
single image 관련 내용을 주로 정리했습니다! video deblurring관련 부분은 많이 생략했습니다
dynamic scene motion deblurring을 해결하기 위한 모델을 제안한 연구이다
high resolution processing과 multi resolution feature aggregation method가 합쳐진 네트워크 구조를 제안
single frame 및 video deblurring 을 위한 네트워크 제안
[2 stage 로 이뤄져 있다]
stage 1
•
multiple atrous convolution in parallel
•
각 3개의 convolution 에서 atrous rate를 조심스럽게 조절했다. input의 rectangular area를 완전히 커버하기 위해
•
이 방법으로 high spatial resolutrion에서의 large receptive field를 얻을 수 있었다
stage 2
•
multiple consecutive frames of a video sequence 여러개의 연속된 비디오 시퀀스의 프레임들을 결합
•
high resolution을 유지하면서 multi resolution features를 사용한다. 이미지 간 객체들의 큰 움직임의 영향을 완화시키기 위해
NTIRE2020 single image 1등, video deblurring 4등 차지한 모델
Introduction
Image capture에서 모션블러는 매우 보편적이고 눈에 띄는 artifacts 이다
Blurred images는 computer vision application에서 문제가 될 수 있습니다
일반적 CNN : downsampling layers → expand internal receptive field
여기서 입력의 더 크고 의미론적으로 더 의미 있는 영역에서 특징을 추출하기 위해, 많은 방법은 일종의 서브샘플링을 사용한다. → 보통 maxpolling 이나 average pooling 같은 pooling operations
motion deblurring 같은 image to image task같은 경우에는 full input resolution에서의 dense spatial output이 요구됨
이러한 task에서 subsampling을 사용하면
subsampling → loss of spatial information → negative effect
또한 downsampling으로 인한 spatial dimension의 변화로 downsampling레이어 이후에는 보통 upsampling layer가 따라온다 spatial dimension을 회복하기 위해
현대의 upsampling 기술( deconvolution ) → checkerboard artifacts( eneven overlap ) → image-to-image 모델의 심각한 성능 저하
이를 극복하기 위해 지금까지는 단순히 업샘플링 레이어가 많이 필요하지 않도록 down-sampling의 대부분을 제거하였다
image deblurring에서의 atrous convolution(==dilated convolution)의 사용에 대해 분석한다
이미 다른 dense-prediction task에서는 이미 효과적이라 알려져있다.( e.g. semantic segmentation )
파라미터 증가 없이 kernel이 커버하는 spatial area를 증가시킴
[contribution]
1.
큰 receptive field 얻기 위해서 atrous convolution을 매우 많이 사용하는 high-resolution model 제안. 그리고 그를 통해 단일 이미지 디블러링에 대한 SOTA performance달성
2.
Multi-Level Feature Aggregation method for video deblurring 제안. 이는 single image performance도 향상
3.
ablation study를 통해 high-resolution 우리의 out-performane의 주된 요인임을 입증한다
Related Work
Image deblurring with CNN
CNN 사용한 최근의 image deblurring 접근들
•
encoder-decoder
•
multi-scale networks
이 네트워크들은 전형적으로 최소 3개의 다른 해상도를 내부적으로 이용
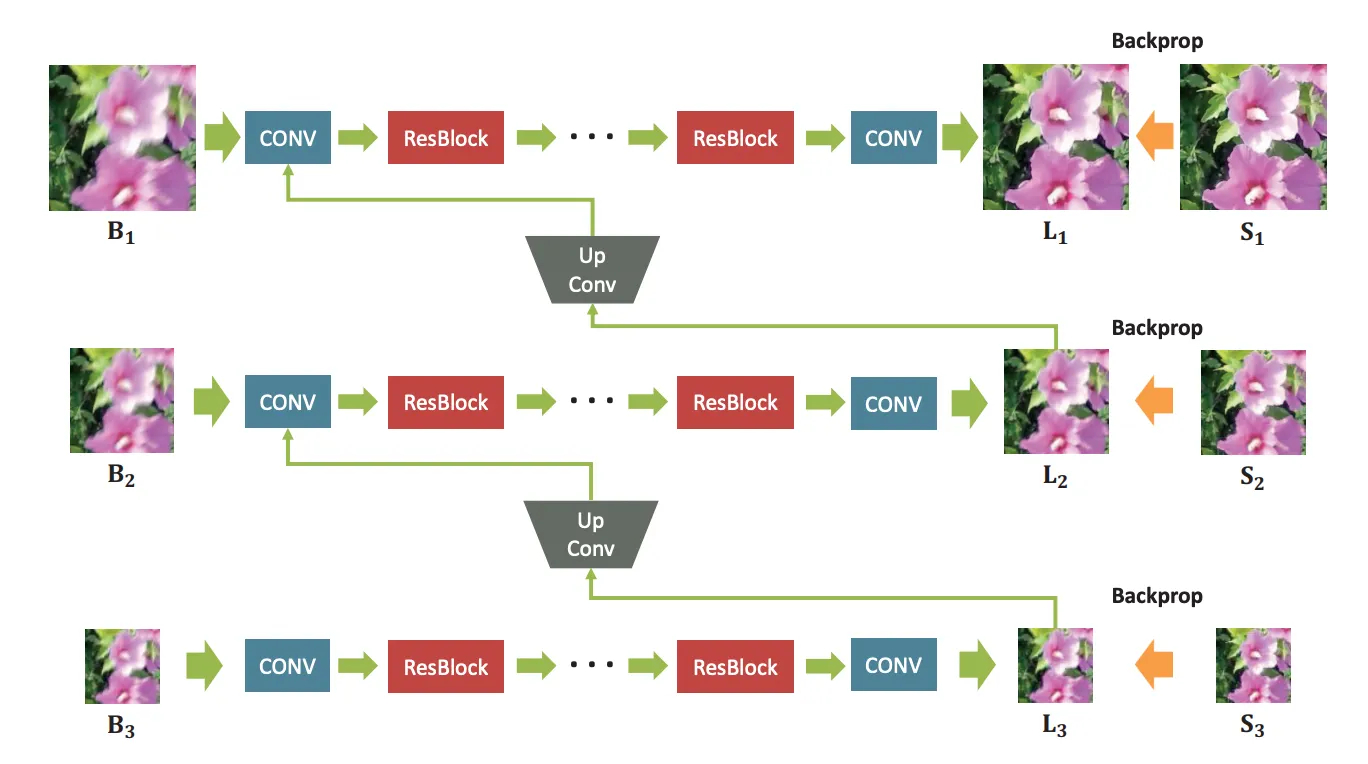
이 그림처럼 blurred image pyramid를 input으로 사용하고 residual blocks를 모든 레벨에서 사용했다
output 또한 피라미드 형테이고 모든 레벨에서 복원된 이미지들이다
[36]의 경우는 encoder-decoder residual blocks를 사용했고 deep features의 upsampling과 downsampling을 residual connection으로 대체했다

그렇게 해서 receptive field를 키우면서 high resolution representation을 지킬 수 있었다.
대조적으로 우리는 네트워크 전체에서 high-resolution representation을 유지하기 위해 하나의 downsampling 작업과 하나의 upsampling 작업을 제외한 모든 것을 생략합니다.
Atrous convolution
single convolution kernel의 receptive field 크게 함
[4, 38, 32] spatially-dense task에 효과적
semantic segmentation에 적용하기도
[38]은 고해상도 결과를 요구하는 작업의 경우, 네트워크 전체의 high-resolution operation이 실현 가능하고 유망하다는 것을 보여주었다. - semantic segmentation에 적용
[42]의 경우 cascaded atrous block을 사용했고, standard residual blocks와 비슷해보인다
그러나 다른 atrous rate(1, 3)을 갖는다

이러한 1과 4라는 atrous rate setting은 모든 픽셀을 완전히 커버하지 않는 receptive field를 초래
down/up sampling 레이어 없는 네트워크들과 atrous settings통한 resonable한 receptive field 가 더 적은 trainable parameters로 Unet보다 성능이 더 좋을 수 있음을 보여준다
[이후 video deblurring 관련 내용 생략]
3. Methology
•
two stage
first stage : single image blur 제거
second stage : 이미지 시퀀스의 다른 features를 align.( 결과 개선 위함 )
•
이미 어느 정도 흐려진 이미지에서 spatio-temporal information 의 aggregation 이 더 쉽다고 주장
•
특히 심하게 흐릿한 이미지의 경우, 다른 연속 프레임의 details을 집계하는 것은 매우 어려울 수 있습니다.
그러므로 두 개의 다른 네트워크로 구성
◦
하나는 하나의 이미지만 흐리게 하는 작업이고
◦
다른 하나는 first stage부터 features of predictions을 집계하는 작업이다.
Stage 1. Single Image Deblurring
single image deblurring model에서는 atrous convolution으로 downsampling을 피하려고 노력
atrous rate를 설정하는 준 방법은 없으나 적절한 atrous rate을 선택하는 것은 perfomance에 매우 중요하다.
Atrous Rate Setting
다른 atrous rate를 가진 multiple parallel convolution 제안
각 convolution layer가 주어진 viewing distance에 대해 특정 파라미터를 학습할 수 있게 함
그러므로 multi-scale approach 를 spatial resolution 감소 없이 수행한다
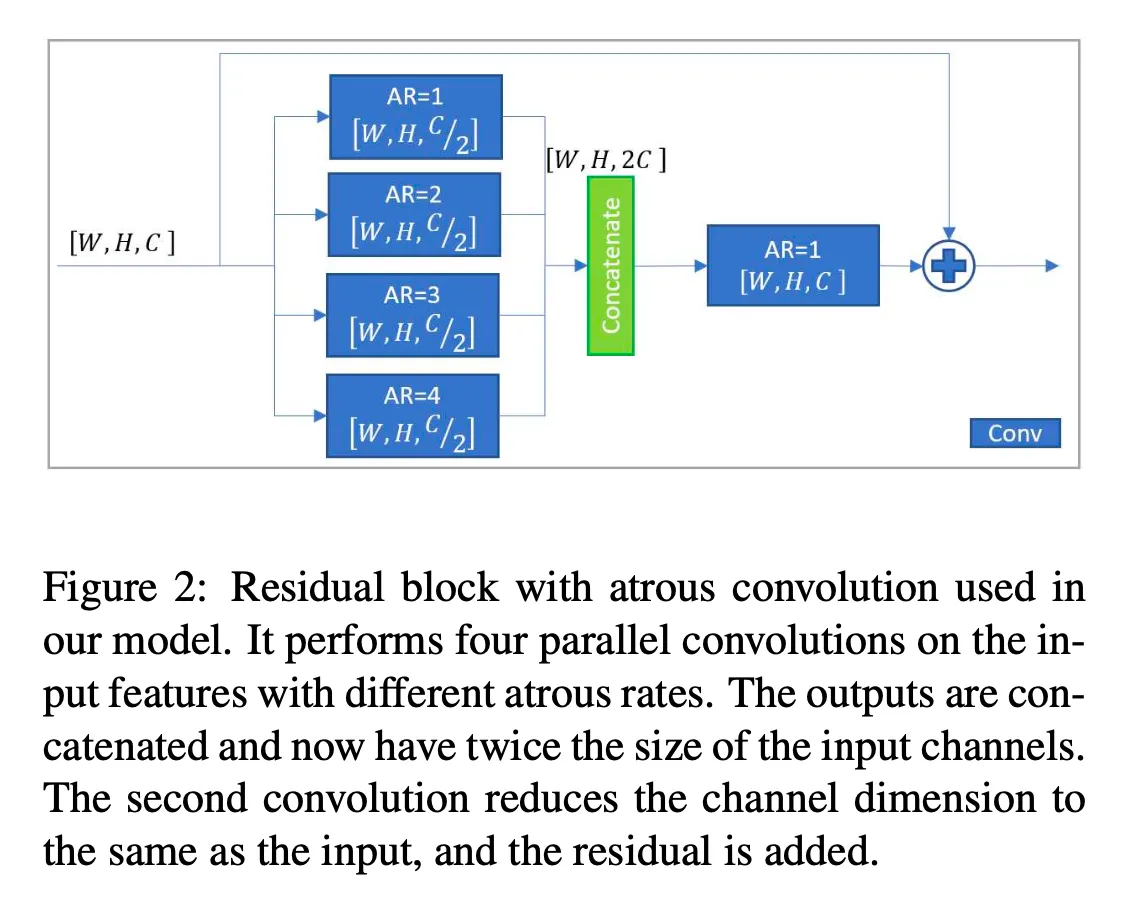
각 block은 4개의 3 × 3 convolutions 을 수행.
•
in parallel with 128 filters each and atrous rates of 1, 2, 3 and 4
[WRCA와 비교]
•
4개 atrous conv 결과를 concatenate → 512 featuremaps로 이뤄짐
•
그 후에 또다른 3x3 conv(AR=1이면 일반 conv) 적용해 이 피쳐들을 합치고 feature map 수를 256으로 줄임
•
이 output에 input을 더함 ( shortcut )
이것에 대한 직관은 residual block에서 feature depth를 확장시키는 것이 더 많은 information이 전달될 수 있도록 해준다는 것이다.→ 성능 향상
각 atrous block은 11x11의 receptive field를 갖는다
블록들을 쌓음으로써 receptive field가 계속해서 증가한다

Fig3은 parallel convolution with atrous rate 1, 2, 3, 4 이후를 각각 시각화한 그림
(a)와 마지막 3x3 conv 이후의 receptive field (b) 사이의 missing gaps
결과적으로 receptive field가 거의 정사각형에 가깝다
비슷한 모양의 receptive field는 5개의 순차적인 convolution layer( kernelsize 3x3, atrous rate 1 per residual block)으로 얻을 수 있다.
이러한 설정(일반 conv로 비슷한 receptive field 얻은 경우)에서 모든 convolution layer는 receptive field가 layer to layer로 증가함에 따라 증가하는 영역의 정보를 통합합니다.
우리의 접근(일반 conv 아니라 atrous conv를 병렬로 사용한 방법)은 각각의 레이어가 특정 viewing distance를 specialize할 수 있게 한다
이는 input features를 subsampling하고 multiple scales에서 convolution 적용하는 것과 유사하다 ( 뭐 여러 크기의 피쳐맵에서 conv 적용하는거랑 비슷하다 그런말로 이해하면 될 것 같다)
이러한 방법으로 high-resolution 정보를 보존하면서 multi scale processing을 수행!
마지막 conv layer는 모든 블록에서의 output을 합치고
fig3이 kernelsize 3x3이 탁월한 선택임을 보여준다 왜냐하면 input features를 거의 완전히 square receptive field를 채우는 방향으로 합치기 때문이다
각 pixel들에 대한 resulting weight는 fig3의 색의 강도로 나타난다. 뭐 얼마나 많이 반영되는지 그런거 말하는 것 같다( kernel들에 의해 여러번 반영되는 픽셀도 잇을거니까 )
[42]논문의 경우 모든 픽셀이 weighted equally되었지만 receptive field의 중심에 더 많이 가중치가 주어질수록 image deblurring에 beneficial 하다
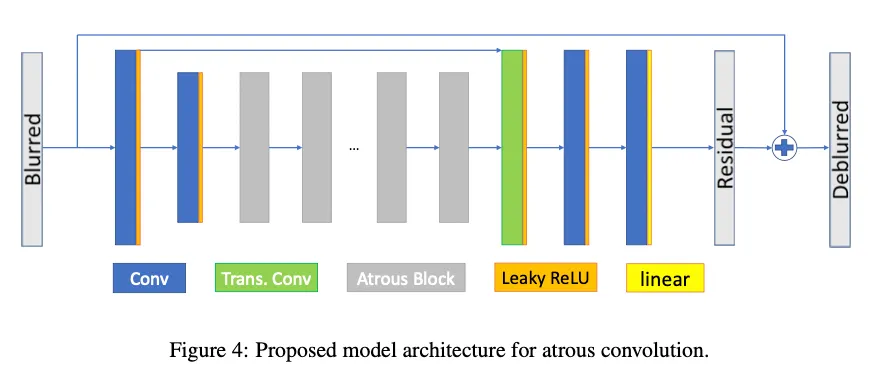
Fig4는 first stage의 아키텍쳐 overview
1.
2개의 연속된 convolution layer
a.
첫번째 conv레이어는 큰 conv kernel 사용 → 9x9크기 → low level features 추출
b.
두번째 conv 레이어는 2 stride, kernelsize 3x3 인 strided conv로 downsampling
2.
총 20개의 proposed atous residual block → 반복적으로 receptive field의 크기 늘림
3.
single deconvolution + 2개의 일반 conv 로 upsample 수행
output은 blurred input에 더하는 residual image가 된다( blurred에서 blur성분을 빼는 것으로 생각하면 될 것 같다)
RED datasets 이미지들의 high resolution과 NTIRE 2020 실험에 한정된 시간 때문에 single downsampling 레이어를 사용했다고 한다.

3.2. stage 2 - Video Deblurring
first stage의 Qualitative 분석은 미세한 질감이나 표정과 같은 많은 세부 사항이 다른 이미지들에서 똑같이 잘 복구되지 않는다는 것을 보여주었다.
reconstruuction quality와 consecutive frames 간의 큰 local differences들을 관찰
그런 경우 우리는 stage1에서의 deblurring을 multiple neighboring images의 정보를 aggregating함으로써 개선이 가능했다
하지만 카메라의 움직임과 scene에서의 객체의 움직임에 의존하고 image contents간의 관계성을 찾는 것은 CNN에게 있어 매우 어렵다
이것은 주로 convolution의 local operation 때문이다
object가 프레임간에 너무 많이 이동을 했다면 추가적인 정보를 이용하는 것은 거의 불가능하다
이 problem에 우리는 multi level feature aggregation(MLFA) 로 접근했다
CNN feature space의 다양한 resolution의 연속적인 프레임들에서 정보를 aggregate함
이를 통해 고해상도 세부 정보를 유지하면서 낮은 해상도로 장거리에서 정보를 수집할 수 있습니다.
Network Architecture
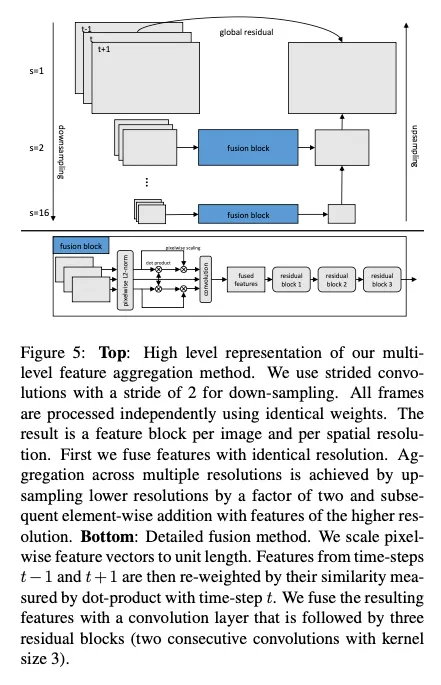
Fig 5는 second stage model의 high level architecture를 보여준다
video data를 3개의 phase에서 categorized되게 처리함
1.
feature extraction
2.
intra-resolution feature aggregation
3.
inter-resolution feature aggregation
뭐 비디오니까 이전 이후 프레임 정보 섞는 과정..! [생략]
3.3. Experimental Framework
Dataset
•
REDS dataset(NTIRE2020)
300 videos with 100 images
720 x 1280
240 videos training
30 videos validation
30 videos test
blurred images는 high frame rate 카메라의 여러개의 sharp frames가 겹쳐져서 만들어졌다
•
GOPro dataset
standard benchmark for evaluation of deblurring algorithm
3214개의 blurred and sharp images 쌍 가지고 있음
REDS 와 같은 image resolution가짐
REDS dataset처럼 GOPro dataset도 합성으로 만들어진 single image 혹은 video deblurring 데이터셋이다
optimization
Adam optimizer
initial learning rate 0.0001
= 0.9 , =0.999
학습과정마다 10 의 factor로 lr 줄임 ( 10씩 나눴다는 말같다 )
validation 에서 훨씬 더 오래 지연되었다. 우리는 서로 독립적으로 약 250만 개의 반복을 위해 1단계와 2단계 모델을 모두 훈련시켰다.
data augmentation and preprocessing
random image를 320x320으로 잘라서 학습
이것은 주로 전체 크기의 이미지를 사용할 때 엄청난 런타임과 메모리 소비 때문입니다.
image brightness, hue, saturation, contrast를 조금씩 모든 이미지 크롭에서 다르게 했다
50% 비율로 flip 과 rotate도 적용
이 augmentation 조합들 때문에 학습동안에 완전히 똑같은 이미지를 두번 얻는것은 어려웠음
모든 이미지들은 -1~1로 normalize각 mini batch는 2단계 모델의 다른 이미지에서 가져온 2개의 random image crops로 이뤄져있고 stage 1모델에는 batchsize 1 사용
Training Objectives
stage 1과 stage 2 모두를 학습시키는 것은 pixel-wise absolute error in RGB space로 가이드되었다.
두 스테이지 모두에서 현재 time step t를 라벨로 RGB이미지를 사용했다
하지만 우리는 예비 실험에서 다른 error formulations로 했는데
이 실험들을 위한 baseline model은 PSNR 32.3dB, SSIM 0.901 을 얻어냈다
이 실험들의 전부는 single image deblurring 세팅에서 이뤄짐
adversarial setting에서 pixel-wise task를 학습한 GAN은 최근 유명함
하지만 우리의 실험은 쓸만한 결과가 안나왔다
우리는 다양한 discriminator 아키텍쳐들과 다양한 GAN formulations( StandardGAN, LSGAN, Relativistic Average LSGAN 등 ) 을 시도해봤지만 의미있는 것으로 수렴한 것이 없었다
[16]논문에서도 추가적인 perceptual loss를 더하지 안혹서는 GAN based 접근은 수렴하지 않았다함
[16]에 대비해 우리는 29.00dB PSNR과 0.869 SSIM으로 수렴하는 모델을 학습시킬 수 있었다 . absolute error와 결합한 StandardGAN이었다.
이것은 여전히 우리의 baseline( 32.3dB PSNR, 0.901 SSIM) 보다 꼬ㅒ 별로다
[VGG]
우리는 perceptual loss를 VGG16의 conv3_3 layer를 기반으로 더했다.( ImageNet pretrained )
resulting model은 학습동안에 파라미터 업데이트 수의 측면에서 더 빠른 수렴을 보여줬다.
하지만 우리는 PSNR과 SSIM 측면에서 어느 향샹도 볼 수 없었다.
[Edge]
Edges는 매우 중요하다 시각적으로 만족스러운 복원을 위해서
이를 강조하기 위해 우리는 우리의 baseline을 추가적인 absolute error between the edge of output image 와 sharp image의 edge를 시도했다
그러나 더 안좋았음 31.32dB PSNR, 0.880 SSIM
It is commonly known that both adversarial and percep- tual loss improve visual quality at the cost of quantitative performance measured by PSNR and SSIM [1].
이렇게 언급한 예비실험에 대한 질적분석은 하지 않았다고 함
Other Details
모든 reported models에서 우리는 Leaky ReLU사용했다
모든 convolution layers 에서. output 레이어 제외하고
여기서, 우리는 lineaer activation fuction을 사용했다
test time에서 우리는 단순히 output을 correct range of values로 clip했다
전통적 ReLU에 매우 유사함에도 불구하고 Leaky ReLU는 우리가 validation성능에서의 계속되는 향상이 있는 시간이 길어지게 해줬음
이것은 아마 dying ReLU문제에 고통받지 않기 때문일 것이다 왜냐면 zero slope part가 없어서
대조적으로 ReLU activation function은 모든 negative values에서 gradient flow를 멈춤
더 나아가 우리가 보통의 feature normalization 테크닉을 사용하지 않았다는 것을 주의해라(Batch Normalization 같은거)
하지만 대신 단순히 learned scaling factor을 사용했다 각 feature map에 대해
bias term 더하기 직전에
우리의 실험에서 이 테크닉은 충분했다 학습을 stable 하게 하는데에
이미지 경계가 결과에 미치는 영향을 완화하기 위해, 우리는 가능한 한 제로 패딩 대신 reflect 패딩을 사용했습니다.
Evaluation
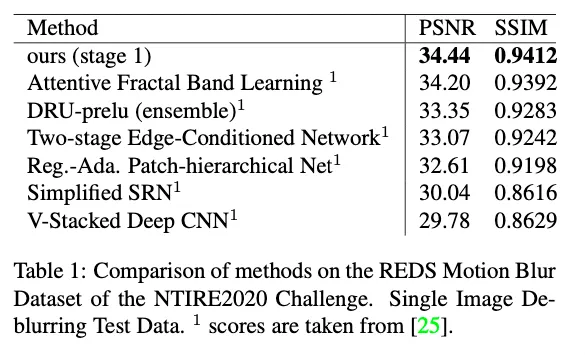
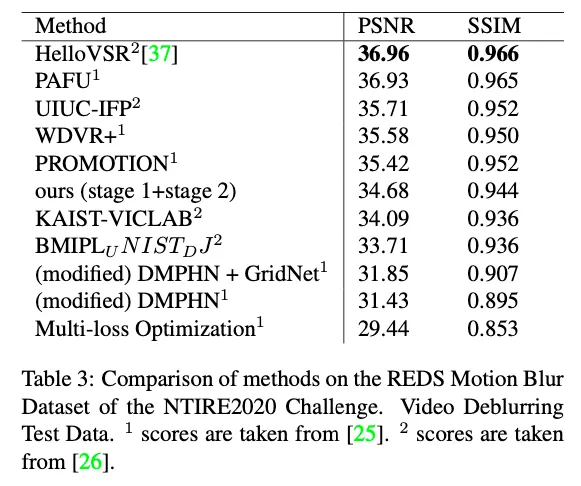
single image에 대한 다양한 방법의 비교 ( REDS dataset )
best video score 달성 stage 1 모델로 separately deblurring 해서 stage2로 합치는 방식으로
[33, 19]의 geometric self-ensemble을 수행했다 성능향상 위해 input frames를 4개의 다른 버전으로 augmenting함으로 인해 - rotating and flipping
모든 combinations는 네트워크에 들어가고, 그들의 원래 shape로 돌아간다. 그리고 모든 combinations의 mean pixel value가 final prediction으로 더해진다
Ablation Study

benchmark Results
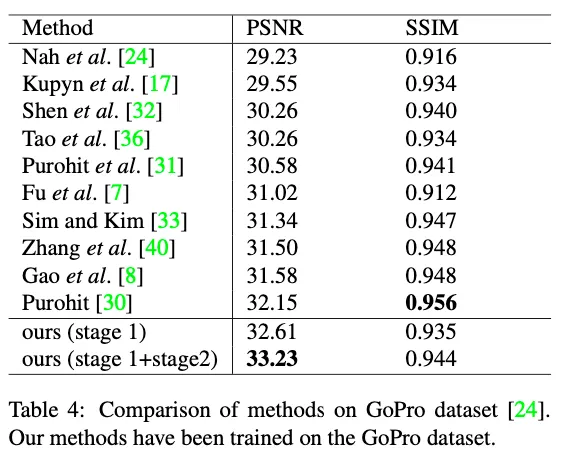

result example

Conclusion
새로운 atrous residual block으로 single image deblurring tast에 대한 high resolution motion deblurring network 제안
이 모델을 video deblurring task까지 확장 - 다른 프레임의 정보를 합침으로써
우리의 벤치마크에서의 실험은 이전의 연구들에 비교해 우리의 연구의 우월함을 입증했다
우리는 atrous network without any internal down sampling이 더한 향상을 가져왔다고 추정한다
그러므로 future work는 우리가 메모리와 런타임 제한때문에 사용한 single down sampling layer를 제거할 수 있을 것이다
첫번째 실험은 full resolution model이 더 빨리 수렴함 파라미터 업데이트 횟수 측면에서
이 전망은 future work에 대한 유망함을 보여줌
또하나의 promising perspective는 제안된 stage1과 stage2의 장점들을 싱글네트워크로 그래서 end-to-end로 학습될 수 있도록 합치는 것이다
