Abstract
SegNet의 구성
•
encoder
•
decoder : encoder에서의 max pooling 위치정보를 사용해 non-linear upsampling을 수행한다.
•
pixel-wise classification layer
SegNet의 설계 목적은 road scene understanding 이며 다음과 같은 것들을 고려하여 설계됨
1.
memory 효율
2.
inference time 효율
3.
학습파라미터 효율
4.
end to end 학습
Introduction
SegNet은 road scene understanding이 목적이므로 road, building같은 appearance나 cars, pedestrians같은 shape를 잘 모델링하고, road와 side-walk같은 다른 클래스간의 spatial relationship (context)를 잘 이해할 수 있도록 설계했다.
Encoder 에서 추출된 image representation으로부터 boundary information을 유지하는 것이 중요하다.
대부분의 픽셀을 차지하는 도로/건물같은 큰 객체들은 smooth segmentation 생성할 수 있어야 하고, 보행자같은 작은 object에 대한 shape도 잘 나타낼 수 있어야 한다.
계산량 관점에선 memory 및 inference time에서 효율적이어야 한다.
Encoder 구성
•
VGG16과 입력 이후 13개의 convolution layer까지 동일구조
•
학습 파라미터 줄여 학습 쉽게 하기 위해 마지막 FC Layer 제거
Decoder 구성
•
각 encoder에 하나씩 연관되는 같은 계층구조의 decoder모듈들로 이루어짐
•
 encoder의 max pooling 레이어에서 max-pool indices를 받아 non-linear unsampling을 수행한다. 이를 통해 boundary delineation 성능은 향상시키고 모델의 학습 파라미터 수는 증가시키지 않았다.
encoder의 max pooling 레이어에서 max-pool indices를 받아 non-linear unsampling을 수행한다. 이를 통해 boundary delineation 성능은 향상시키고 모델의 학습 파라미터 수는 증가시키지 않았다. •
따라서 어떠한 encoder-decoder 구조라도 큰 수정없이 적용할 수 있다.
contributions
1.
SegNet과 FCN의 decoder에서 key design factors를 분리해 각각의 장단점을 분석하였다.
2.
2가지 scene segmentation task에서 test를 진행했다
a.
CamVid road scene segementation
b.
SUN RGB-D indoor scene segmentation
※ PASCAL VOC dataset은 여러배경에 1~2 class만 존재하는 이미지가 대부분이라서 scene understatnding task와 적합하지 않아 사용하지 않았다. scene understanding task에서 robust하려면 object의 co-occurrence 및 spatial-context를 학습할 수 있는 이미지 데이터가 필요하다.

Architecture
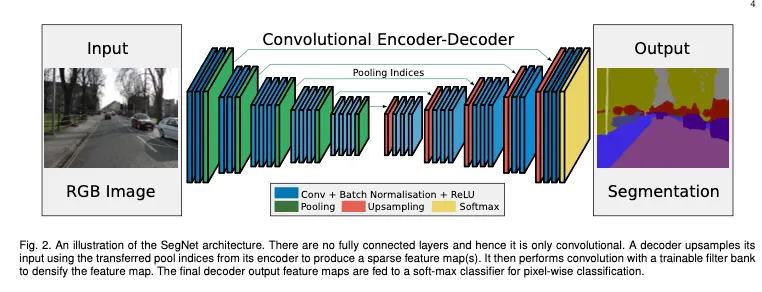
Encoder
•
ImageNet에서 pretrain된 VGG16 13개 convolutional layers 사용
•
conv - BN - ReLU 구조의 convolutional block을 기본으로 사용했다.
•
max pooling은 kernelsize와 stride2를 사용하였다.
Decoder
•
upsampling과정을 encoder에서 maxpooling할 때의 maxpooling indices를 받아와 upsampling을 수행하였다. Fig2에 보면 화살표로 표현되어 있다.
•
여기서도 역시 conv-BN-ReLU 구조의 convolutional block을 기본으로 사용했다.
•
conv는 encoder의 각 계층별 위치에 해당하는 conv와 동일한 채널 수의 피쳐맵을 출력할 수 있도록 구성하였다. (RGB 3채널의 이미지를 입력으로 받는 encoder의 첫 레이어는 제외 했다)
•
마지막에는 softmax 레이어를 classifier로 사용하였다.
Softmax는 각 픽셀별로 각 클래스에 대한 확률을 계산하여 K channel의 확률 이미지를 output으로 가지게 된다. ( K=class 수)
따라서 픽셀별로 가장 확률이 큰 class로 분류하여 최종 segmentation결과를 내놓게 된다.
SegNet은 encoder의 feature map정보를 효율적으로 decoder로 전달해 boundary delineation을 향상시키고 메모리도 아꼈다
•
UNet처럼 encoder의 feature map을 저장하는 것이 아니라 max pooling indices만 저장하는 방식으로 조금의 accuracy를 희생하고 memory를 크게 아꼈다.
Decoder Variants
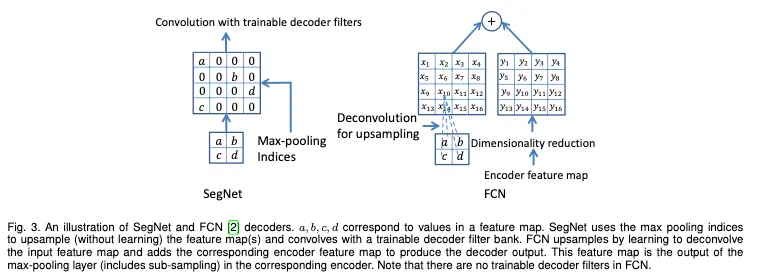
Fig 3은 SegNet과 FCN의 decoding 방법을 나타낸 것으로
•
SegNetdms Maxpooling indices를 사용한다
•
FCN은 transposed convolution 과 dimensionality reduction(skip architecture)를 사용한다
이 두 차이점을 강조한다
이후 SegNet과 FCN의 decoder구조를 변형시켜 서로 비교하고 각 요소들의 영향을 분석했음

[Performance Measure] ( FCN 논문과 동일하게 사용 )
Bilinear-Interpolatiion
•
Encoder는 SegNet-Basic과 동일하게, Decoder에 bilinear interpolation upsampling만을 사용
•
파라미터 수는 작지만 모든 test metrics가 가장 작은 것을 볼 수 있다.
•
segmentation을 위해 decoder 구조는 꼭 필요하다는 것을 알 수 있음.
SegNet-Basic
•
Encoder와 Decoder가 각각 4개의 레이어 블록으로 구성된 모델
•
upsampling using max-pooling indices 사용 → 메모리 사용량 감소
•
주의할 점은 최종 proposed model이 아니다. proposed model의 figure를 보면 레이어가 5개씩으로 이루어져 있다.
•
convolutional layer의 kernel size and no bias
•
Decoder에 ReLU사용 x
•
SegNet계열 세개 중에서는 대부분의 metric에서 2번째로 높은 성능을 보여준다.
•
FCN-Basic보다 더 적은 메모리를 사용한다. FCN은 encoder의 featuremap을 저장하기 때문에 11배나 더 많이 사용함
SegNet-Basic-EncoderAddition
•
SegNet-Basic보다 더 많은 정보를 전달하는 구조이다
•
encoder는 SegNet Basic과 동일하고
•
Decoder는 SegNet-Basic에서 추가로 encoder 각 레이어마다 64개 피쳐맵을 추출해 해당 위치 deocder layer에 더해주었다.
•
SegNet 계열에선 가장 높은 성능을 보인다
SegNet-Basic-SingleChannelDecoder
•
Decoder의 convolutional filter를 single channel로 변경해 SegNet-Basic을 더 축소시켰다.
•
trainable parameters 수와 inference time을 아주 많이 감소시켰으나 성능이 낮다.
FCN-Basic
•
Encoder는 SegNet-Basic과 동일하나 Decoder는 transposed convolution 및 diensionality reduction을 사용했다.
•
BF score가 가장 높다
•
SegNet Basic보다 inference time이 빠르다. SegNet-Basic의 decoder는 각 레이어가 64채널의 피쳐맵을 가지는데, FCN-Basic의 decoder는 dimensionality reduction을 사용하므로 각 레이어별로 11개만큼 더 적은 feature maps를 갖게된다.
SegNet Basic과 FCN-Basic은 비슷한 좋은 결과를 보이기 때문에 inference time의 중요성과 메모리 크기에 따라 적합한 모델을 사용하면 되겠다
FCN-Basic-NoAddition
•
Encoder는 SegNet-Basic과 동일하나 Decoder는transposed convolution만 사용하였다.
•
SegNet-Basic보다 성능이 떨어지게 된다’
•
encoder의 feature maps를 decoder로 전달하는게 성능 향상에 큰 영향을 미치는 요소임을 확인해준다.
•
SegNet-Basic-SingleChannelDecoder보다 낮은 성능을 보인다
•
SegNet 구조(upsampling using max-pooling indices, larger decoder) 가 더 좋은 성능을 낸다는 것을 보여준다.
FCN-Basic-NoDimReduction
•
Encoder는 SegNet-Basic과 동일하나 Decoder는 FCN-Basic에서 encoder의 정보를 더해줄 때 dimension을 축소하지 않고 바로 더해준다.
•
G와 mIOU가 가장 높은 것을 확인할 수 있다.
•
SegNet-EncoderAddition과 비교했을 때 각각은 각자의 variants에서 가장 높은 성능을 보였으나
◦
memory / inference time에 제약을 받지 않으면 더 많은 정보를 전달하는 더 큰 모델이 높은 accuracy를 보인다는 것을 보여주는 결과이다.
◦
memory - inference는 trade-off
FCN-Basic-NoAddition-NoDimReduction
•
Encoder는 SegNet-Basic과 동일하고
•
Decoder는 transposed convolution 및 dimensionality reduction 모두 사용하지 않았다.
•
SegNet-Basic보다 성능이 떨어지게 된다
•
Decoder를 단순히 크게 하는 것이 성능향상으로 가는 길이 아니고 encoder의 feature map을 decoder로 전달하는게 중요하다는 것을 보여준다
Table 1의 가장 오른쪽 두 열은 class balancing을 구행하지 않은 결과인데, class balancing을 한 결과보다 성능이 좋지 못하다. class average와 mIOU가 크게 감소한다.
Global Average에서는 성능이 약간 높게 나온다 → 도로/ 하늘/ 건물같은 큰 class들이 픽셀수를 많이 차지하기 때문이다.
<정리>
•
encoder의 featyre map을 모두 사용하면 가장 좋은 성능을 보이지만, 메모리가 많이 든다.
•
memory가 제한되면
◦
encoder의 featuremaps를 압축해 저장하는 방법을 사용 가능하다
▪
dimensionality reduction
▪
max pooling indices 저장 ( segnet type의 decoder 사용 )
•
decoder가 클수록 성능이 향상된다.
