.jfif&blockId=452a434b-d46f-455a-be72-e7a9139b7af3)
CPU time
CPU Time = CPU Clock Cycle x Clock Cycle Time = CPU Clock Cycle / Clock Rate
Performance는 다음과 같이 하여 향상시킬 수 있다
•
CPU Time이 짧을수록 Performance가 향상되므로
◦
CPU Clock Cycle 또는 Clock Cycle Time을 감소시키기
◦
Clock Rate 증가시키기 = Clock Period 감소시키기
•
보통 clock rate를 높이면 cycle count도 늘어나게 되어있다. 하드웨어 디자이너는 이 trade -off를 잘 조절하여 적당한 포인트를 찾아야 하겠다.
<예제>
컴퓨터 A : 2GHz clock(=clock rate), 10s CPU Time
컴퓨터 B : 6s의 CPU Time이 목표, 더 빠른 clock가능하지만 1.2 x clock cycle을 유발한다.
Q. 컴퓨터 B의 clock은 얼마나 빨라져야 하는가?
[풀이]
Clock Rate_B = Clock Cycles_B / CPU TIme_B = 1.2 x Clock Cycles_A / 6s
Clock Cycles_A = CPU Time_A x Clock Rate_A = 10s x 2GHz = 20 x 10^9
Clock Rate_B = 1.2 x 20 x 10^9 / 6s = 24 x 10^9 / 6s = 4GHz
Instruction Count and CPI
Cycle per Instruction = CPI = 하나의 명령어 실행에 몇 cycle이 걸리냐
Instruction Count = 명령어 수
Clock Cycles = Instruction Count x CPI
CPU Time
= Instruction Count x CPI x Clock Cycle Time
= Instruction Count x CPI / Clock Rate
Instruction Count
•
program(의 알고리즘), ISA(Instruction set architecture), Compiler에 의해 결정된다
ISA란?
마이크로프로세서가 인식해서 기능을 이해하고 실행할 수 있는 기계어 명령어를 말한다. 마이크로프로세서마다 기계어 코드의 길이와 숫자 코드가 다르다. 명령어의 각 비트는 기능적으로 분할하여 의미를 부여하고 숫자화한다. 프로그램 개발자가 숫자로 프로그램하기가 불편하므로 기계어와 일대일로 문자화한 것이 어셈블리어이다. [위키백과]
프로그램 작성시 프로그램은 한 명령어로 되어있지 않다. 여러 명령어로 이루어져 있음. 그래서 더 정확한 표현을 위해 사용하는 것이
•
Average cycles per instruction
◦
CPU 하드웨어에 의해 결정됨
◦
만약 다른 명령어들이 다른 CPI를 갖는다면 Average CPI가 instruction mix(명령어의 조합)에 의해 영향을 받는다.
→ 어떤 프로그램은 A명령어가 많이 사용되어 Average CPI가 낮고 어떤 프로그램은 B명령어가 많이 사용되어 Average CPI가 높고 이럴 수 있다는 의미
[CPI 예제]
Computer A는 Cycle time이 260 ps → 4GHz, CPI = 2.0
Computer B는 Cycle time이 500 ps → 2GHz, CPI = 1.2
ISA는 같다
Q. 어떤 컴퓨터가 더 빠르고, 얼마나 빠른가?
[풀이]
CPU Time_A = Instruction Count(l) x CPI_A x Cycle Time_A = l x 2.0 x 250ps = l x 500ps
CPU Time_B = Instruction Count(l) x CPI_B x Cycle Time_A = l x 1.2 x 500ps = l x 600ps
B가 1.2배만큼 빠르다
CPI in More Detail
•
다른 instruction classes가 다른 cycle수를 갖는다면
◦
Clock Cycles =
◦
Latex수식으로 ∑밑을 i=1로 하는 법을 모르겠네욤.. 알려주세요..
◦
Weighted average CPI
평균 CPI를 구하지만, weighted→ 즉 명령어들의 비율이 반영된 값
CPI = =
는 Relative frequency
CPI Example
같은 프로그램인데 컴파일을 다르게 하여 다른 명령어 조합으로 이루어진 Alternative Compiled Code
다음은 A, B, C 클래스의 명령어만 사용하는 Alternative compiled code sequences이다.(IC = Instruction Count)
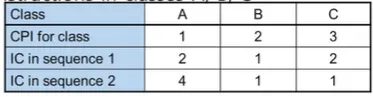
•
Sequence 1 : IC = 5
◦
Clock Cycles = 2 x 1 + 1 x 2 + 2 x 3 = 10
◦
Avg. CPI (= 2/5 + 2/5 + 6/5) = 10/5 = 2
•
Sequence 2 : IC = 6
◦
Clock Cycles = 4 x 1 + 1 x 2 + 1 x 3 = 9
◦
Avg.CPI = 9/6 = 1.5
⇒Sequence 2가 IC가 더 큼에도 불구하고, Avg.CPI가 더 작아 실행시간이 더 빠르다는 것을 알 수 있다.
Performance Summary
[식에서 알 수 있는 것]
•
Instructions는 Program의해, ClockCycles는 Instruction 의해, Seconds(실행시간)은 Clock Cycles의해 결정됨
•
위 식은 결국 = Instruction Count x CPI x Clock Cycle Time(Clock Period) = Instruction Count x CPI / Clock Rate
Performance를 결정하는 것
•
알고리즘 : IC, 어쩌면 CPI에도 영향을 미침
•
Programming language: IC, CPI에 영향을 미침
•
Compiler : IC, CPI에 영향을 미침
•
Instruction set architecture(ISA) : IC, CPI, 에 영향을 미침
Performance 예제
난이도 상
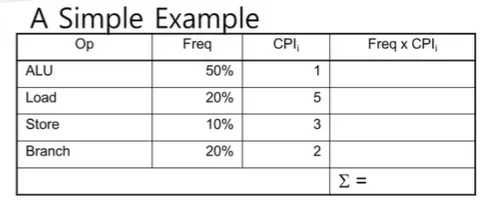
Op = 명령어 타입
Freq x 는 위에서부터 순서대로 0.5, 1.0, 0.3, 0.4, ∑ = 2.2
Q1. 어떤 더 나은 data cache가 average load time을 2cycles로 줄인다면 기계는 얼마나 빨라지는가?
→ Load의 가 2로 줄어드므로 Freq x 는 위에서부터 순서대로 0.5, 0.4, 0.3, 0.4, ∑ = 1.6
→ 새로운 CPU Time = 1.6 x IC x CC, 2.2 / 1.6 = 1.375 ⇒ 37.5% 더 빨라짐
Q2. branch prediction을 사용하여 branch time을 한 사이클 단축하는 것과 비교하면 어떻습니까?
→ Branch의 가 1로 줄어듬
→ Freq x 는 위에서부터 순서대로 0.5, 1.0, 0.3, 0.2, ∑ = 2.0
→ 2.2 / 2.0 = 1.1 ⇒ 10% 더 빨라짐
Q3. ALU명령어가 한번에 2개씩 실행할 수 있도록 하면 어떻게 되나요?
→ ALU의 가 0.5로 줄어듬(절반으로)
→ Freq x 는 위에서부터 순서대로 0.25, 1.0, 0.3, 0.4, ∑ = 1.95
⇒ 2.2/1.95 = 1.128 ⇒ 12.8% 더 빨라짐
The Power Wall
컴퓨터 트렌드에 큰 변화를 준 요인 중 하나이다.
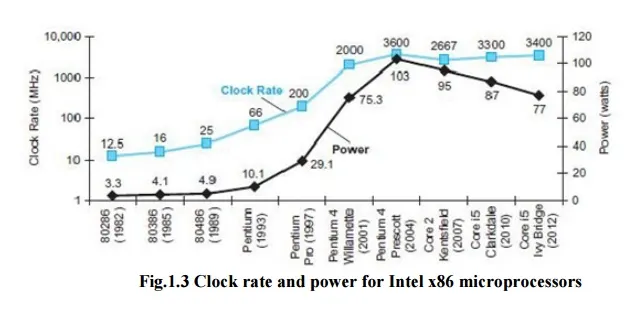
시간에 따른 Clock Rate(log scale로 나타남, 파란 꺾은선), Power(linear scale, 검정 꺾은 선)
•
IC Technology의 CMOS에서는
◦
Power = Capacitive load x Voltage^2 x Frequency
2004~2005년 기점으로 Clock Rate도 거의 변화하지 않고 Power은 오히려 감소하는 모습을 보인다.
Power는 그래프의 기간 동안 약 30배, Voltage는 1/5배, (Clock)Frequency는 약 1000배가 되었다.
Power는 Voltage에 가장 큰 영향을 주고있다.
Power를 그대로 하고, Frequency를 늘리고 싶다면 Voltage는 제곱이기 때문에 Voltage를 줄이는 것이 가장 효과적이다.
그래서 그동안 5V→1V로 줄여온 것이었다. 그러나 이 이하로 내리면 칩이 동작하지 않아 더이상 줄일 수 없었고, Frequency의 증가도 멈춘 것이다.
Reducing Power
•
새로운 CPU가
◦
이전 CPU의 85%의 capacitive load를 갖고, 15%의 voltage reduction과 15%의 frequency reduction을 가져온다고 가정해보자
⇒ 새로운 CPU의 Power는 이전 CPU의 power의 약 52%
용량성 부하(Capacitive Load)
용량성 리액턴스가 유도성 리액턴스보다 큰 부하. 이 경우 부하에 흐르는 전류는 전압보다 위상이 앞서 있으며 진상 전류를 형성하고 방해원과 신호 시스템 사이의 용량에 의한 결합으로 만들어진 전계에 의해 신호 시스템에 방해를 준다.
The Power Wall
◦
더 이상 voltage는 줄일 수가 없음
◦
발열도 제거할 수가 없음(전력많이 사용시 발열 증가)
◦
이러한 이유로 성능을 더 이상 향상시킬 수 없게되는 현상을 Power Wall이라고 한다.
어떻게 해야 다른방식으로 Performance 향상시킬 수 있을까?
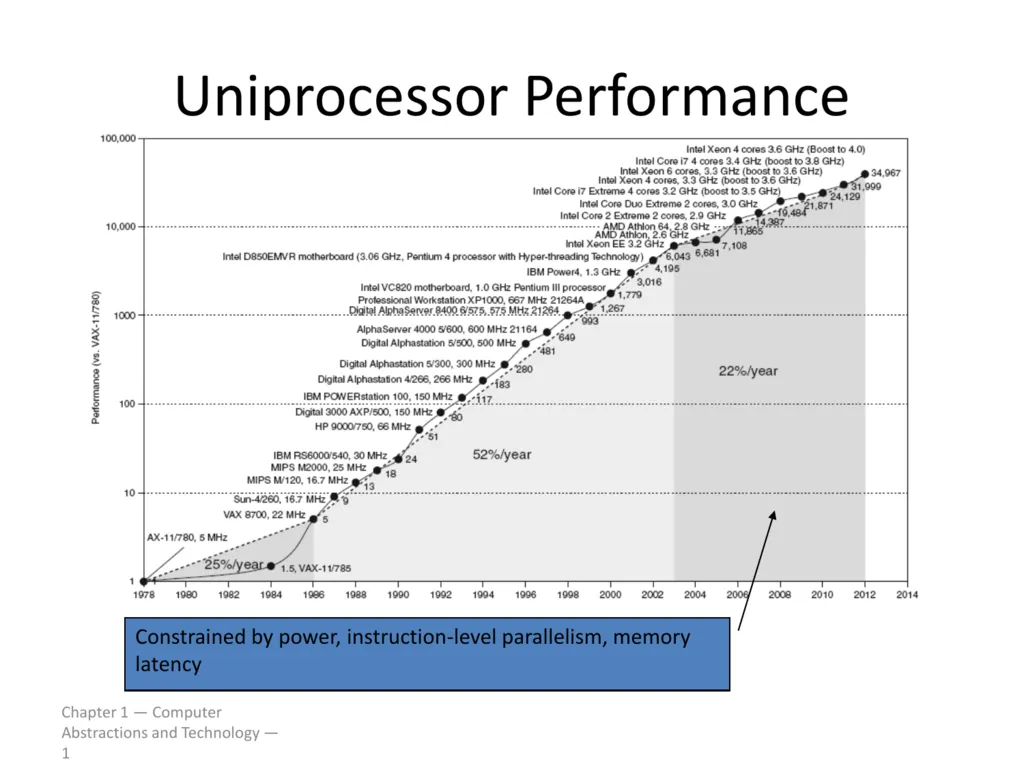
1976-1996 : 1년에 약 25% 증가
1996-2003 : 1년에 약 52% 증가 - 급격한 성장
2003-2012 : 1년에 약 22% 증가 - 성장 줄어듬 ⇒ Power, Instruction-level parallelism, memory latency 등 의해 제한을 받았기 때문
MultiProcessors
다중 프로세서는 단일 프로세서의 참조이기도 합니다.
멀티프로세서와 유니프로세서의 차이점은 멀티프로세서가 (컴퓨터 하드웨어) 여러 개의 CPU 또는 실행 장치를 통합 제어 하에 둔 컴퓨터인 반면, 유니프로세서는 한 번에 하나의 태스크에서 순차적으로 작동할 수 있는 단일 프로세서(CPU)라는 점입니다.
◦
Multicore microprocessors
▪
하나의 칩 당 하나 이상의 프로세서 존재
▪
dual core, quad core, ..., octa core
▪
parallel programming이 가능해졌다.
◦
Requires explicitly parallel programming 병렬 프로그래밍의 명시적 필요성
▪
instruction level parallelism(ILP)과의 비교
ILP는
•
하드웨어가 한번에 여러 instructions를 실행한다(명령어 차원에서의 병렬).  parallel programming은 프로그램 자체를 여러개 돌리는 것
parallel programming은 프로그램 자체를 여러개 돌리는 것
parallel programming은 프로그램 자체를 여러개 돌리는 것•
이에 프로그래머들은 관여하지 않는다.
[Parallel Programming의 어려운 점]
▪
프로그래밍하기가 힘들다(디버깅 까다로움)
▪
여러 프로세서 중 A는 실행할 것이 많고, B는 적고 이런 imbalance가 발생할 수 있다 = Load Balancing이 어렵다
▪
프로세스 간의 communication과 synchronization이 발생한다. 그래서 예상보다 성능이낮게 나오게된다.
SPEC CPU Benchmark
SPEC = Standard Performance Evaluation Corp
benchmark란 어떤 것의 성능을 측정해주는 프로그램
SPEC CPU Benchmark란 CPU 성능 측정해주는 benchmark
•
supposedly typical of actual workload
SPEC은 CPU, I/O, Web등의 benchmarks를 개발
•
SPEC CPU2006 - 2006년에 만들어진 CPU성능 측정 위한 benchmark
selection of programs를 실행하는데 소요된 시간으로 구성되어 있음
프로그램인데, 무시가능한 I/O (I/O시간은 매우매우매우 짧음)으로 CPU Performance에 집중할 수 있는 것이 특징
reference machine에 비교하여 normalize하여 비교한다.
숫자가 클 수록 성능이 좋은 것이다.
Summarized as geometric mean of performance ratios
여러가지 프로그램의 SPEC ratio의 geometric mean을 이용해 성능 측정
◦
[종류] CINT2006(integer) and CFP2006(floating point)
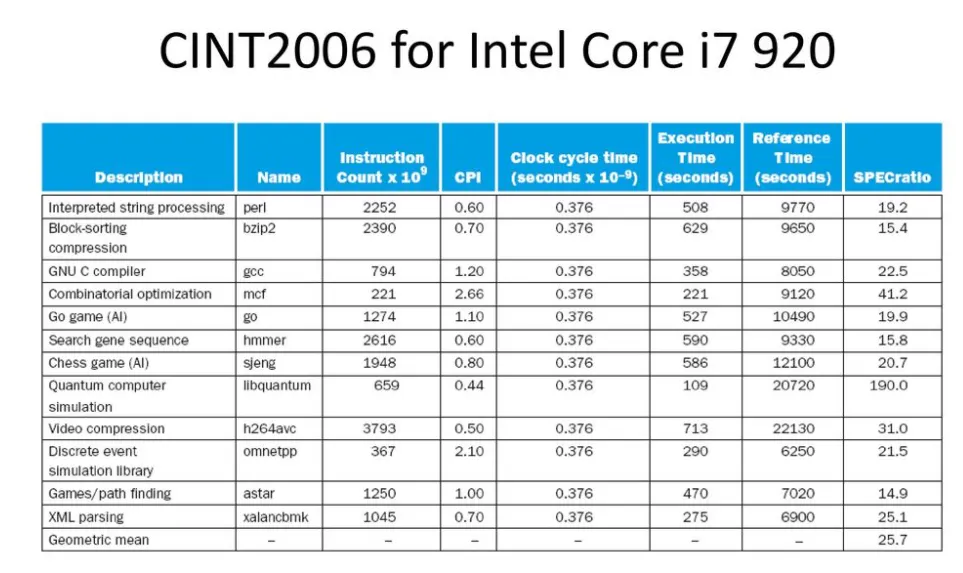
Intel Core i7대한 CINT2006결과
맨 첫 줄을 살펴보자면, 일단 reference machine에서는 9770초(Reference Time)가 걸린 것을 i7에서는 508초(Execution time)가 걸렸다고 한다.
프로그램 이름은 perl이고, 특성은 Description에 쓰인대로
명령어의 수는 2252x10^9 (Instruction Count)
그 외 CPI, Clock Cycle Time등이 표현되어있다
그래서 결과적으로 맨 마지막에 나와있는 SPECratio를 gemetric mean구하여 기존 reference machine에 비해 얼마나 성능이 좋은지 표현. 이 표에선 25.7배 빠르다고 할 수 있겠다.
SPEC Power Benchmark
•
Power Consumption of server at different workload levels
◦
Performance = ssj_ops/sec
◦
Power = Watts(Joules/sec)
◦
ssj_ops = server size 작업(ssj가 server size라는 말)
Overall ssh_ops per Watt =
SPECpower_ssj2008 for Xeon X5650
Xeon X5650 이라는 CPU대한 내용
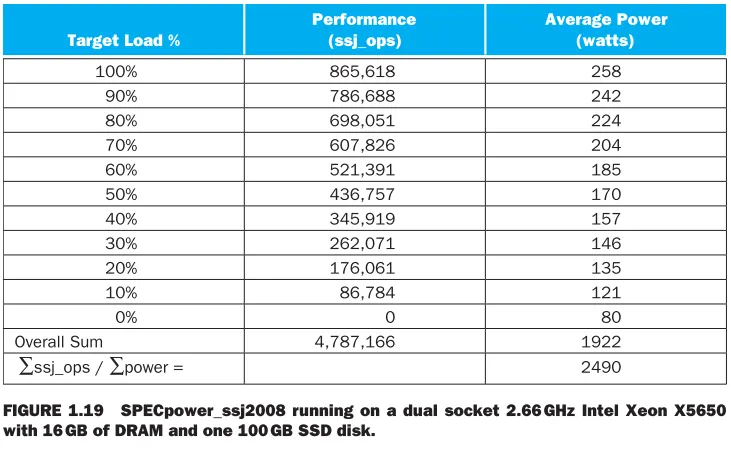
당연히 Target Load가 높아짐에 따라 Performance(ssh_ops), Average Power도 증가
Target Load에 따른 Performance 의 합에서 Average Power의 합을 나눠주면 Overall ssh_ops per Watt를 알 수 있음 ⇒ 높을수록 효율적! 낮다는건 전력효율이 낮다는 뜻이기 때문
Concluding Remarks
•
Cost/performance is improving
◦
underlying technology development(Moore's Law)의해
◦
최근에는 Moore's Law의 적용이 어려워짐
•
Hierarchical layers of abstraction
◦
hardware와 software 둘 다에서
•
Instruction set architecture
◦
= hardware/sortware interface
•
Execution time: the best performance measure(가장 좋은 성능지표)
•
Power is a limiting factor
◦
Performance향상을 위해 parallelism사용
Fallacies and Pitfalls(오류와 위험들)
Pitfall : Amdhl's Law
•
aspect of a computer(컴퓨터의 한 부분, 컴퓨터의 한 컴포넌트)의 성능을 향상시키면 그 컴포넌트가 전체에서 차지하는 비율만큼 전체 performance가 향상된다는 법칙
•
식 :
•
(예) 어떤 프로그램에서 multiply는 전체실행시간 100s에서 80s를 차지한다.
◦
전체 성능이 5배 더 좋아지려면 multiply performance가 얼마나 향상되어야하는가?
◦
20s = 80s/n + 20 (n=얼마나 향상시켰는가)
◦
이 식에서 문제를 만족시키려면 n은 무한대가 되어야함
◦
즉 불가능!
우리가 알 수 있는 것!전체의 성능에서 많이 차지하는 것의 성능을 향상 시킬수록 전체 성능이 더 많이 향상된다!
Fallacy: Low Power at Idle
i7의 power bench돌아보기
•
at 100% load : 256W
•
at 50% load : 170W (100%의 66%)
•
at 10% load : 121W(100%의 47%)
⇒ 10% load라고 해서 10%의 Power만 사용하는 것이 아니다.
Google Data Center의 경우
•
보통의 경우 전체 성능의 10-50% load 정도만 사용한다
•
전체시간의 약 1%도 안되는 시간동안에만 100% load를 사용
•
⇒ 적은 작업을 해도 전력 소비량이 크다!
Hardware Designers : 프로세서 설계시 load에 비례하게 전력을 소비할 수 있도록 고려하여 디자인해야 한다.
Pitfall: MIPS as a Performance Metric
•
MIPS = Millions of Instructions Per Second(지금은 잘 쓰지 않는 용어이다. 한때의 성능지표)
•
1초에 몇백만의 명령어를 실행하는지
◦
이러한 것들을 고려하지 않아 문제가 되었다
1.
Differences in ISAs between computers
2.
Differences in complexity between instructions(명령어사이의 CPI값 차이)
•
MIPS는 결국 CPI가 결정하게 됨
•
그러나 CPI는 주어진 CPU에서 프로그램마다 다르다.
•
올바른 성능지표가 아님!
