distorted views, crops를 만들었다.
multi-crop strategy
•
2개의 global views (, ) + several local views 생성
•
global views : 224 x 224 size (원본의 50%이상 차지)
local views : 96 x 96 size (원본의 50% 미만 차지)
•
global views → teacher input
global views + local views → student input
⇒ local-to-global correspondences
•
이 설정을 더하여 다시 구성한 loss 식은 다음과 같다.
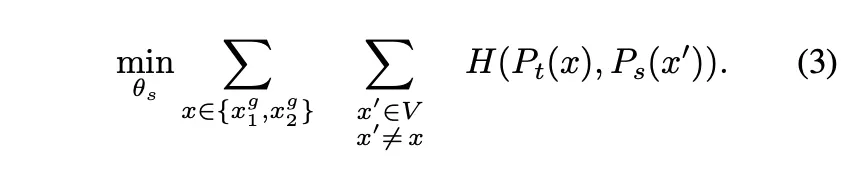 teacher와 student는 같은 아키텍쳐를 가지며 student는 SGD를 통해 업데이트 된다.
teacher와 student는 같은 아키텍쳐를 가지며 student는 SGD를 통해 업데이트 된다.teacher network
KD와 달리 teacher에게 priori를 주지 않았다. 대신 student의 과거 iterations를 통해 teacher를 빌드하였다.(EMA; momentum encoder)
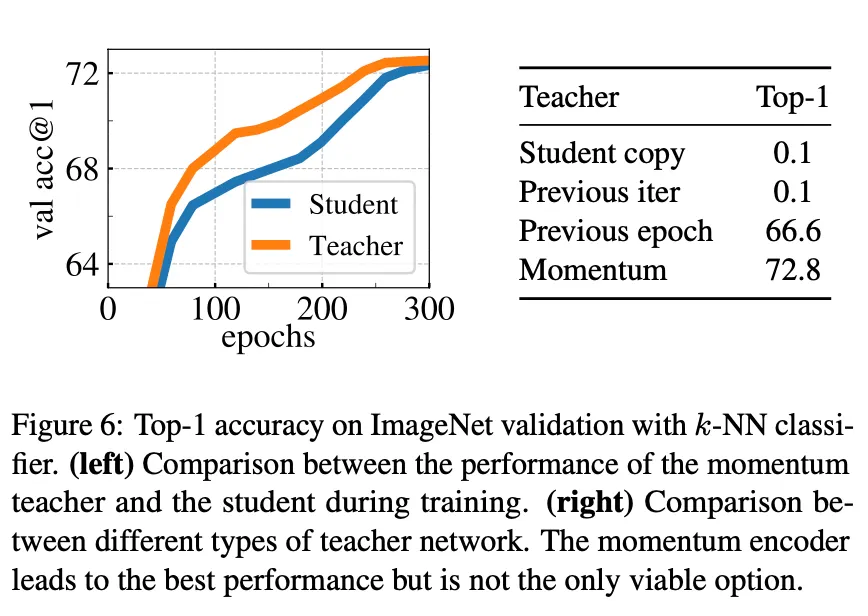
section 5.2의 teacher type별 성능 비교
student의 past iterations를 통해 EMA로 업데이트하는 momentum encoder 형식의 teacher가 가장 성능이 좋고, 그저 student의 weights를 복사하는 것으로는 네트워크가 수렴하지 못 했다.
update rule : , 는 0.996에서 1까지 cosine schdule된다.
원래 momentum encoder는 contrastive learning에서 queue의 대체품으로 소개되었으나 DINO에서는 self training의 mean teacher의 역할에 더 가깝게 사용하였다.
Network Architecture
•
Backbone () : ResNet or ViT
•
projected head() : 3-layer MLP
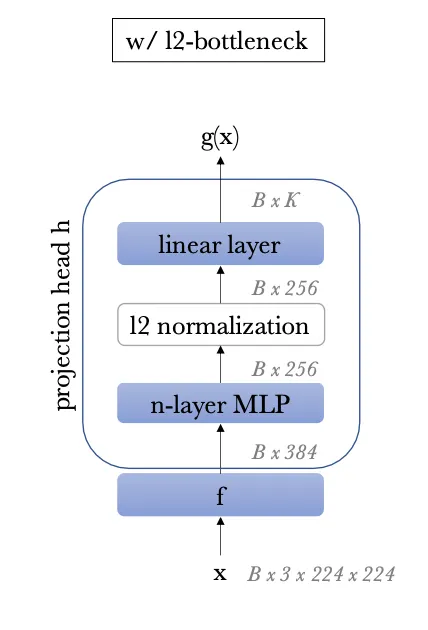
•
f의 output이 downstream task에서 쓰인다.
•
network
•
ViT의 경우 convnets와 달리 BN이 안쓰이기 때문에 h에서도 BN을 사용하지 않았다고 한다.
Avoiding collapse
다양한 self-supervised methods는 collapse를 피하기 위해 다양한 연산을 사용했다. (e.g. contrastive loss, clustering constraints, predictor, batch normalization)
DINO에서는 teacher의 centering과 sharpening으로 model collapse를 피했다.
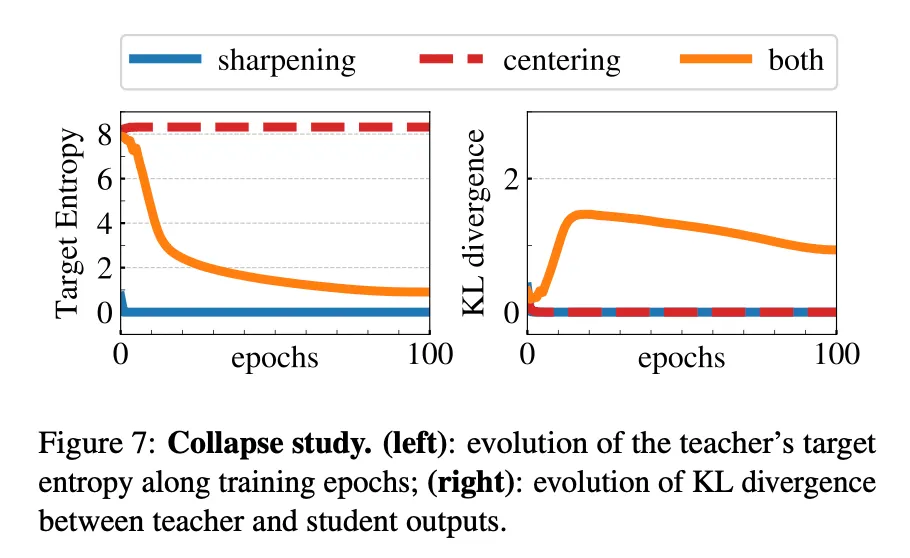
section 5.3의 표. centering만 적용했을 때, sharpening만 적용했을 때, 둘 다 적용했을 때의 epoch별 target entropy와 s와 t의 KD divergence를 그린 그래프이다.
centering은 한 dimension이 학습을 지배하는 것을 막지만 uniform distribution으로의 collapse라는 부작용이 있다. sharpening은 반대의 효과가 있다. 그래서 두 연산을 함께 사용하면 발란스가 맞아진다.
center C는 EMA로 업데이트된다. centering은 first-order batch statistics에만 의존하기에 teacher에 c라는 bias term을 추가한 것으로 볼 수 있다.
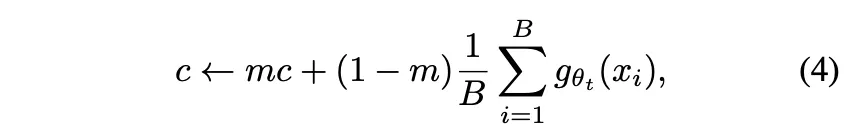
m (>0) : rate parameter
B : batch size
(centering을 수행한 뒤 sharpening을 수행한다.)
Implementation and evaluation
•
DeiT의 구현을 따랐다.
•
ViT는 NxN resolution의 패치들을 사용하는데 N=16 or 8 으로 사용했다.
•
모든 패치들은 linear layer로 들어가고 embedding 집합을 구성한다.
•
추가적인 learanable token을 사용했는데, 이것의 역할은 전체 시퀀스의 정보를 집계하는 것이다. 그리고 그것의 output에 h를 부착하였다. 이것을 CLS token이라고 이름붙였다. (이전 연구들과의 일관성을 위해 라벨이 없음에도 이렇게 이름붙임)
•
패치들에 대한 token과 CLS token은 standard Transformer network with a pre-norm layer normalization에 들어간다
implementation details
•
pretrain models on the ImageNet without labels
•
adamw optimizer
•
batch size 1024
•
ViT-S/16
•
lr = 0.0005 * batchsize/256 으로 10epoch동안 warm up. 이후에는 cosine schedule을 따름
•
\tau_t = 0.1 while linear warm up, 0.04 to 0.07 during first 30 epoch
•
follow BYOL augmentation (color jittering , gausian blur and slarization) and multi crop with bicubic interpolation
Evaluation protocols
•
standard protocols
◦
learn linear classifier on frozen features
◦
finetune the features on downstream tasks
•
for linear evaluation, random resize crops and horizontal flips augmentation are applied during training
•
for fine tuning evaluation, initialize with pretrained weights
•
위의 두 방식은 하이퍼 파라미터에 매우 민감함. 그래서 피쳐의 퀄리티를 단순한 weighted k-NN을 통해 평가함.
◦
pretrain model을 freeze하고 downstream task data에 대한 피쳐를 연산하고 저장한다.
◦
nearest neighbor classifier는 이미지의 피쳐를 k개의 가까운 stored features를 통해 라벨을 투표한다. 20 NN이 젤 잘되었다고 한다.
◦
하이퍼파라미터는 k만 필요하다. data augmentation도 필요하지 않다.
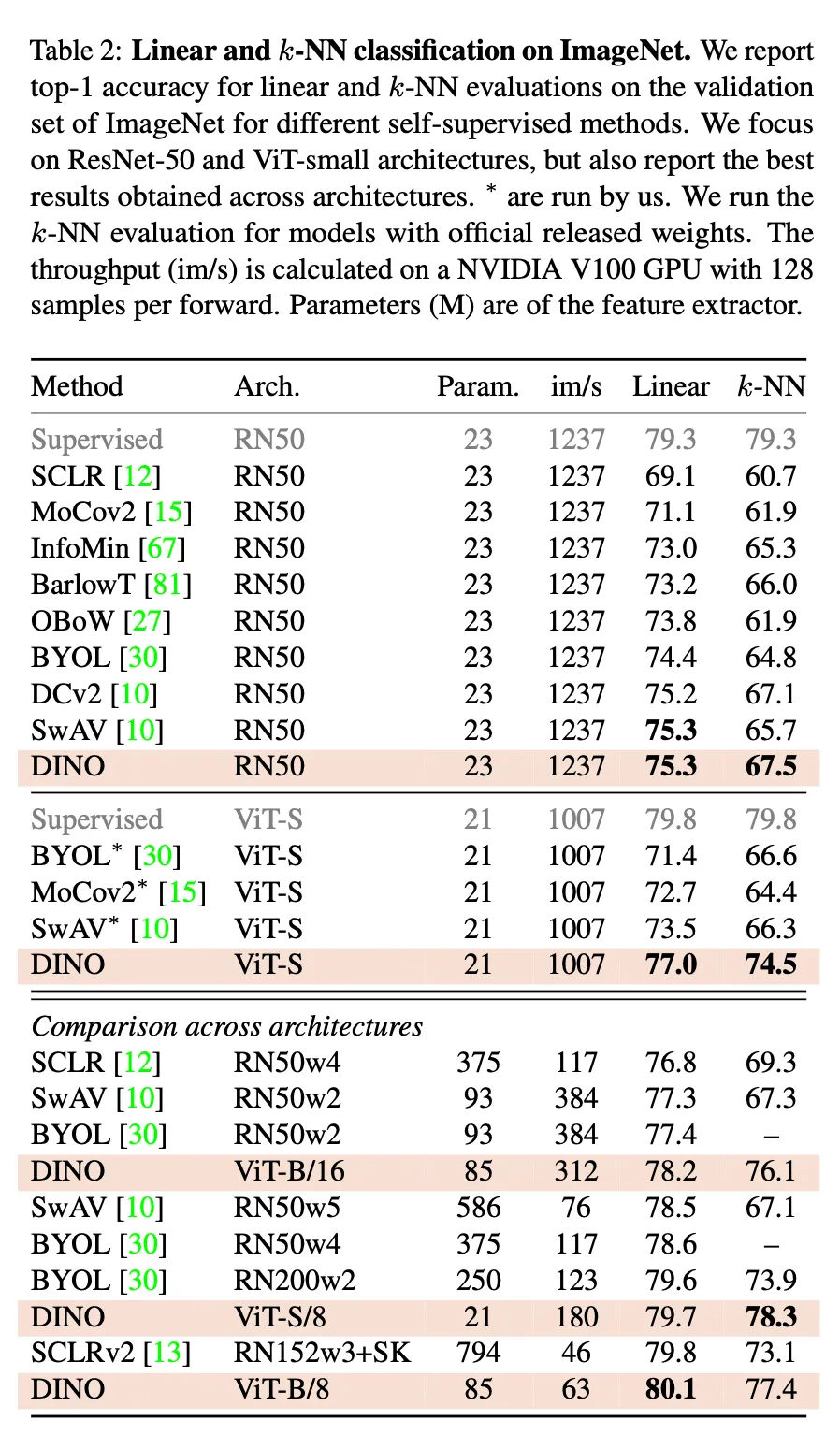
main results
•
Comparing with the same architecture / Comparing across architectures