
복잡하고 시간이 걸리는 작업을 별도의 프로세스를 생성해 병렬처리해 보다 빠른 응답처리 속도를 기대할 수 있게 해준다
딥러닝 / 머신러닝같은 대용량의 빅데이터를 분석하고 예측해야 하는 task에서는 멀티 프로세싱을 통해 멀티코어의 CPU의 장점을 극대화하고 빠른 처리를 지원할 수 있다

병렬프로그래밍에 대한 충분한 공부 없이 코드를 작성하면 싱글프로세스보다 시간이 지연되거나 잘못된 결과가 발생할 수 있어 프로세스 / 쓰레드에 대한 이해가 필요합니다
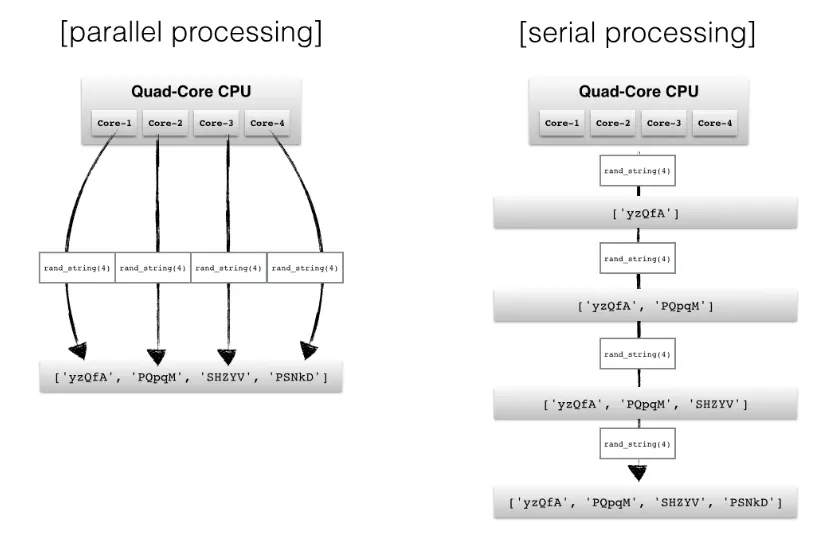
간단히 parallel processing 과 serial processing을 비교하면 다음과 같다
Pool 예시
from multiprocessing import Pool
## crop_image: 이미지를 랜덤하게 자르는 함수
pool = Pool(opt['n_thread'])
for path in img_list:
pool.apply_async(
crop_image, args=(path, opt), callback=lambda arg: pbar.update(1))
pool.close()
pool.join()
Python
복사
1.
pool 객체 생성
2.
이미지 리스트에 있는 이미지 경로마다 pool.apply_asyn으로 작업을 배정
•
apply_async
(func [, args [, kwds [, callback [, error_callback]]]])
◦
func : 호출할 함수
◦
args : func에 전달해줄 인자
◦
kwds : func에 전달해줄 키워드인자
◦
callback : 단일인자를 갖는 callable. 결과가 준비되면 이 결과를 인자로 호출
◦
error_callback : 대상 함수 실패시 호출
◦
* callback 이 완료되지 않으면 겨로가 처리하는 스레드가 블록된다
3.
close 호출로 리소스 낭비 방지
4.
join 함수로 작업완료 대기
여러 매핑함수
multi-args | concurrence | blocking | ordered-results | |
map | X | O | O | O |
apply | O | X | O | X |
map_async | X | O | X | O |
apply_async | O | O | X | X |
map / map_async는 한번에 job 리스트가 넘겨지지만
results = pool.map(worker, [1, 2, 3])
pool.map_async(worker, jobs, callback=collect_result)
apply / apply_async는 하나의 job만 넘겨진다( 예시코드처럼 loop가 필요하다 )
for x, y in [[1, 1], [2, 2]]:
results.append(pool.apply(worker, (x, y)))
def collect_result(result):
results.append(result)
Python
복사
apply_async는 백그라운드에서 job을 병렬로 실행한다
for x, y in [[1, 1], [2, 2]]:
pool.apply_async(worker, (x, y), callback=collect_result)
Python
복사
