
Abstract
vision task에서 오랫동안 CNN이 지배적이었지만 최근 ViT 계열의 Transformer-based 모델들이 뛰어난 성능을 보이고 있다. 그러나 ViTs는 Patch embedding이 필요하다. self-attention의 연산량 때문이다. 픽셀들을 모두 그대로 넣어준다면 감당할 수 없을 것이다. 여기서 이 논문은 의문을 제기한다.
•
ViT의 성공이 정말 Transformer의 구조 덕분인가? Patch representation 사용 때문이 아닐까?
이 의문에 대한 증거를 이 논문에서 제시하며 ConvMixer라는 ViT와 MLP-Mixer에서 영감받은 새로운 아키텍쳐를 제안한다.
ConvMixer는 input에서 패치들을 연산하고 spatial dimension과 channel dimension의 mixing을 분리한다. 그리고 네트워크 전반에서 같은 size와 resolution을 유지한다.
ConvMixer는 오직 일반 convolution 연산만을 사용한다. 단순한 구조에도 ViT와 MLP-Mixer의 성능을 뛰어넘었다.
Introduction
NLP에서처럼 vision에서도 ViT구조가 주가 되는 것은 시간문제로 보이나 이미지의 경우에는 self attention의 연산량 때문에 변화가 필요했다. 바로 patch embedding이다.
이 논문에서는 vision transformers의 성능이 transformer 구조 그 자체에서 온 것인지 patch-based representation에서 온 것인지를 분석한다. 그리고 매우 간단한 convolutional 아키텍쳐 “ConvMixer”를 제안한다. 이는 ViT와 MLP-Mixer와 많은 점에서 유사하다.
1.
patch단위로 연산된다는 점
2.
모든 레이어에서 같은 해상도와 사이즈(채널을 의미하는 듯 하다)를 유지한다. (downsampling x)
3.
information을 channel-wise mixing과 spatial mixing으로 분리한다.
그러나 오직 convolution연산으로만 이루어져 있다는 것이 다른 점이다.
ConvMixer아키텍쳐의 실험결과를 ResNets와 ViT, MLP-Mixer와 비교하지만 ConvMixer는 accuracy나 speed를 위해 설계한 것이 아니다 ( 오직 patch embedding의 영향에 대한 분석을 위해 설계)
또한 patch embedding과 다른 요소들의 영향을 분리하기 위해서는 더 많은 실험이 필요할 것이라고 한다.
A Simple Model : ConvMixer
ConvMixer : Patch Embedding Layer + fully convolutional blocks
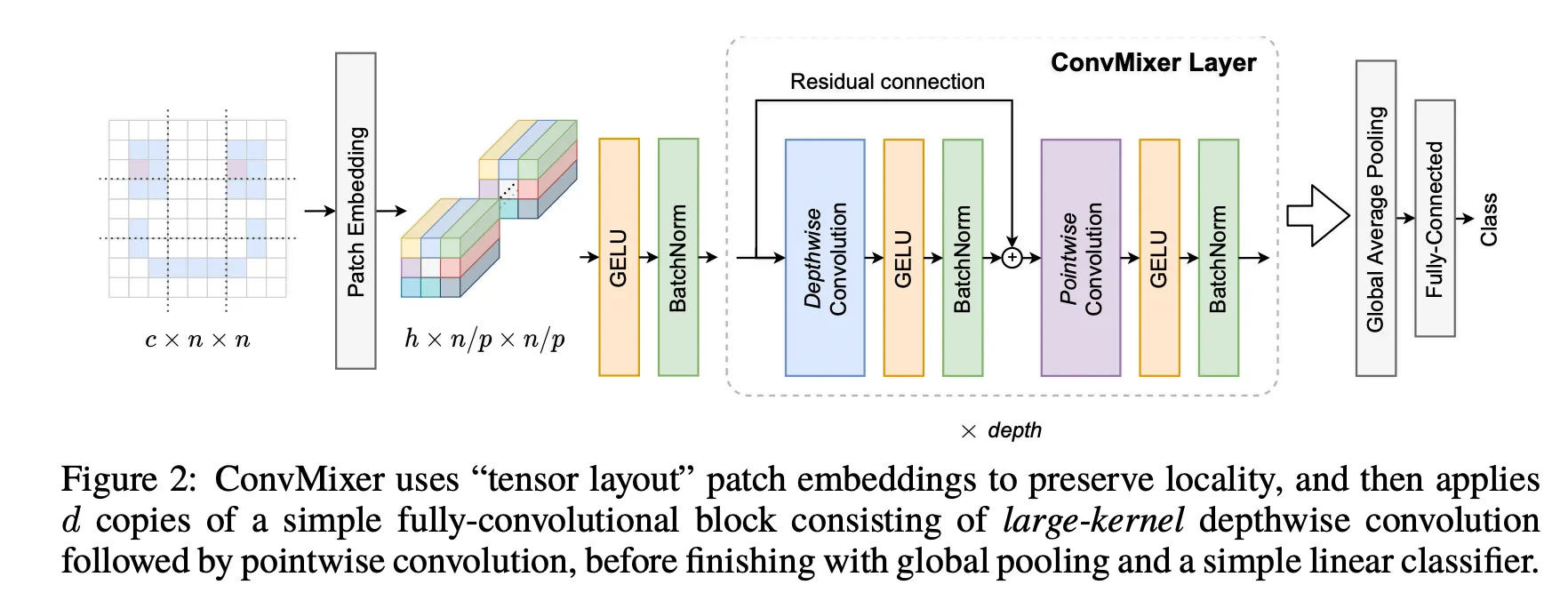
•
: dimension ( output channels )
•
: patch size
•
: input channels
•
: original input size
Fig. 2를 보면 알 수 있듯이 기존 ViT와 같은 Patch Embedding 수행 후 Activation - BatchNorm을 수행한 후 ConvMixer Layer에서 [Depthwise conv - Activation - BatchNorm] → Residual Connection → [pointwise conv - Activation - BatchNorm] 을 수행한다.
acivation function으로 GeLU를 사용한 것과 Normalization 이전에 Activation을 수행해 주는 것은 Transformer의 구성을 따라간 것으로 보인다.
Design parameters
ConvMixer는 4개의 파라미터들을 지정해주어야 한다.
1.
: width / hidden dimension
2.
: depth
3.
: patch size
4.
: kernel size (of depthwise convolutional layer)
논문에서 ConvMixer의 variations를 ConvMixer-/로 표현하였다.
Motivation
기본적으로 MLP-Mixer의 아이디어에서 착안한 것으로, depthwise convolution을 spatial locations를 mix하는 것으로, pointwise convolution을 channel locations를 mix하는 것으로 선택했다.
사실 이러한 개념은 Xception, Mobilenet v1, v2등에서 사용된 depthwise-separable convolution과 매우 유사하다. 이를 transformer의 개념에 연결한 것으로 보인다.
key idea는 MLP와 self attention은 먼 spatial locations를 mix할 수 있다는 것이다. 큰 receptive field를 가지기 때문에 depthwise conv의 kernel size를 크게 설정했다고 한다.
self-attention과 MLP가 이론적으로는 더 유연하고 더 큰 receptive fields를 가지며 content-aware 하게 작동함에도 convolution의 inductive bias는 vision에 적합하며 데이터 효율이 좋다.
이 논문에서는 pyramid-shape(feature가 점점 downsample되는) CNN과 patch representation의 효과도 비교해본다.
Experiments
training setup
•
ImageNet-1k classification에서 평가했다. (pretraining이나 추가 data x)
•
RandomAugment, mixup, CutMix, random erasing
•
gradient norm clipping
•
AdamW
•
hyperparameter tuning 하지 않았고, 비교모델들보다 적은 epoch로 학습했다
Results
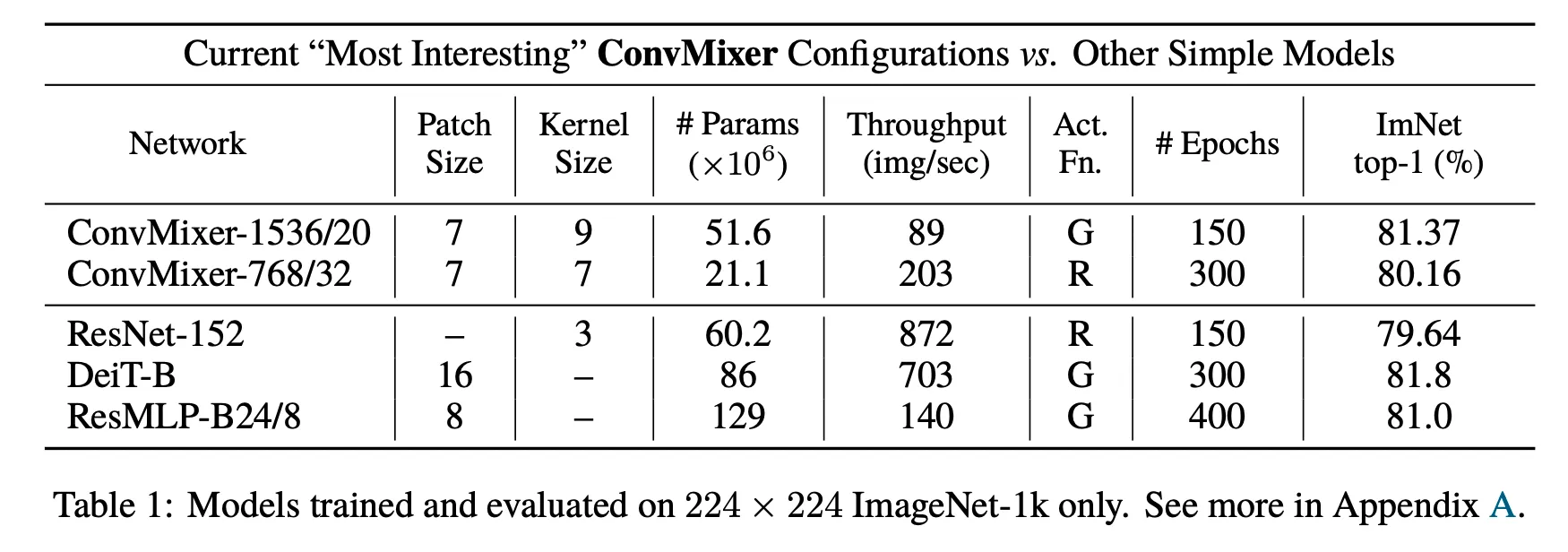
•
kernel size는 클수록, patch size는 작을 수록 성능이 좋았다.
•
GeLU와 ReLU사용의 차이는 크지 않았다.
•
패치가 크면 depth가 더 요구되는 것으로 보인다
Conclusion
patch embedding을 사용하는 “isotropic” architecture(피쳐의 해상도가 동일하게 유지) 가 그 자체로 얼마나 powerful한지 증거를 제시한다.
patch embeddings는 모든 downsampling이 한번에 일어나도록 하고 바로 internal resolution을 감소시켜 effective receptive field size를 증가시킨다. 이는 distant spatial information을 mix하는 것을 쉽게 만든다.
결론은, self-attention 뿐 아니라 Patch embedding그 자체가 매우 강력하고 중요하다.
