
데이터의 이동 평균을 구할 때,오래된 데이터가 미치는 영향을 지수적으로 감쇠(exponential decay) 하도록 만들어 주는 방법.

(예시) Temperature in London
…
…
이 데이터의 시간의 흐름에 따른 변화를 그리고싶다면 어떻게 해야할까?
으로 정의하고,
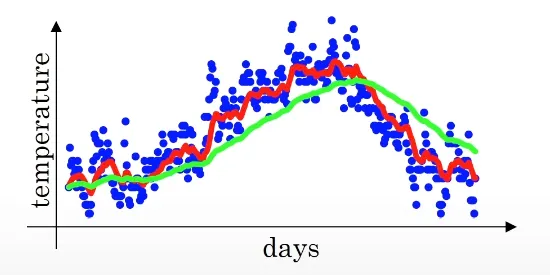
이라고 정의해 이를 그래프로 그리면
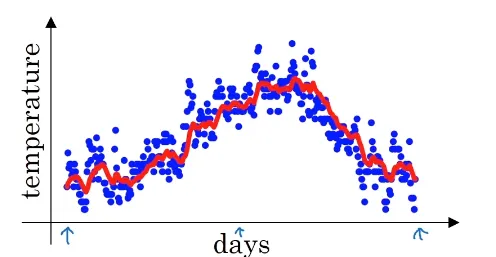
위의 빨간 선과 같다. 이런 방식이 지수 가중 평균이다.
0.9를 로 표기하면
이렇게 식을 정의할 수 있다.
이때 는 0~1 사이의 값을 갖는 하이퍼파라미터이고, 는 새로 들어온 데이터라고 생각하면 된다.
는 현재의 경향을 나타내는 값이라고 이해하자.
왼쪽의 부분은"과거의 경향성"이고,+ 이후의 (1-β) * 는 새로운 경향성을 나타내기 위해 새로 들어온 데이터를 반영하는 (최신의 기온을 평균 산식에 넣어주는) "새로운 경향성" 이라고 이해할 수 있다.
는 대략적으로 의 평균과 같다.
이유
이면 는 10일간의 기온의 평균과 유사한 것이다.
이면 는 50일간의 기온의 평균과 유사해지고 아래 그래프의 초록색 선과 같아진다
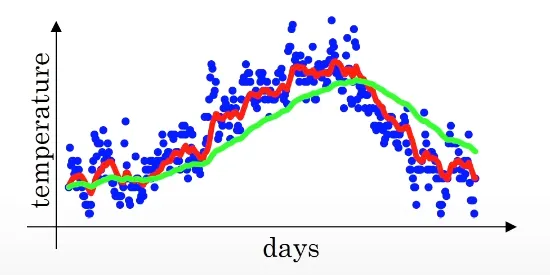
더 많은 날짜의 기온의 평균을 이용하기 때문에 초록색 선이 비교적 좀 더 부드럽다.
다르게 말하면, 기온의 변화에 더 느리게 적응하게 된다. 따라서 날씨 예측에 더 지연이 생기게 된다.
이유를 생각해보면, 로 크게 적용시키면, 이전 값에 더 큰 가중치를 주고 현재 기온에 더 작은 가중치를 주게된다. 그래서 온도가 상승하면 더 느리게 적응하게 된다.
아예 반대의 극단적인 예시로라면? → 2일간의 평균만 이용하게 되고 아래의 노란 그래프와 같아진다
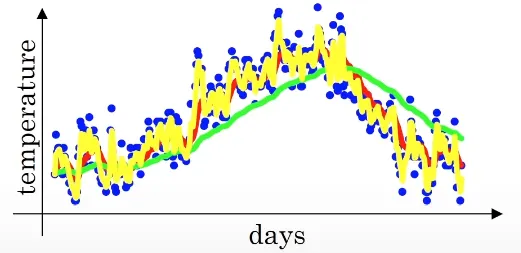
확실히 기온 변화에 빠르게 적응하지만, 이상치에 민감하고 noise가 더 많아진다
이제 이 공식을 을 구하고, 가 0.9라는 가정으로 나열해보면
이렇게 된다. “지수적으로(exponentially)" 감소하는 모습을 볼 수 있다
( 값들 앞에 곱해지는 계수들을 모두 더하면 1 혹은 1에 가까운 값이 되는데, 이를 bias correction이라고 할 수 있다고 한다. )
이렇게 되기때문에 만약 라면 10일 뒤에는 가중치가 현재 가중치의 배정도로 줄어든다
보통 V_0 = 0으로 초기화하고
…
가장 최근의 값만 저장하면 되므로 매우 단순하고 하나의 실수를 저장하는 메모리만 필요하다
→ 한 줄의 코드만 필요
bias correction
bias correction을 통해 평균을 더 정확히 계산할 수 있다.
원래 위에서일 때 초록색 곡선을 얻을 수 있을 것이라고 했는데,
이렇게 구현하면 초록 곡선을 얻을 수 없다.
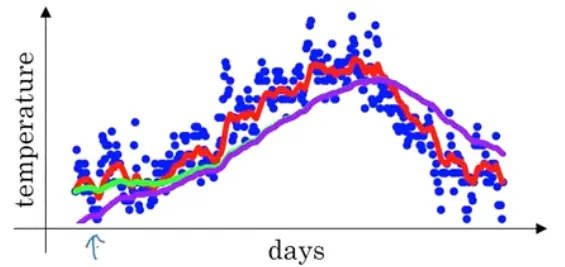
더 낮은 곳에서 출발하는 보라색 곡선을 얻게된다.
이를 고치려면 bias correction이 필요하다.
일 때
가 양수라면 v_2의 값은 보다 매우 작아진다
처음 두개의 예측값이 매우 안좋아질 수 있는 것이다.
특히 이 초반의 추정값을 더 낫게 하는 것이 bias correction이다.
대신 를 취하는 것이다.
ex) t=2 :
⇒ 과 의 weighted average에 bias를 없앤 값이라고 할 수 있다.
⇒ t가 커질수록 는 0에 가까워진다 ⇒ t가 충분히 커지면 bias correction의 효과는 사라진다
⇒ 보라색 선에서 초록색 선에 가까워진다.
