
Abstract
test-to-image synthesis
이전의 연구들에서 부족한 점 : input text에서 불충분하게 표현된 특징에 대한 요소 혹은 학습한 적 없는 ( unseen ) 요소 에 대한 일반화가 부족했다
ex)인구통계학적으로 적은 그룹의 얼굴
이 논문에서는
•
StyleT2I라는 test-to-image synthesis에서 compositionality를 향상시키는 framework를 제안한다
•
CLIP-guided Contrastive Loss라는 다른 문장들에서 다른 요소들을 더 잘 식별하는 loss를 제안한다
•
compositionality를 더 향상시키기 위해 새로운 Semantic Matching Loss와 의도한 공간적 영역 조적을 위한 attributes의 latent directions를 확인하기 위한 Spatial Constraint을 제안
→ 더 잘 disentangled된 attribute의 spatial representations를 결과로 가져옴
•
확인된 latent directions of attributes에 기반해 Compositional Attribute Adjustment를 제안해 latent code를 조정하고, image synthesis에서 더 좋은 compositionality를 결과로 가져온다
•
추가적으로 image-text alignment과 image fidelity 사이의 균형을 맞추기 위해 식별된 latent directions(norm penalry)의 L2-norm 정규화(regularization)를 활용한다.
Introduction
Text-to-image 합성은 여러 분야에서 활용되고 있지만 compositionality라는 측면이 간과되고 있었다.
예시) “ He is wearing lipstick “ 그는 립스틱을 바르고있다.
이 문장의 (He, Lipstick) 이 attributes의 조합은 face dataset에서 underrepresented, 즉 충분하지 않게 존재한다.
이전의 방식들은 이러한 이미지를 정확히 합성하지 못한다. 아마도 overrepresented compositions에 overfitting되었기 때문일 것이다. 쉽게 말하면 데이터에 많이 존재하는 조합들만 잘 합성된다
overrepresented composition의 예시 : (”she”, “wearing lipstick”), (”he”, not “wearing lipstick”)
⇒ dataset 으로부터 얻게되는 biases / stereotypes
⇒ Severe Robustness and Fairness Issues 발생시킴
따라서 이러한 조합들을 그저 ‘암기'하는 것이 아니도록 해야한다.
이를 위해서
1.
큰 datast 으로 pretrain된 CLIP모델을 이용한 Loss 사용
2.
단어와 이미지의 연관성 보다는 각 특징을 disentangled 하는데 집중
했다고 한다.
다른 attributes의 disentangled representations로 compositionality를 향상! sentence내에 묘사된 각 attribute가 맞게 합성됐음을 보장할 수 있기 때문이다.
StyleT2I
backbone : styleGAN(StyleCLIP)
overview
1.
Text to Direction : CLIP guided Contrastive Loss로 학습 → ‘다른'요소를 잘 인식하도록.
norm penalty가 합성된 이미지의 fidelity를 유지시켜준다 ( 더 잘 합성되게 해준다 )
2.
compositionality 향상을 위해서 semantic matching Loss와 spatial constraint를 제안한다
→ disentangled attribute latent directions를 검증한다.
→ Compositional Attribute Adjustment와 함께 text-conditioned latent code를 조정하는데 사용된다
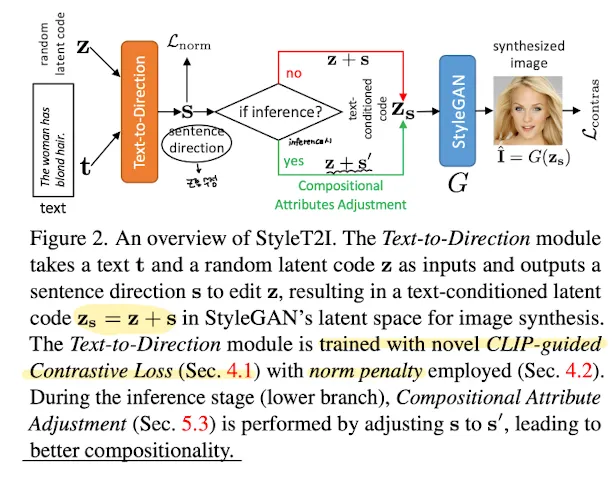
4. Text-conditioned Latent Code Prediction
이전 연구들에서 밝혀진 사실 : StyleGAN의 latent space의 latent direction은 attribute를 나타낼 수 있다.
attrubute의 latent direction을 가로질러 latent code를 횡행하는 것이 합성된 이미지의 attribute를 편집할 수 있다. 글ㅐ서 이 논문은 input text 내의 여러 attributes의 조합에 관련있는 latent direction이 존재한다고 가설을 세웠다 - (”woman”, “blond hair”) in “the woman has blond hair”
그래서 pretrained StyleGAN’s latent space에서 text-conditioned latent code를 찾는 것이 Text-to-Direction module이다.
Fig2에서 볼 수 있듯 Text-to-Direction module은 text 와 pretrained StyleGAN에서 랜덤하게 샘플링된 latent code 를 입력으로 받아 latent direction 를 output으로 가진다
⇒ 결과적으로 가 StyleGAN의 G에 input으로 들어간다.
synthesized image
text to direction : pretrained StyleGAN의 latent space에서 text-conditioned latent code를 찾는 모듈
4.1.CLIP-guided Contrastive Loss
Text-to-Direction 모듈은 input text로 정렬된 sentence direction을 예측해야한다. 그래야 단순히 training data의 조합을 암기하는 것을 피할 수 있다. 그를 위해 큰 dataset에서 pretrain된 CLIP을 사용했다.
pretrained CLIP: image-caption pair 데이터로 joint embedding을 배우기 위해 학습됨
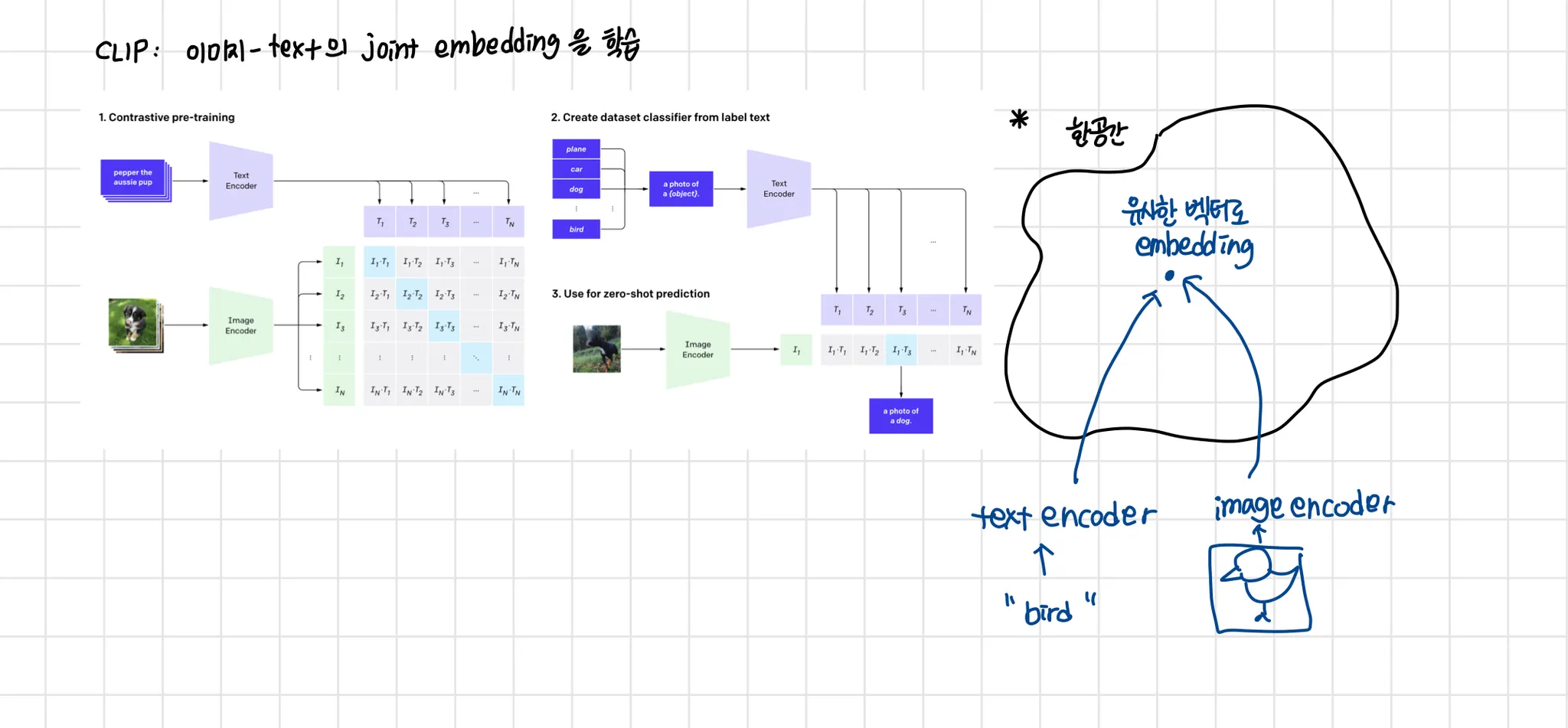
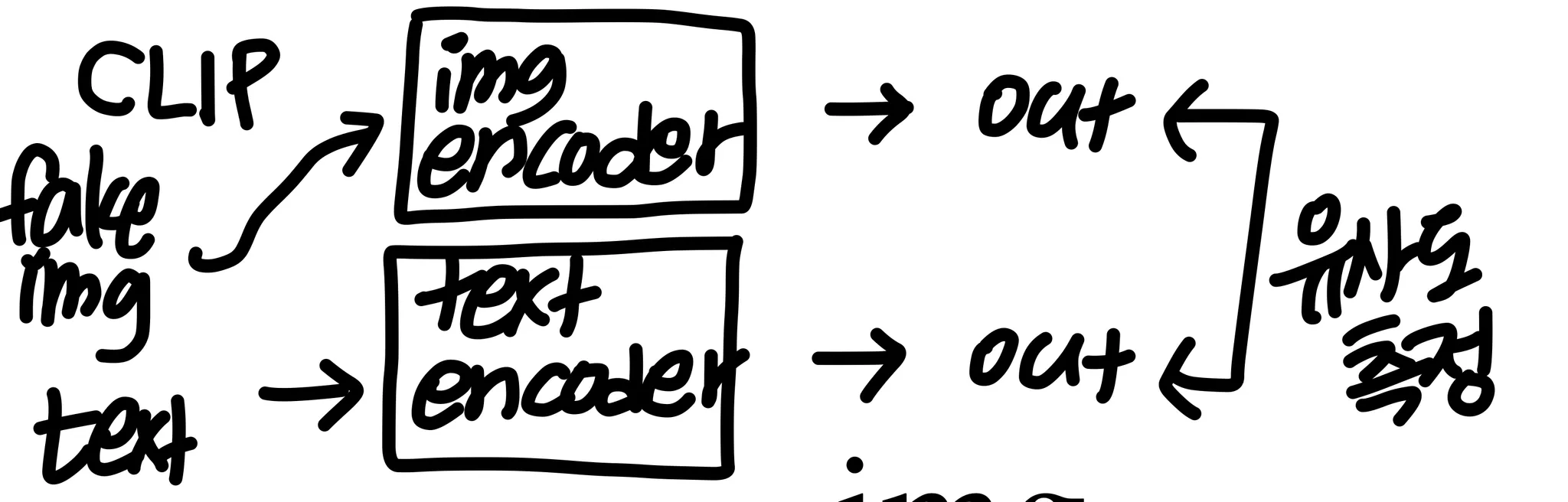
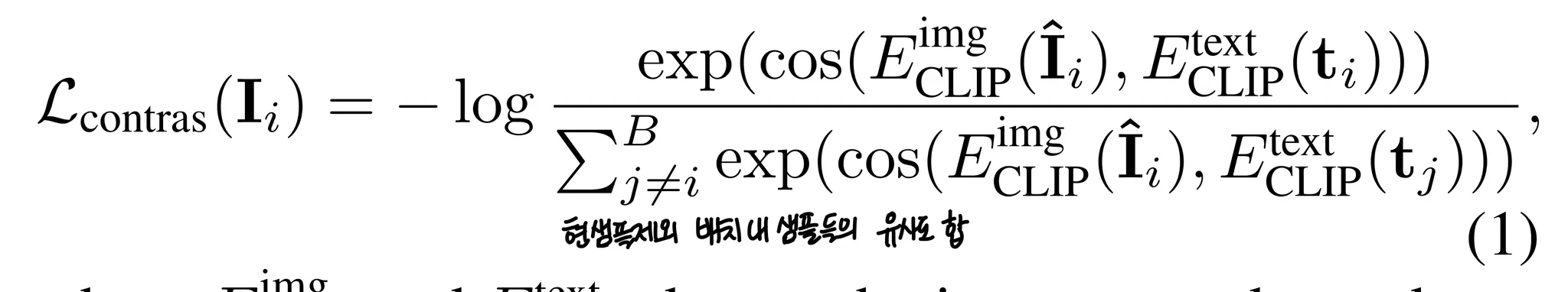
※ 내 해석
contrastive Loss 기반이기 때문에 결국 ‘차이' ‘유사도'를 기반으로 학습하겠다는 것이다.
유사도의 기준은 보통 거리가 되고, 거리는 predefined된다. 특정 metric을 기준으로 유사도를 잘 측정하기 위해 모델 파라미터들이 학습된다면 이는 해당 metric을 찾기 위한 manifold를 찾게 되는 것이다. 이것은 learned metric이 되고, deep metric learning이 된다.
예를 들어 의자정면 사진, 의자 측면이 있다고 할 때 이 두 사진은 임베딩 공간 내에서 거리가 짧아야 할 것이다. 이러한 임베딩 공간을 찾는 것이다.
이 모델에서는 fake image와 text의 거리가 잘 학습된 CLIP의 joint embedding공간 내에서 짧은 거리를 갖도록 학습된다고 할 수 있다.
이 Loss를 사용해
1.
input text 와 sentence direction 가 더 잘 정렬된다
2.
다른 texts의 다른 조합들을 더 contrast하게 한다 ( 더 차이가 나게 한다) 이 논문에서는 he is wearing lipstick과 she is wearing lipstick을 예로 들었다.
이를 통해 네트워크가 training data를 주로 지배하고 있는 조합들에 오버피팅되지 않도록 했다.
4.2. Norm penalty for High-Fidelity Synthesis
Text-to-Direction 모듈이 큰 으로 를 예측하기 때문에 가 low-density 영역으로 이동하게 해 이미지 뭘리티를 낮아지게 했다고 한다(정확히 무슨의미인지 잘 모르겠다)
그래서 sentence direction 의 을 penalize했다.
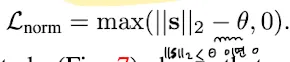
s의 l2norm이 너무 클 때 Loss에 penalty가 생기게 되는것

5. Compositionality with Attribute Directions
5.1. Identify Attribute Directions via a Semantic Matching Loss
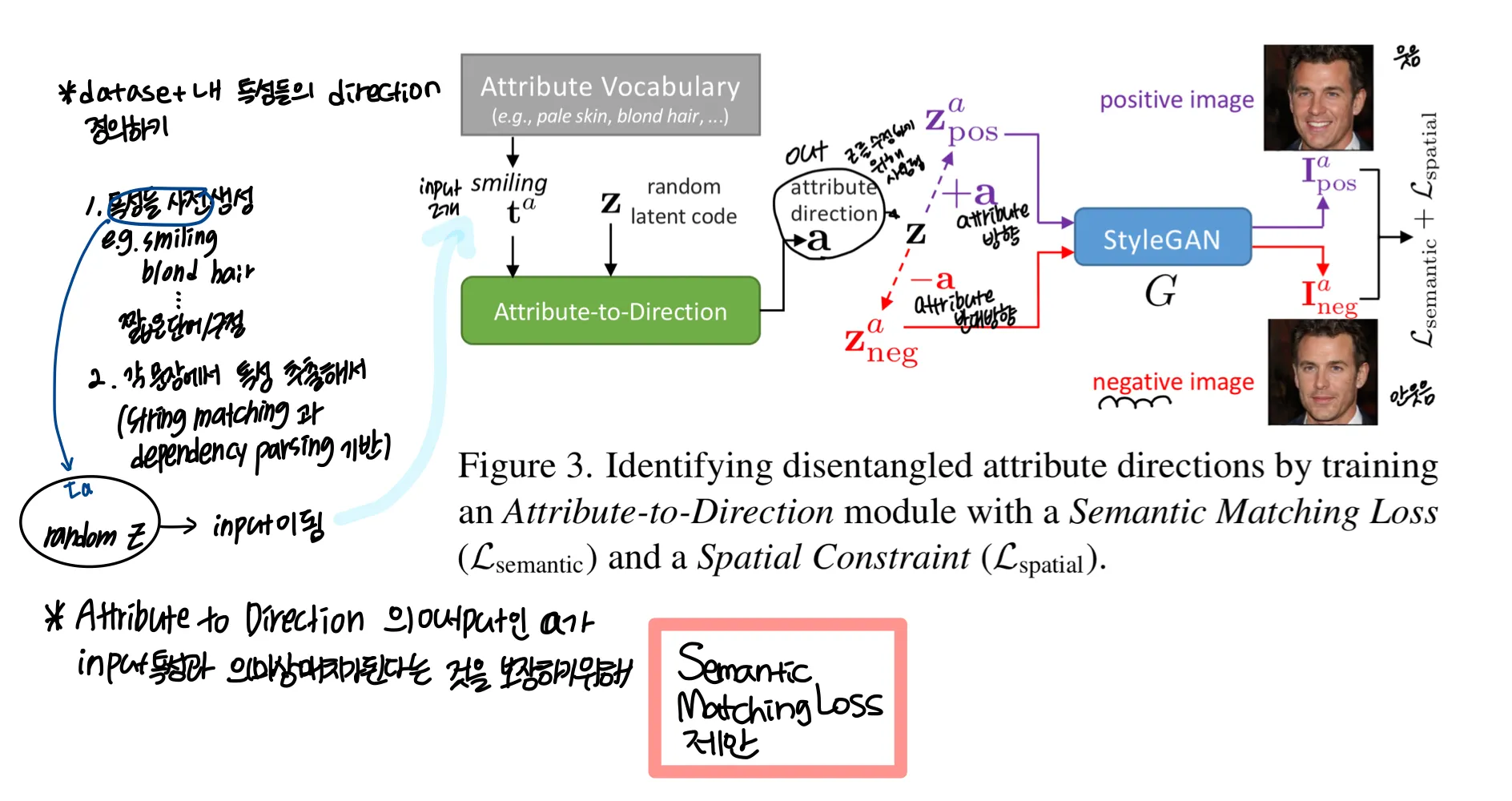
그림에서 output 는 smiling이라는 attribute를 나타내는 방향이다.
latent code 에 + 를 하면 웃는 방향이 될 것이고, - 를 하면 반대로 안 웃는 방향이 될 것이다.
이를 각각 , 라고 정의한다.
이 둘을 각각 StyleGAN에 넣어 나온 결과를 , 라고 정의하면
와 text의 관계는 커야하고, 와 text의 관계는 작아야한다. 이를 이용해 을 정의한다 → Semantic Matching Loss
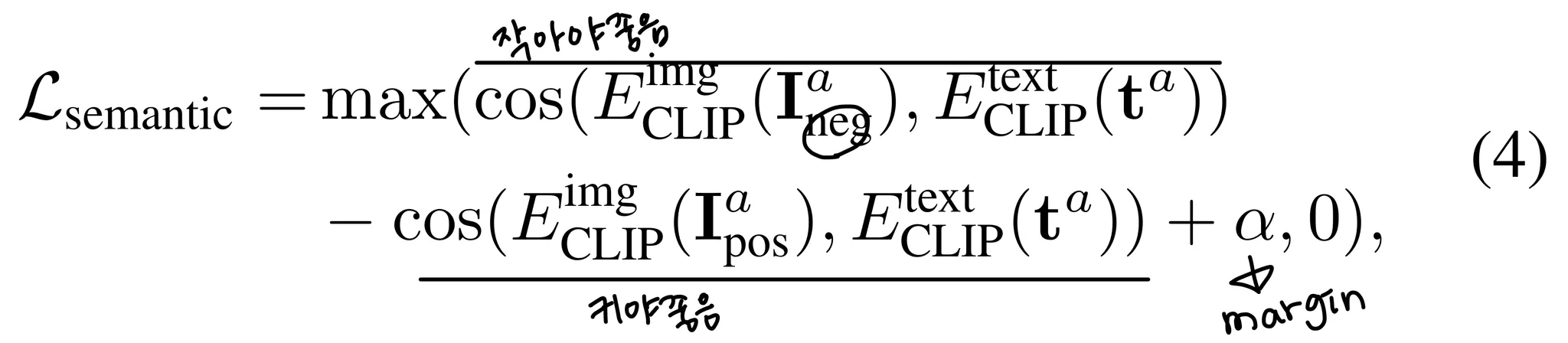
보면 positive와 text의 관계가 negative와 text의 관계보다 이상 높으면 Loss는 0이 되게 된다. 이정도 차이가 나면 잘 학습 된 것이라고 판단하는 듯 하다
5.2. Attribute Disentanglement with a Spatial Constraint
이 부분은 “한 특성” 에서 그 반대가 그 반대 방향을 갖는지 확인할 수는 있으나 “다른 특성” 과 겹치지 않는지는 알기 어렵기 때문에 Spatial Constraint를 사용했다고 한다
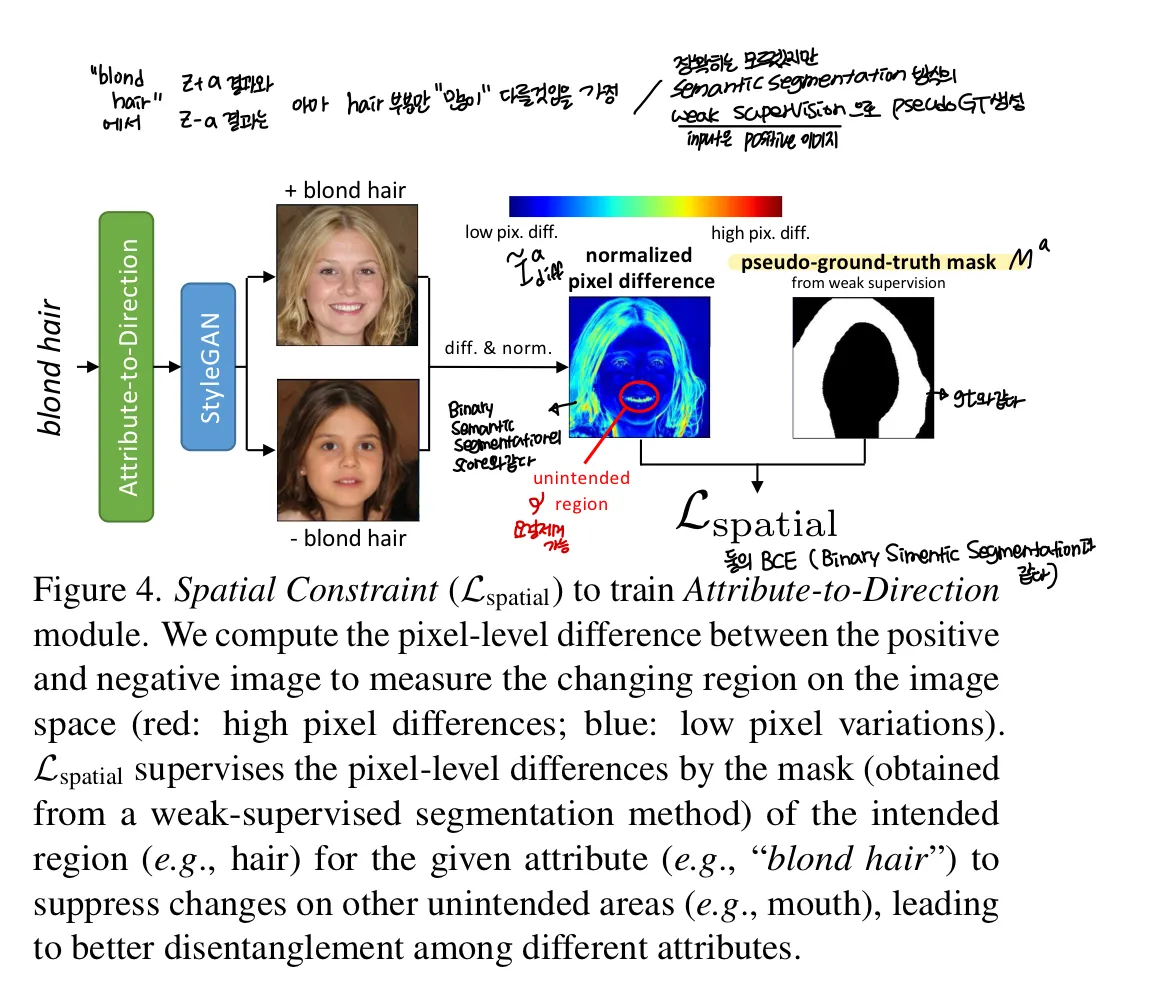
그림을 보면 blond hair에 대해서는 머리부분만 달라야하는데 입부분도 다른 것을 볼 수 있다. 따라서 positive 와 negative 사이 공간적 차이를 “원하는 영역만" 알기 위해
1.
픽셀 차이를 계산한다 (L1 distance)
2.
minmax normalization으로 0~1사이 값으로 변환한다. ( )
3.
positive image를 weakly supervised segmentation방식으로 하여 pseudo-ground-truth mask를 생성한다.

이 방식으로 Attribute-to-Direction 모듈이 attribute direction이 이미지의 원하는 영역을 수정할 수 있도록 예측하는 것을 강제한다!
5.3. Compositional Attribute Adjustment
Compositional Attribute Adjustment(CAA)의 목적은 합성 결과의 compositionality를 보장하는 것이다.
주된 아이디어는 two-fold이다.
1.
sentence direction 에서 attribute를 확인한다
2.
잘못 예측한 attribute를 확인한다
이 둘을 합쳐서 correction한다.
inference시에는 latent code 를 sampling한 후 Text-to-Direction module로 보내 input text 로부터 sentence direction 를 얻는다.
동시에 sentence 로부터 K개의 attribute 를 추출한 후 와 함께 attribute to direction 모듈로 보낸다. 거기서 attribute directions 를 얻는다. K는 하이퍼파라미터가 아니고 centence에 묘사된 attributes의 수로 결정되낟. 그리고 두 모듈에 들어가는 는 동일하다.
attribute directions에 기반해 sentence direction을 s에서 s’로 조정한다.
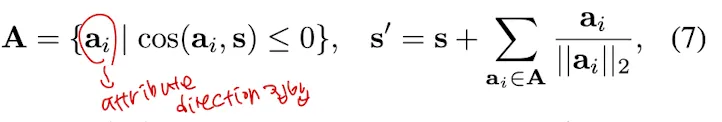
는 attribute directions 집합이고, sentence direction과 zero cosine similarity와 같거나 적다.
≤ 0 이면 sentence direction 는 i번째 attribute direction 와 agree되지 않고(맞지않음) 는 input text의 i번째 attribute를 나타내는데 실패한 것이다.
i번째 attribute direction 를 더해줌으로써 adjusted sentence direction 는 i번쨰 attribute에 대해 corrected 된다. 그래서 latent code 를 수정하는 는 새로운 text-conditioned code 로 대체된다→ final image 합성에 사용되고 text-to image 합성의 compositionality를 향상시킨다.
