Abstract
SOTA semantic segmentation method : 높은 성능 위해 high resolution input을 사용 → large computation budgets 필요, 자원이 제한된 기기에 적용 제한
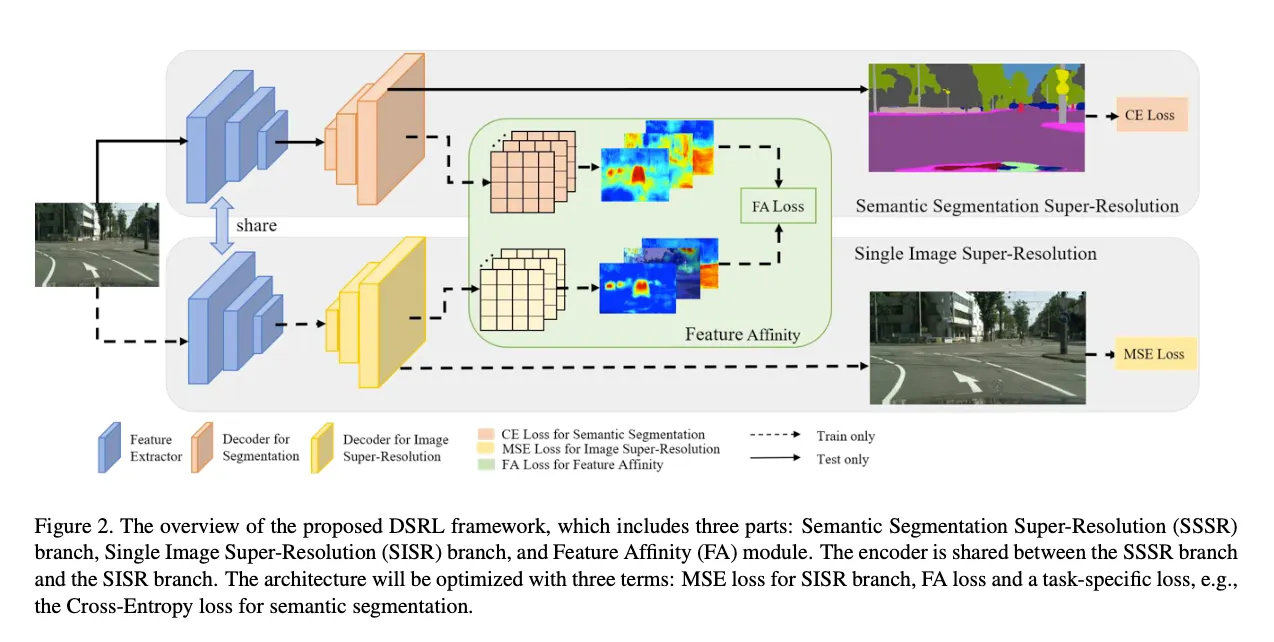
simple and flexible two-stram framework인 Dual Super-Resolution Learning ( DSRL ) 제안
→ 추가적인 computation cost없이도 segmentation accuracy 향상
모델의 3파트
1.
Semantic Segmentation Super Resolution ( SSSR )
2.
Single Image Super Resolution ( SISR )
3.
Feature Affinity ( FA )
•
low resolution input으로 high resolution representation을 유지 가능
•
model computation complexity 감소
•
다른 task에 쉽게 일반화 가능
semantic segmentation과 human pose estimation에서 테스트 수행
semantic segmentation : 비슷한 FLOPs로 높은 2% 이상 높은 mIOU 달성
human pose estimation : 같은 FLOPs로 2% 이상 높은 mAP달성 , 더 적은 FLOPs로 동일한 mAP 달성 ( 효율이 좋다 )
( 코드는 제대로 공개되어있지가 않다 )
Introduction
scene understanding → segmentation 은 필수적 task
자율주행, robot sensing 등 여러 분야 활용 가능 잠재력이 높은데 좋은 성능과 효율적 inference speed유지가 어렵다 ( 특히 mobile devices, limited resources에서 )
딥러닝의 발전으로 향상된 semantic segmentation의 성능 → high resoultion deep feature representation이 보장된 성능을 내는데에 중요한 역할을 한다

현재 HR representation을 유지하기 위한 두가지 큰 결
1.
strided convolution 대신 atrous convolution 사용 ( DeepLabs )
2.
TopDown pathway에서 피쳐맵을 합쳐 고해상도처럼 느끼도록 한다 ( Unet )
⇒ expensive computation cost
HR image input → calculation 수 많음
가벼운 Semantic Segmentation 모델의 경우에는 SOTA 비해 성능이 좋지 않음
( 큰 input을 쓰면 computation이 너무 많아지고, 큰 input을 사용하지 않으면 성능이 낮아짐 )
따라서 Super Resolution 에서 영감을 받아 DSRL 이라는 패러다임을 제안
DSRL의 구성
•
Semantic Segmentation Super Resolution ( SSSR )
•
Single Image Super Resolution ( SISR )
•
Feature Affinity ( FA )
SR의 개념을 SS에 적용
SSSR과 SISR은 동일한 feature extractor를 공유함
SISR은 SSSR을 reconstruction supervision 으로 최적화하나 inference 시에는 제거됨
제안된 방법이 유사한 FLOP로 더 높은 mIoU를 쉽게 달성할 수 있으며, 더 적은 FLOP로 성능을 유지할 수 있다는 점에 주목
그림 1에서 볼 수 있듯이, 제안된 DSRL은 특히 저해상도의 경우 다른 해상도 하에서 정확도를 크게 향상시킬 수 있으므로 유사한 성능으로 계산 비용을 크게 줄일 수 있습니다.
입력 크기가 320×640인 ESPNetv2에 비해, 256×512의 저해상도 입력 이미지를 사용하는 방법은 mIoU의 2.4%를 얻고 동시에 36% FLOP를 줄일 수 있습니다.
광범위한 실험은 의미 세분화를 위한 CityScapes와 human pose estimaition을 위한 MS COCO와 같은 두 가지 도전적인 데이터 세트에서 제안된 방법의 효과와 효율성을 보여줍니다.
Related Work
Semantic Segmentation
FCN, DeepLAbs, PSPNet 등 : 정교한 feature extraction networks 적용 ( ResNet, DenseNet 등 )
atrous conv, pyramid pooling module, attention mechanism, context encoding 등으로 발전시킴
경량화의 경우 conv 연산을 가속화시키거나 MobileNet / ShuffleNet같은 가벼운 백본 적용 혹은 경량화기술 ( pruning / 양자화 ) 적용
Simgle Image Super Resolution
1.
Pre upsampling SR
2.
Post Upsampling SR
3.
Progressive upsampling SR
4.
Iterative up and down SR
Multi-task Learning
ex ) object detection, action recognition, pose estimation, instance segmentation
여러 task를 함께 다루는 ( training / test 모두에서 ) 것들
이논문에서는 SISR은 보조일 뿐이며 test시에는 제거된다
Proposed Approach
Encoder Decoder framework
deeplab 논문을 보면 나오는 output stride
output stride ( OS ) : ‘Input 이미지 해상도’와 (Global Pooling을 하기 전) ‘Output 해상도' 의 비율로 정의했습니다. Semantic Segmentation은 더 빽빽한 특징맵이 필요하기 때문에 16 또는 8로 조절해줍니다 (output stride 가 작을수록 계산비용이 증가합니다.) 조절하는 방법으로는 마지막 block 에서 stride 를 없애거나, atrous convolution 으로 대체하는 등의 방법을 사용합니다. ( input 크기 / output 크기 )
높은 성능을 위해서는 보통 OS는 16 혹은 8이어야 한다 → 마지막 하나 혹은 2개의 strided conv를 atrous conv로 바꾸는 방식으로
Decoder의 경우에는 downsampled featuremap을 기반으로 bilinear upsampling 을 해준다( OS 를 scaling factor로 ) 혹은 간단한 subnetwork로 upsample을 해주기도 한다 → segmentation 결과를 refine하는 용도
대부분의 현존하는 방법들은 피쳐맵을 input과 같은 크기로 upsample 한다. 보통 데이터셋을 조금 줄여서 사용하는데 그러면 라벨맵도 크기를 조정해야한다. 그러면 라벨의 정보를 잃게되는 문제가 있다
반면 디코더에만 의존해 모든 original details를 복원하는 것은 어려운 일이다
Dual Super-Resolution Learning

Feature Affinity 

p=2, q=1로 설정했다고 한다
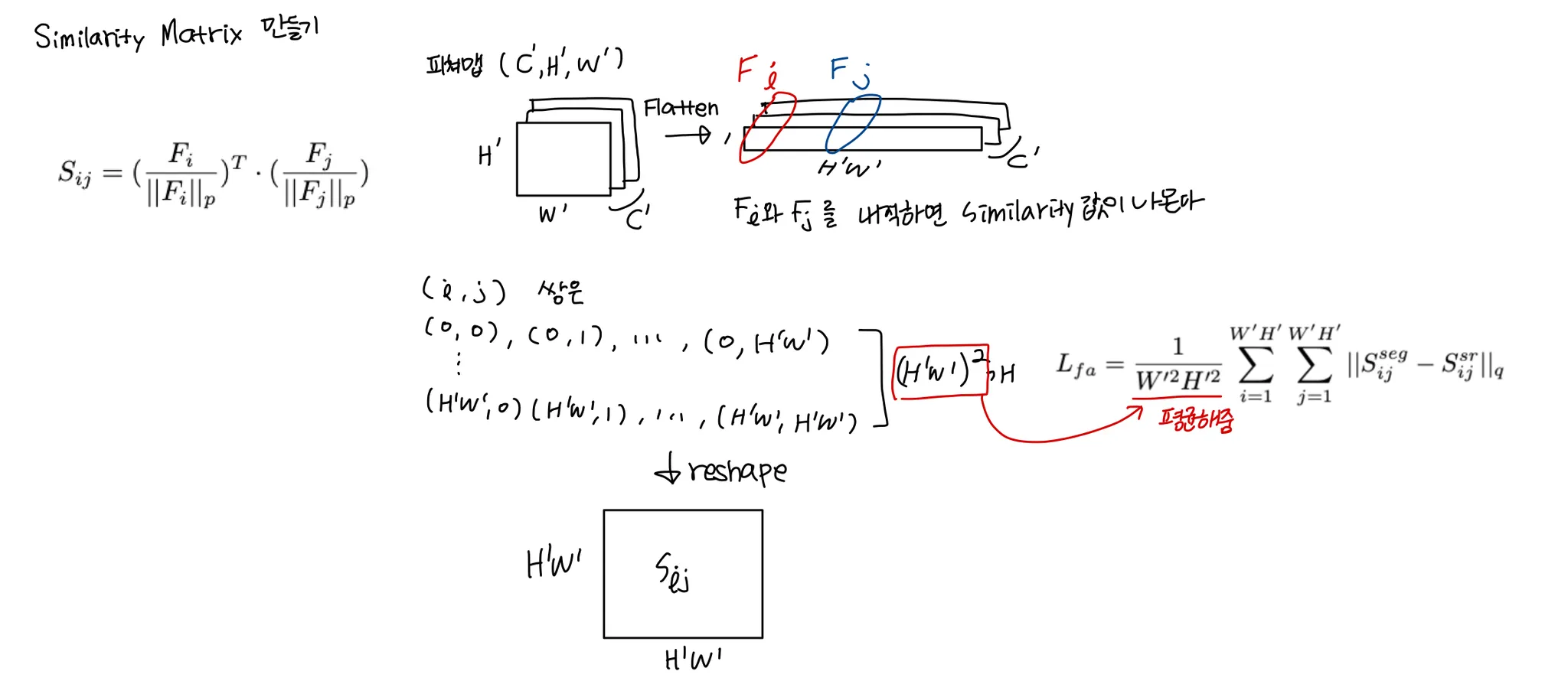
그러나 이 과정은 모든 픽셀간의 affinity를 연산하는 것이라 매우 큰 memory overheads를 갖는다. 그래서 픽셀들의 쌍을 1/8로 subsample하여 사용한다(Average Pooling) → H, W를 1/8했다
SISR과 SSSR 사이의 feature distribution의 불일치에 의한 학습 불안정성을 줄이기 위해 SSSR 브랜치의 피쳐맵에 FA Loss 반영 전 feature transform 모듈을 추가한다.
feature transform 모듈 : 1x1conv - BN - ReLU
최종 Loss

이 default 값이다
Experiment for Semantic Segmentation
Dataset
•
CityScapes : 2975 training 500 validation 1525 test, 1024x2048
•
Camvid : 960x720
Implementation Details
•
network : DeepLabv3, ESPNetv2, PSPNet, BiseNet, DABNet
•
training : Pytorch implementation, SGD(momentym 0.9, weight decay 0.0005)
•
lr initialize 0.01
•
SR model : ESPCN
Ablation Study
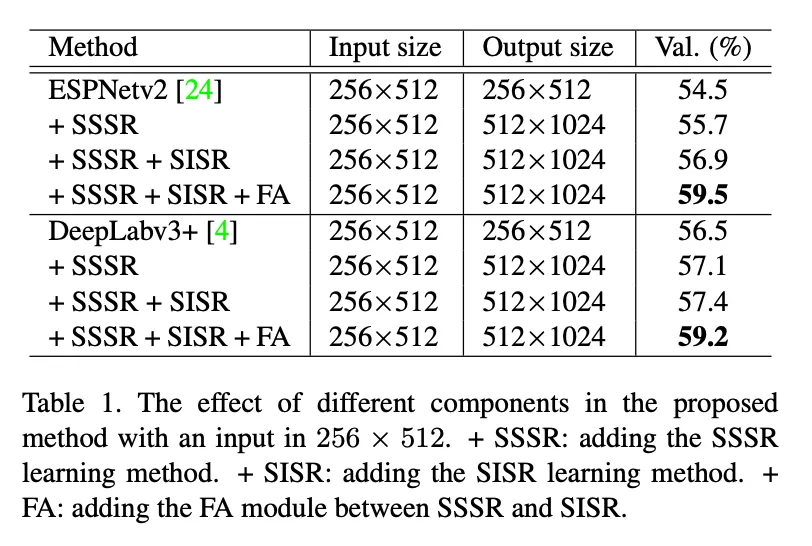
다양한 input 해상도에서

CityScapes

Camvid

DSLR for Human Pose Estimation

conclusion
이 작업에서, 우리는 Semantic Segmentatio를 위한 Dual Super REsolution Learning 제안
SSSR 브랜치는 dense label prediction을 위한 고해상도 표현을 배우는 데 도움이 되며, SISR는 상세한 구조 정보를 복구할 수 있으며, FA 모듈은 상세한 구조적 형성을 통해 시맨틱 세분화의 고해상도 표현을 향상시키기 위해 배포됩니다.
이 접근은 다양한 최근 발전한 네트워크와 결합하면 매우 효과적이고 다른 task로도 확장될 수 있다.
