Step 1. Azure Machine Learning wrorkspace 다루기
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Azure 리소스 그룹 생성
# Azure Machine Learning Service 워크스페이스 생성
# Get a handle to the workspace
ml_client = MLClient(
credential=credenial,
subscription_id="b9#8##4-2###-4a##-####-7##e6##5a###", # subscription_id - 구독id는 Azure Portal -> Subscription 항목에서 확인 가능
resource_group_name="resource group name",
workspace_name="workspace name",
)
Python
복사
Step 2. workspace에 model을 register하기
 Azure ML[1] Azure Machine Learning에서 머신러닝 모델 학습하기 을 모두 완료하였다면 이미 workspace에 모델이 등록되어 있다.
Azure ML[1] Azure Machine Learning에서 머신러닝 모델 학습하기 을 모두 완료하였다면 이미 workspace에 모델이 등록되어 있다. 그렇지 않은 경우 다음과 같은 코드 등록시켜준다.
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
mlflow_model = Model(
path="./deploy/credit_defaults_model/", # path to the model files, if you've stored them locally.
type=AssetTypes.MLFLOW_MODEL,
# Asset types are used to identify the type of an asset.
# An asset can be a file, folder, mlflow model, triton model, mltable or custom model.
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Python
복사
compute나 environment를 등록할 때 처럼 Model 객체를 만든 후 MLClient.models.create_or_update() 메소드로 등록해줍니다.
registed model 확인
AML studio의 workspace - Models에서 확인할 수 있습니다.

코드로는 다음과 같이 확인 할 수 있습니다.
registered_model_name = "credit_defaults_model"
# 이 코드로 등록되어있는 모델들의 리스트에서 가장 최신의 버전을 알아낸다
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version) # 최신버전
Python
복사
Step 3. Online Endpoint 만들기
모델의 학습이 끝나면 배포를 해서 사람들이 inference에 사용할 수 있도록 해야겠죠, AML은 이를 위해 endpoints를 생성하고 그것에 deployment를 추가할 수 있게 도와줍니다.
다음 그림을 보면서 이해해봅시다.
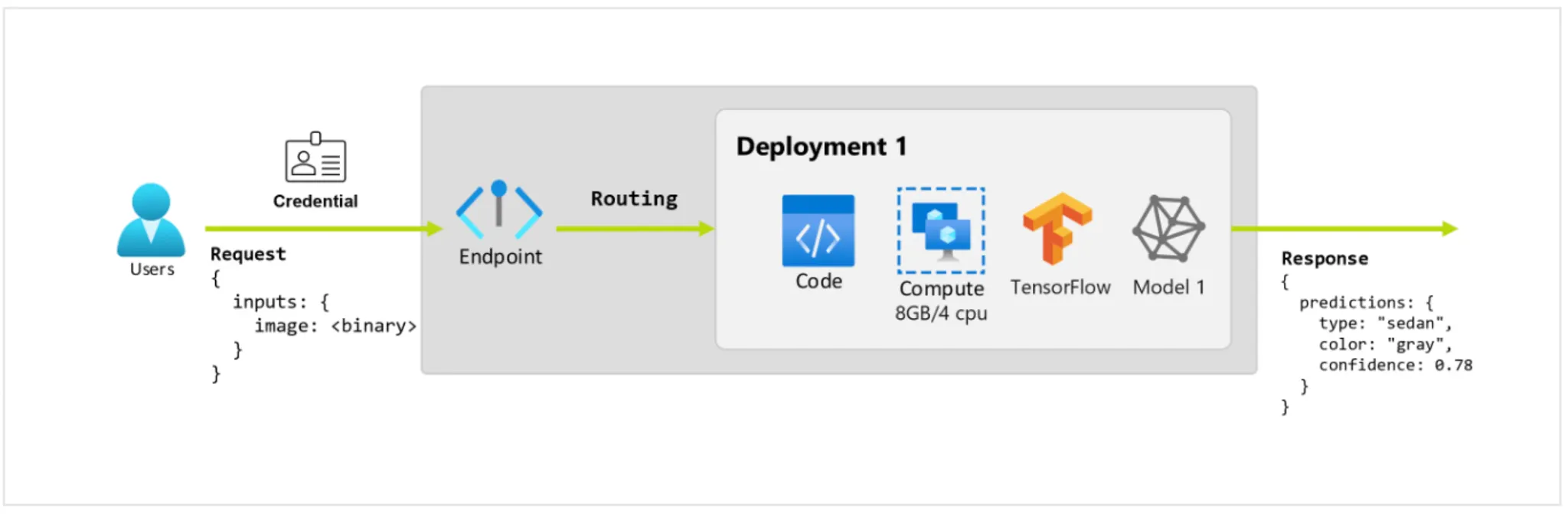
주어진 사진을 보고 차의 색과 종류를 예측하는 application이라고 합시다. 특정 credentials를 갖는 사용자가 URL에 HTTP request를 생성합니다. 그리고 request의 일부로 사진을 제공합니다. 그러면 사용자는 그에 대한 응답으로 차의 종류와 색 정보를 받게됩니다. 여기서 URL이 endpoint로서 작동하게 됩니다.
그런데 이 예측을 수행하기 위해 모델로 inference를 수행하기 위해서는 tensorflow, keras같은 라이브러리들이 있는 환경과 모델 weight, inference 코드, 연산을 수행할 compute 자원 등이 필요합니다.
이렇게 실제로 inference를 수행하는 모델과 자원들을 담고 집합이 Deployment 입니다.
다음 그림처럼 하나의 endpoint는 여러개의 deployment들과 연결될 수 있습니다.
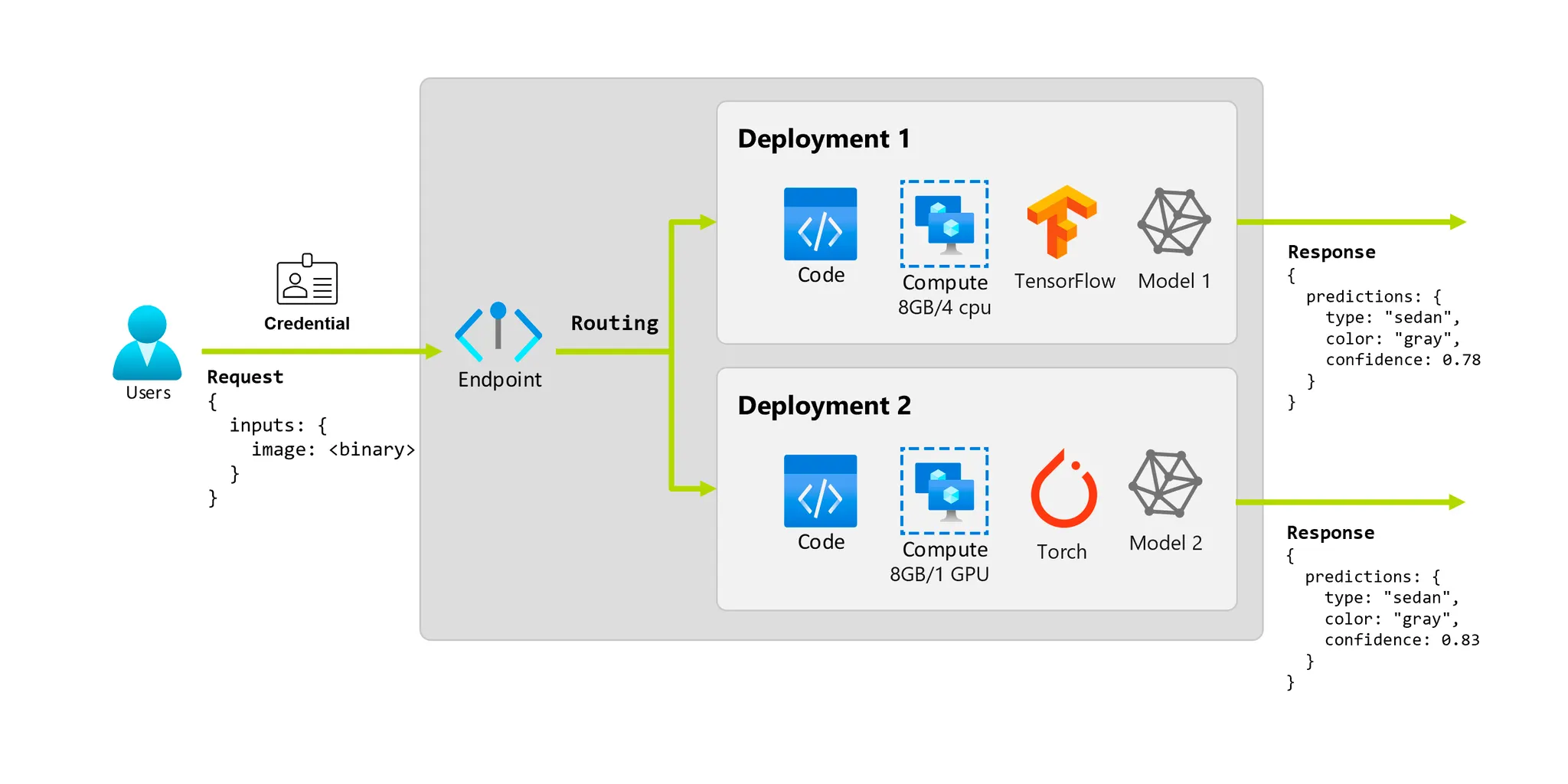
즉 endpoint는 client가 학습된 모델에 request(input data)를 보내고, inference 결과를 받을 interface를 제공해줍니다.
endpoint가 제공해주는 것들:
1.
Authentication using “key or token” based auth
2.
TLS(SSL) termination
3.
A stable and durable URI (endpoint-name.region.infernce.ml.azure.com)
endpoint 는 특정 deployments에 바로 request할 수 있는 routing mechanism을 가집니다.
endpoint에는 online endpoint와 batch endpoint가 있는데요, online endpoint는 실시간 inference를 위해 디자인 되어있고, batch endpoints는 long-running batch inference를 위해 디자인되어 있습니다. 본인의 유스케이스에 맞추어 선택하여 사용하면 됩니다. 우리는 online endpoint를 이용해 실습합니다.
이제 진짜로 endpoint를 생성해봅시다
endpoint는 Azure region 전체에서 유일해야 하기 때문에 UUID를 통해 유니크한 이름을 생성합니다.
import uuid
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Python
복사
그리고 ManagedOnlineEndpoint class로 endpoint를 정의합니다.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# Managed online endpoints help to deploy your ML models in a turnkey manner.
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name, # 이름
description="this is an online endpoint", # 설명
auth_mode="key", # key기반인증
tags={
"training_dataset": "credit_defaults", # dataset에 대한 정보를 태그로 주었다.
},
)
Python
복사
이 endpoint를 workspace에 등록해줍시다. 다음 코드는 endpoint를 생성한 후 confirmation응답을 반환해줍니다.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Python
복사
만약 endpoint를 이미 만든 상태라면 (AML studio 등에서) 다음 코드로 불러올 수 있습니다.
endpoint = ml_client.online_endpoints.get(name="credit-endpoint-db3#####")
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)# Endpoint "credit-endpoint-db3#####" with provisioning state "Succeeded" is retrieved
Python
복사
Step 4. endpoint에 model을 배포하기
deployment는 다음과 같은 중요 aspects를 포함합니다.
•
name
•
endpoint_name : deployment를 포함할 endpoint의 이름
•
model : deployment에 사용될 모델. workspace에 있는 versioned model일 수도 있고 inline model specification일 수도 있습니다.
•
environment : deployment에 사용될 environment. workspace에 있는 environment 혹은 inline specification, 혹은 conda dependencies가 있는 docker image나 Docker file일 수 있습니다.
•
code_configuration :
◦
path : model을 scoring하기 위한 source code의 경로
◦
scoring_path : 주어진 input request에 따라 모델을 실행하며, source code directory에 대한 상대경로로 표현한다. 다음과 같은 구성을 가진다.
•
instance type : 배포에 사용할 VM 의 size 지정
•
instance_count : 배포에 사용할 인스턴스 수
MLFlow model로 배포하면…
MLFlow로 만들어지고 로깅된 모델은 AML에서 no code배포가 가능합니다.
즉, scoring script / environment 제공이 필요 없습니다. scoring script와 environment가 MLFlow model을 학습 할 때 저절로 생성되기 때문입니다.
이제 하나의 deployment를 생성해보겠습니다. ManagedOnlineDeployment class로 deployment를 정의해줍니다.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of our registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue", # Blue / Green 배포
# endpoint_name=online_endpoint_name,
endpoint_name = "credit-endpoint-db3#####",
model=model,
instance_type="Standard_DS2_v2", # 이름에 주의. Korea region 사용 가능 VM 다름. https://learn.microsoft.com/en-us/azure/machine-learning/reference-managed-online-endpoints-vm-sku-list?view=azureml-api-2
instance_count=1,
)
Python
복사
blue/green 배포를 하기 위해서 blue라는 이름으로 deployment를 정의해줬습니다.
blue/green 배포는 무중단 배포 기법의 하나로, 다음과 같은 장점을 가집니다.
•
구, 신버전이 동시에 떠 있는 시간을 매우 짧게 처리할 수 있습니다.
•
롤백을 굉장히 빨리 할 수 있다. 테스트 환경에서는 문제점이 발견이 안됐는데 운영 서버에 배포를 하니 문제가 발생되면 재빨리 기존 것으로 롤백할 수 있습니다.
•
배포 과정에서 인스턴스 수가 줄지 않으므로 요청량을 처리하는 데서 오는 장애의 부담이 없습니다.
이제 이 deployment를 workspace에 생성해줍니다.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100} # 일단 blue를 100으로
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Python
복사
들어오는 traffic의 100%를 blue deplyment가 다루도록 했습니다. endpoint.traffic으로 설정하고 endpoint를 update해줌으로 설정할 수 있습니다.
에러없이 잘 배포되었는지 endpoint의 상태 확인하기
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name="credit-endpoint-db3#####")
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Python
복사
Step 5. sample data로 endpoint를 테스트하기
다음과 같은 sample data를 생성해줍니다.
./deploy.sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
JSON
복사
MLClient.online_endpoints.invoke 메소드에 endpoint 이름과 input data, endpoint내에서 test할 deployment의 이름을 넣어주면 test가 가능하다.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
# endpoint_name=online_endpoint_name,
endpoint_name = "credit-endpoint-db3#####",
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
JSON
복사
다음과 같이 결과가 출력됩니다.

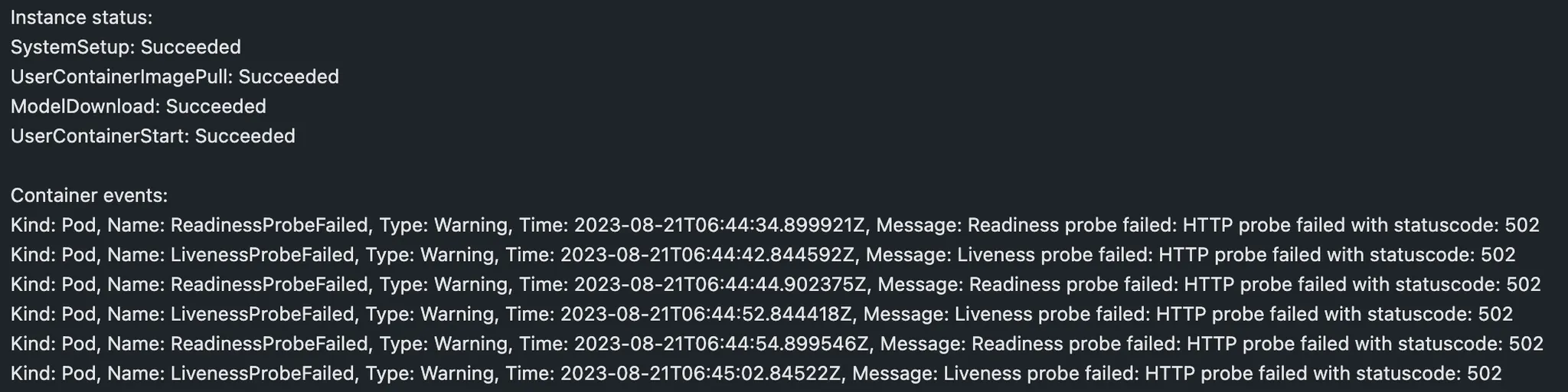
Step 6. deployment의 로그 확인하기
endpoint와 deployment가 성공적으로 호출됐는지 확인해볼까요
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name="credit-endpoint-db3#####", lines=50
)
print(logs)
JSON
복사
다음과 같이 출력됩니다.
Step 7. 두번재 deployment 생성하기
아까 blue/green 배포를 수행해본다고 했죠? 이제 green 배포를 생성할 차례입니다.
여러 deployment를 생성하여 성능비교를 수행할 수 있습니다.
deployment마다 모델의 다른 버전을 사용하거나 완전히 다른 모델일 수도 있고, 더 강력한 compute를 사용할 수도 있습니다.
green_deployment = ManagedOnlineDeployment(
name="green", # Blue / Green 배포
# endpoint_name=online_endpoint_name,
endpoint_name = "credit-endpoint-db3#####",
model=model,
instance_type="Standard_DS2_v2",
instance_count=1,
)
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
)
Python
복사
Step 8. deployments의 traffic 업데이트하기
여러 배포들에 traffic을 나누어주는데요, 이는 canary 배포를 수행하는 것이라 할 수 있습니다.
Canary 배포는 구버전 서버와 새 버전의 서버를 구성하고 일부 트래픽을 새 버전으로 분산해 오류 여부를 판단합니다. 오류율 및 성능 모니터링에 유용합니다.
endpoint.traffic = {"blue": 80, "green": 20} # Canary 배포 test
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Python
복사
sample data를 여러번 invoke해서 traffic 할당을 테스트해봅니다.
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Python
복사
green 배포가 잘 되었는지 로그를 확인해봅니다.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Python
복사
Step 9. AML studio에서 메트릭 확인해보기
workspace - endpoints - metrics에 가서 확인해봅니다.
Step 10. 새로운 deployment로 모든 traffic 보내기
green 배포의 성능이 괜찮다면 traffic을 green 쪽으로 모두 보냅니다.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Python
복사
그리고 구버전 deployment는 제거해줍니다.
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Python
복사
마무리
이 실습이 끝났다면 endpoint와 배포들을 모두 지워줍시다!
ml_client.online_endpoints.begin_delete(name="credit-endpoint-db3#####").result()
Python
복사
다음 글에서는 AzureML을 활용한 MLOps 파이프라인이 어떻게 구축되는지 살펴봅니다.
