Abstract
Image Restoration : spatial details  high level contextualized information 간의 balance가 중요
high level contextualized information 간의 balance가 중요
high level contextualized information 간의 balance가 중요 이를 최적으로 맞출 수 있는 아키텍쳐 디자인 제안
•
degraded input에 대한 복원 functions를 progressively 학습 → 모든 recovery process를 보다 관리하기 쉬운 단계 ( manageable steps )로 분해
⇒ Multi Stage Architecture
◦
encoder-decoder architecture로 먼저 contextualized features 배움
◦
그 이후 로컬 정보 유지되는 high resolution branch와 결합
•
각 stage에서는 per-pixel adaptive design
⇒ 실시간 supervised attention → local features reweight
•
다른 stage간의 information 교환이 중요
Introduction
Image restoration : degraded image → clean image
solution space을 valid/natural 이미지로 제한하기 위해, 기존 복원 기술은 emperical observations로 handcrafted image priors를 사용합니다.

이런 priors를 설계하는 것은 매우 어려운 작업이며 일반화하기 어려움
이 이슈를 개선하기 위해 CNN 적용 솔루션이 나옴.
그러나 대부분이 single stage이며 low level vision problems(image classification, segmentation, detection, deblurring, ...)를 위한 것이었다.
multi stage network가 high level vision problems(pose estimation, scene parsing, action segmentation)에 대해 더 효율적이라는 것이 알려져 있으나
image deblurring 혹은 image deraining에서의 multi stage 적용 연구는 거의 없었다
multi-stage image restoration의 아키텍쳐 측면에서의 bottleneck
1.
현존하는 multi-stage 기술들은 encoder-decoder 구조를 채택하거나
: broad contextual information 들을 encoding하는데에는 효과적이나 spatial image details를 보존하는데에는 사용하기 어렵다
: 혹은 spatially accurate하지만 sementically less reliable output을 갖는 single-scale pipeline을 사용한다.
⇒ 우리는 multi stage architecture에서 두 디자인을 조합하는 것이 이미지 복원에 효과적임을 보여줌
2.
우리는 단순히 one stage를 통과한 결과물을 다음 stage로 보내는 것이 suboptimal results를 낳음을 보여줌 ( 단순히 보내주는 것이 아니라 어떠한 처리를 해서 보내줘야 한다 )
3.
점진적 복원을 위한 각 stage에서 ground-truth supervision을 제공하는 것은 중요하다.
4.
multi stage processing 도중에 encoder decoder branch로부터 contextualized features를 보존하기 위해 intermediate features를 earlier 스테이지로부터 later stage로 전파하는 메커니즘이 필요하다.
MPRNet이라는 multi stage progressive image restoration 아키텍쳐를 제안하며, 여러 key 요소들을 갖고있다.
1.
earlier stages는 인코더-디코더를 적용 → multi-scale contextual information 을 배움
last stage는 fine spatial details 를 보존하기 위해 원본 이미지 해상도로 작동한다.
2.
supervised attention module ( SAM )이 모든 stage사이에 껴서 progressive learning을 가능하게 한다.
•
GT이미지의 가이드로, SAM은 이전 stage 예측을 활용해 다음 stage로 전달되기 전 이전 단계 features를 개선(refine)하는데 사용되는 attention maps를 계산한다.
3.
A mechanism of cross-stage feature fusion (CSFF) 가 추가됨 : multi scale contexualized features가 이전 스테이지로부터 다음 스테이지로 전파되는 것을 돕는 메커니즘.
스테이지간의 information flow를 쉽게하여 multi stage network optimization을 효과적으로 안정화한다.
main contribution
•
새로운 multi stage 접근 →
contextually-enriched( contextual information 풍부 ) + spatially accurate
multi stage 환경 → 우리의 프레임워크는 어려운 이미지 복원 문제를 sub-tasks로 쪼개면서 점진적으로 degraded 이미지를 복원한다.
•
효과적인 supervised attention module이 모든 단계에서 incoming features를 더 전파하기 전에 개선하는데에 restored image를 최대한으로 활용한다.
•
stage들 간의 multi scale features를 결합하는 stategy
•
10개의 synthetic and real world datasets에서 새로운 SOTA를 달성하며 다양한 복원( including image deraining, deblurring, and denoising while maintaining a low complexity)에서 MRPNet이 효과적임을 증명
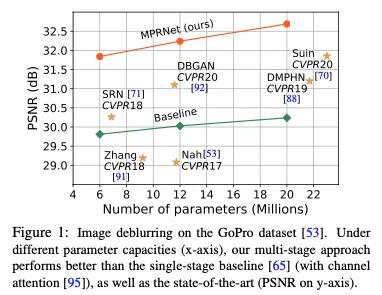
더 나아가 detailed ablations, qualitative results, generalization tests도 제공한다
Related Work
최근 DSLR → smart phone 패러다임의 변화
스마트폰으로 고퀄리티 사진 어려움
이미지 품질저하는 보통의 이미지에 다 존대. 카메라의 한계때문이건 불리한 주변 조건때문에
Early restoration 접근들은 total variatoin, sparse coding, self-similarity, gradient prior 등에 기반
최근에는 CNN based restoration 방식들이 SOTA를 달성
아키텍쳐 디자인의 측면에서 이 방법들은 아주 넓게 카테고리를 나누면 single stage와 multi stage로 나눌 수 있다
•
Single Stage Approches
이미지 복원 방식의 대부분은 single stage design에 기반
아키텍쳐 요소들은 일반적으로 high level vision tasks를 위해 개발된 것이 기반
예를 들어
residual learning : image denoising/deblurring/deraining을 수행하기 위해 사용되어 왔다
비슷하게 multi scale information을 추출하기 위해 encoder-decoder와 dilated conv모델이 자주 사용되었따. 다른 single stage 접근들은 dense connections를 포함한다.
•
Multi Stage Approches
점진적인 방식으로 이미지를 복원하는 것을 목적으로 한 방식들. weight가 가벼운 subbnetwork를 각 단계에 적용한다. 어려운 이미지복원을 각 단계에서 sub task들로 분해하기에 효과적.그러나, 일반적인 관행은 우리의 Section 4 실험에서 볼 수 있듯이 각 스테이지에서 suboptimal result를 산출할 수 있는 subnetwork를 사용한다.
•
Attention
image classification, segmentation, detection 같은 high level tasks에서의 성공에 힘을 얻어 attention module은 low level vision tasks 에도 적용되어왔다.
예를 들어 이미지 deraining [37, 47], 디블러링 [61, 70], 초해상도 [17, 95], 노이즈 제거 [4, 86] 등의 방법이 있습니다. 주요 아이디어는 spatial dimensions[98], channel dimensions[32] 또는 둘 다에 따라 long-range inter dependencies을 포착하는 것입니다 [79].
Multi Stage Progressive Restoration
제안된 이미지 복원을 위한 프레임워크는 Fig 2
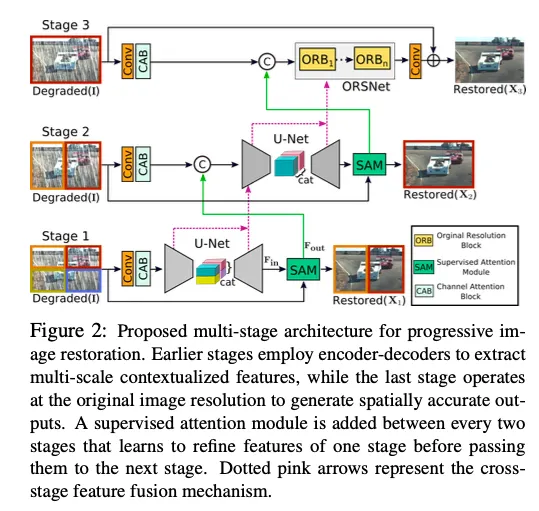
•
3개의 스테이지로 점진적인 이미지 복원
첫 두개의 스테이지는 encoder-decoder subnetworks 기반, broad contextual information 배움
→ 큰 receptive fields덕덕분
이미지 복원은 position sensitive task ( input에서 output으로의 pixel to pixel correspondence가 필요한 ) 이므로
•
마지막 단계는 원래 인풋이미지 해상도를 다루는 subnetwork를 사용한다. 그러므로 마지막 output image에서 원하는 fine texture를 보존할 수 있다.
단순히 multiple stage를 계단화하는 대신 supervised attention module을 모든 두 스테이지 사이에 포함한다
→ GT이미지의 supervision (감독)으로 우리의 모듈은 이전 스테이지의 피쳐맵들을 rescale해 다음 스테이지로 보낸다. ( SAM 모듈. 뒤에 더 자세히 설명 )
게다가 우리는 cross stage feature fusion 메커니즘을 소개한다. 이전 subnetwork에서 나온 intermediate multi scale contextualized features가 더 뒤의 subnetwork에서 나온 intermediate features를 통합하는 것을 돕는다. → stage간에 feature를 전달하면서 영향을 주는 것으로 생각하면 될 듯 하다.
MPRNet이 여러 stage를 쌓음에도 불구하고 각 스테이지는 input 이미지에 접근할 수 있다
최근의 복원 방법과 유사하게 우리는 multi patch hierarchy를 input 이미지에 적용해 이미지를 겹치지 않는 patch로 나누었다. stage 1은 4개, stage2는 2개, last stage는 original image

: stage
: restored image
: Residual image
: GT image
: Charbonnier loss
: edge loss
제안된 모델은 각 스테이지에서 를 바로 예측하기보다는 에서 에 더해지는 를 예측한다.
[Loss Function]

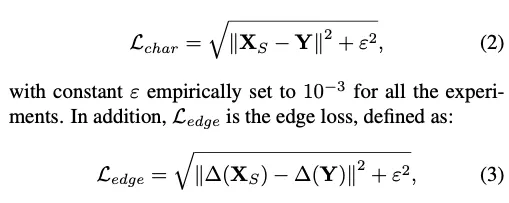
은 경험적으로 으로 설정. 은 penalty term으로, 이상치에 robust하게 해준다
: Laplacian operator
: 두 loss간의 상대적 중요성을 컨트롤. 0.05로 설정
3.1 Complementary Feature Processing
존재하는 이미지복원을 위한 single stage CNN들은 전형적으로 이 중 하나의 아키텍쳐 디자인을 따름
1.
encoder-decoder : 처음에 점진적으로 인풋을 저해상도 표현으로 매핑한 후 점점 reverse mapping으로 원래 이미지 해상도로 복원, 효과적으로 multi scale의 정보를 엔코딩할지는 몰라도 그들은 spatial details를 희생하기 쉽다
2.
single scale feature pipeline : fine spatial details를 가진 이미지들을 생성하는데 reliable
그러나 semantically less robust → 왜냐하면 제한된 receptive field 때문
두 설계의 장점을 활용하기 위해, 우리는 초기 단계가 인코더-디코더 네트워크를 통합하고 최종 단계가 원래 입력 해상도로 작동하는 네트워크를 사용하는 다단계 프레임워크를 제안합니다
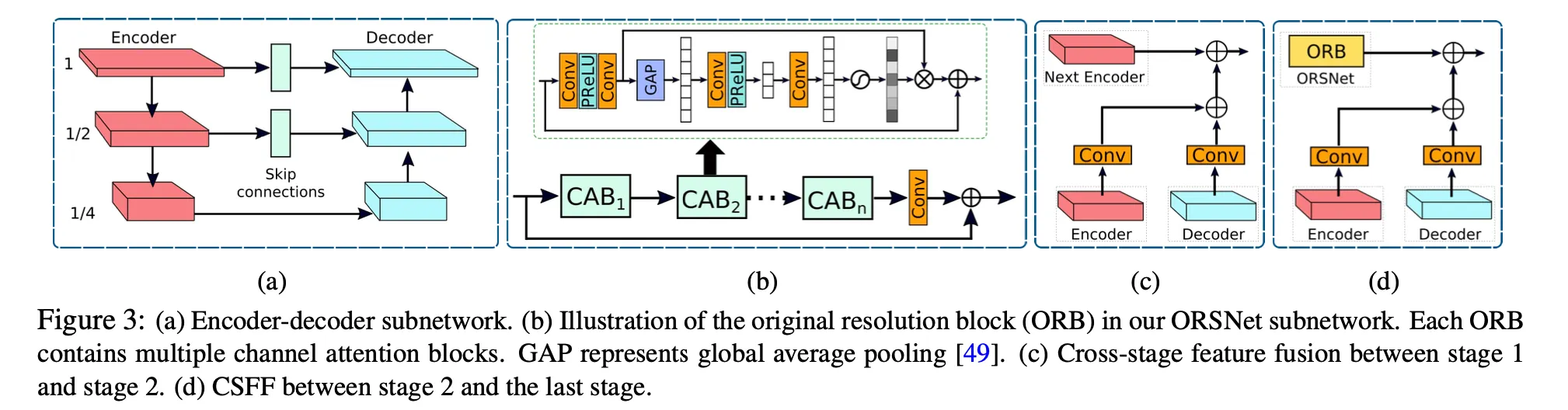
Encoder-Decoder Subnetwork
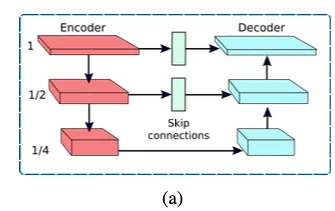
위 그림이 우리의 encoder-decoder 구조를 나타낸다. 일반 U-net에 기반하고 뒤에 말할 요소들을 더했다.
첫번째로, Channel Attention Blocks( CABs )를 넣는다. 이는 각 scale에서 features를 추출한다.
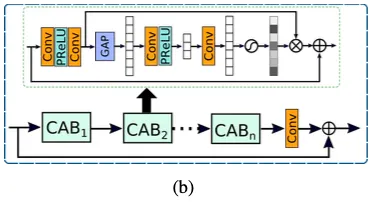
ORB(original resolution block)의 구조와 CAB의 구조를 나타냄
두번째로, U-Net skip connections에서 featuremap는 CAB를 통해 처리된다.( (a)그림의 skip connection. )
마지막으로, decoder부분에서 Transposed conv를 사용해서 해상도를 늘리지 않고, bilinear upsampling을 사용했다. 왜? checkboard artifacts를 줄이기 위해. (Transposed Conv로 인해 잘 발생하는 문제이다)
Original Resolution Subnetwork
fine details를 보존하기 위해서 original-resolution subnetwork(ORSNet)을 마지막 stage에서 사용한다
ORSNet은 어떠한 downsampling 연산도 하지않고 spatially enriched한 high-resolution features를 생성한다

이것은 여러개의 original resolution blocks ( ORBs )로 이뤄져있다. ORBs 각각은 CABs를 포함하고 있다.
코드보면 ORB에 CAB가 8개 들어간다
보면 Degraded에 Residual을 합치는 방식 사용 (블러/rain 성분을 빼는 것이라 볼 수 있음)
3.2 Cross-stage Feature Fusion
우리의 프레임워크에서, 우리는 두 encoder-decoders 사이, 그리고 encoder-decoder 과 ORSNet 사이에 CSFF 모듈을 적용한다.
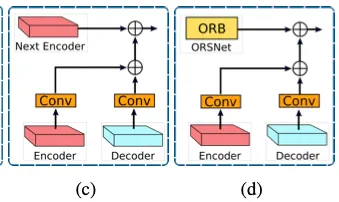
[ Note] 한 stage에서 aggregation을 위해 다음 stage로 전파되기 전에 1x1 conv로 개선됨
] 한 stage에서 aggregation을 위해 다음 stage로 전파되기 전에 1x1 conv로 개선됨제안된 CSFF 는 다양한 장점을 가진다
1.
encoder-decoder에서 up/down sampling 연산의 반복된 사용때문에 발생하는 information loss에 따른 network의 취약성이 감소된다 ( 이전 단계의 feature들이 전달되니까 )
2.
한 stage의 multi-scale features는 다음 stage의 features를 풍부하게 도와준다
3.
네트워크 optimization 절차는 더 안정적이된다. information 의 흐름을 쉽게 해주기 때문이다. 그 때문에 우리가 전체 아키텍쳐에 여러 단계를 추가할 수 있게 해준다.
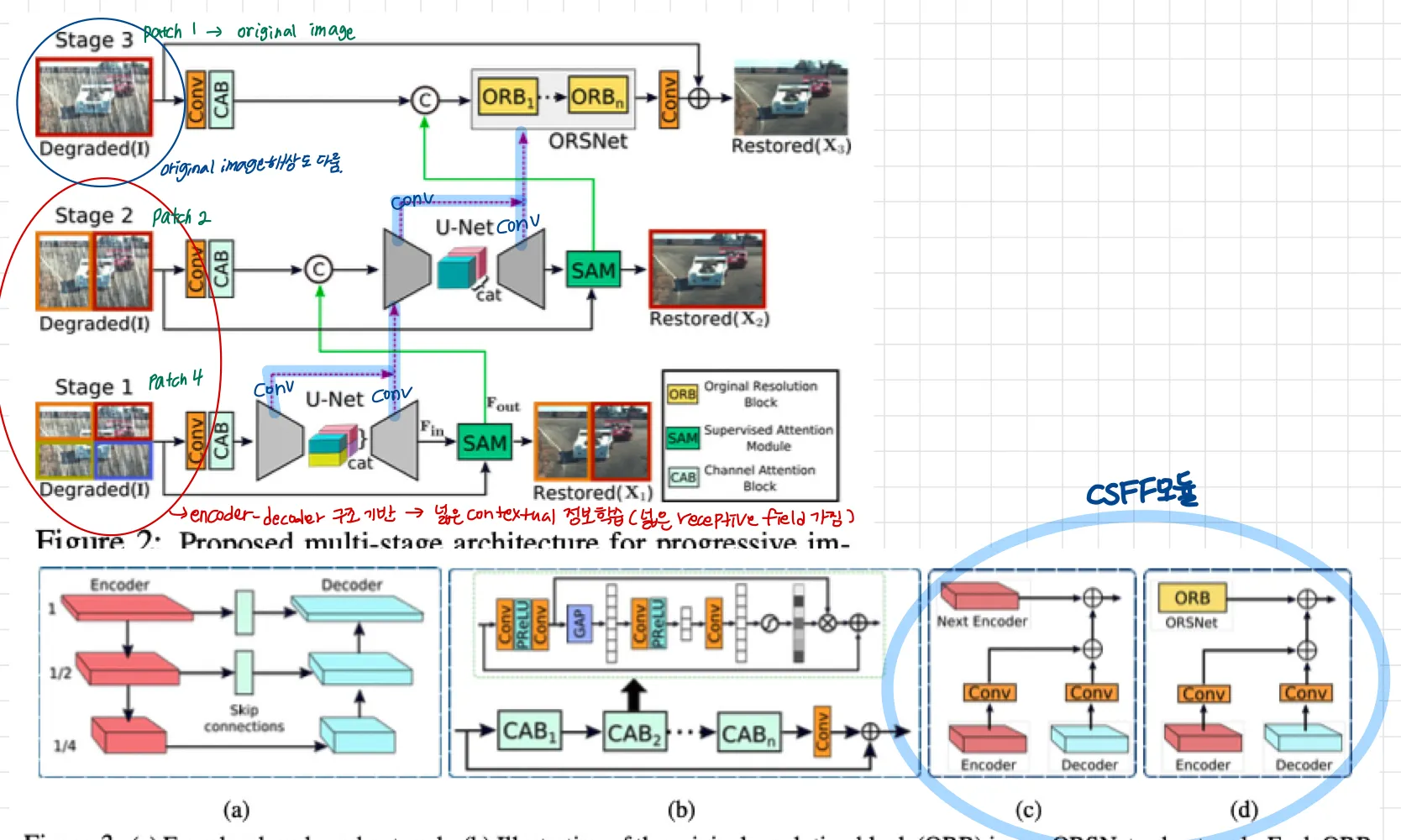
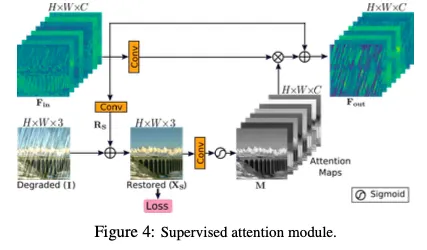
3.3 Supervised Attention Module (SAM)
최근 이미지 복원을 위한 multi stage networks는 한 이미지를 각 스테이지에ㅓ서 곧바로 예측했다. 그리고 다음 스테이지로 전달했다.
대신 우리는 supervised attention module을 모든 두 스테이지 사이에 적용했다. 이는 상당한 성능 향상을 얻을 수 있게 해줬다
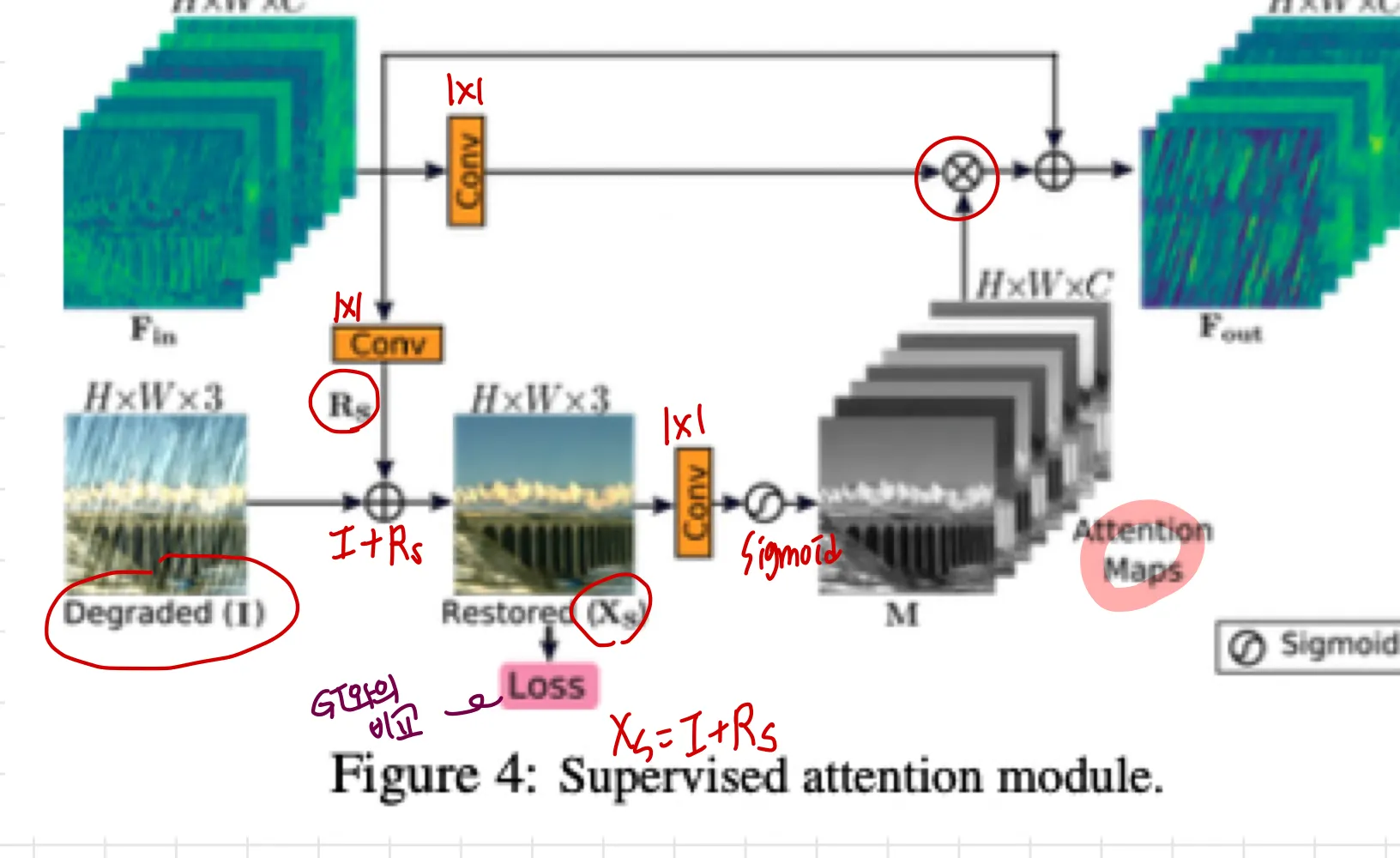
이것의 contribution은 2가지이다.
1.
ground-truth supervisory signals(GT감시신호)를 제공한다. 이는 각 스테이지에서 점진적인 이미지 복원에 유용하다 .
사진을 보면 각 stage에서 loss가 restored와 target 으로 계산되기 때문에 GT의 영향을 계속 받게되어 이런 표현을 쓴 것 같다.
2.
locally supervisory predictions의 도움으로 우리는 attentionmap을 생성한다.
현재 stage에서 less informative features는 억제하고, 다음 stage로 전파할 유용한 것들만 허용하기 위해서 이다.
Fig4에서 보이는 것처럼, SAM은 이전 스테이지로부터 들어오는
feature 1x1 conv residual image 를 생성
1x1 conv residual image 를 생성이렇게 생성된 는 degraded image인 input 에 더해진다
→ restored image 생성
이 예측된 이미지 에 대해, 우리는 GT image로 explicit supervision을 제공한다.
다음으로, per-pixel attention masks 가 로부터 1x1 conv - sigmoid로 생성된다.
1x1 conv sigmoid 이 masks는 transformed local features인 ( 1x1 conv 이후에 얻어진 ) 을 re-calibrate(재보정)하기 위해 사용된다. 이는 identity mapping path에 추가되는 attention guided features를 결과물로 산출한다.
마지막으로, attention-augmented feature representation 이 SAM에 의해 생성되고 다음 스테이지로 전달된다.
4. Experiments and Analysis
우리는 우리의 방법을 다양한 이미지 복원 task에서 평가했다.
a.
image deraining
b.
image deblurring
c.
image denoising
10개의 다른 dataset에서 실험
PSNR과 SSIM으로 평가
PSRN → 으로 변환,
SSIM → 로 변환해 평가
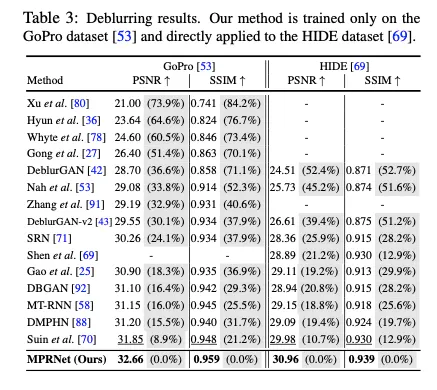
deblurring결과만 살펴보겠다
•
GoPro dataset
◦
training : 2,103 image pairs
◦
evaluation : 1,111 image pairs
◦
이 데이터로 train된 weights를 HIDE, RealBlur dataset에 바로 적용
◦
GoPro와 HIDE는 합성을 통해 만들어진 데이터고,RealBlur dataset은 진짜 사람이 찍어서 흔들린 데이터이다
•
RealBlur dataset은
◦
RealBlur-J : camera JPEG outputs
◦
RealBlur-R : RAW images에 white balancem demosaicking, denoising을 적용해 offline으로 만들어진 데이터
◦
이 두 subset으로 이뤄짐
[training details]
•
patch size: 256×256 patches
•
batch size : 16
•
4×105 iterations
•
data augmentation : horizontal, vertical flips
•
Adam optimizer
•
initial learning rate of 2×10−4, which is steadily decreased to 1×10−6 using the cosine annealing strategy