
Abstract
전통적으로 image denoising 과 high level vision tasks는 개별적으로 생각되어왔으나
이 논문에서는 두가지를 함께 생각하고 상호간의 영향을 탐구
1.
cnn for image denoinsing 제안 → SOTA 달성
2.
deep neural network solution 제안 : denoising을 위한 module과 다양한 high level task를 위한 모듈 두가지를 결합
backpropagation으로 denoising network만을 업데이트 하는 joint loss 사용
•
denoiser가 다양한 high level vision tasks의 성능 저하를 극복할 수 있는 일반성(generality)을 가지고 있음을 보여줍니다.
•
high level vision 정보의 가이드로, denoising network는 더욱더 시각적으로 어필이 되는 결과를 생성할 수 있다
우리가 아는 한, 이것은 딥 러닝을 통한 image denoising 과 high-level vision tasks을 위해 image semantics를 동시에 활용하는 이점을 파악하는 첫 번째 작업입니다.
Introduction
Image denoising - low level vision problem 의 한 대표로써, 그것의 noisy measurement로부터 잠재된 image signal을 복원시키는 데에 전념되어 왔다.
classical image denoising 방식은 이미지의 local 혹은 non-local 구조를 사용한다.
더 최근에는 여러 딥러닝모델들이 이미지 denoising을 발전시켜왔고 좋은 성능을 보였다
U-Net에서 영감을 받아 이미지 denoising 을 위한 CNN을 제안하며 SOTA 성능을 달성했다
널리 사용되는 이미지 노이즈 제거 알고리즘은 평균 제곱 오차(MSE)를 최소화하여 영상을 재구성하지만, 중요한 이미 세부 정보는 대개 손실되어 영상 화질이 저하됨.
e.g. some texture-rich 영역에서의 over-smoothing artifacts : conventional method로의 denoised output에 흔히 발견된다

conventional method로의 denoised output
목표달성을 위해 image denoising을 high-level vision network에 연결시키는 cascade architecture를 제안한다.
우리는 image reconstruction loss와 high level vision loss를 jointly minimize
image semantic information의 가이드로 denoising network가 더욱더 visual quality를 향상시킬 수 있고 비주얼적으로 더 어필이 되는 결과를 생성할 수 있다. 이것이 image denoising에서의 semantic information의 중요성을 보여준다
high level vision tasks는 noisy data에서 수행될 때에는 일반적으로 독립적인 이미지 복원 스텝이 전처리로서 적용된다. 이는 궁극적인 목표에 대해 최적이 아니다.
최근의 연구에서는 이미지 분류를 위해 학습된 neaural networks가 small noise pertubation(섭동)이나 다픈 artificial patterns에 쉽게 속아넘어갈 수 있다는 것이 밝혀졌다.
그러므로 application-driven denoiser은 노이즈 제거와 semantic-aware details 유지가 동시에 가능해야 한다.
joint loss로 학습된 cascaded network는 denoising 네트워크 성능을 boost시킬 뿐 아니라 부가적으로 high level vision tasks의 정확도도 향상시킨다는 것을 보여준다
게다가 우리의 제안된 학습 전략은 학습된 denoising 네트워크가 different hugh-level vision tasks에 충분히 robust하게 만든다. 다시말해서, 하나의 high vision tasks로 학습된 우리의 denoising module은 finetuning없이 바로 다른 high-level vision task에 플러그인 될 수 있다.
2. Method
먼저 우리의 프레임워크에서 작동하는 denoising network를 소개한 후 image denoising module과 high-level vision tasks 모듈간의 관계에 대해 자세히 설명한다
2.1. Denoising Network
image denoising을 위한 CNN 을 제안
noisy image가 input, reconstructed image가 output
이 네트워크는 downsampling과 upsampling연산으로 feature contraction과 expansion을 수행한다
각 downsampling과 upsampling 쌍은 새로운 spatial scale로 feature representation을 가져와 전체 네트워크가 정보를 다른 scale들로 처리할 수 있게 한다
특히 각 스케일에서 input은 이전 스케일로부터의 피쳐가 downsampling이후에 인코딩된다.
다음 스케일의 피쳐로 피쳐 인코딩 및 디코딩 후, 출력은 업샘플링되고 이전 스케일의 피처와 융합됩니다.
이러한 각 downsampling과 upsampling 단계 쌍은 더 많은 spatial scales의 피쳐표현으로 더 깊은 네트워크를 쌓기 위해 중첩될 수 있다.
computation cost와 restoration accuracy사이의 tradeoff를 고려하여 우리는 세개의 scale을 denoising network를 위해 선택했다.(실험적으로)
이 연산들은 input과 target output 사이에 residual을 학습하도록 설계되었으며 가능한 많은 디테일을 복원한다. 그래서 우리는 long distance skip connection으로 이 연산들의 output과 input image를 더해주어 reconstructed image를 생성했다.
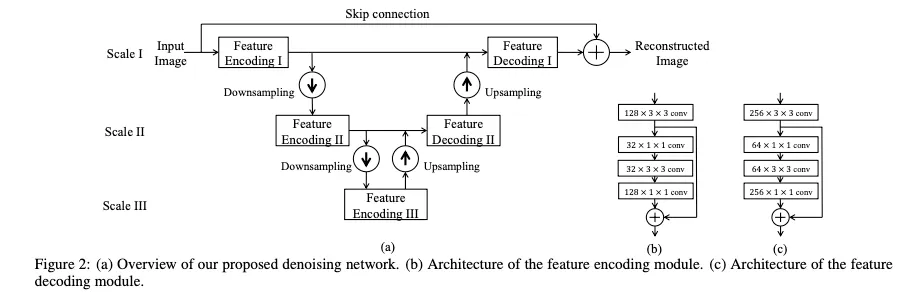
(a)가 denoising network의 oveview이다.
Feature Encoding
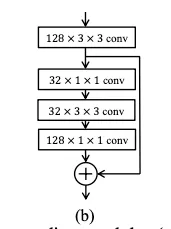
Architecture of the feature encoding module.
각 스케일 당 하나의 feature encoding module을 디자인 했다. 하나의 conv layer와 하나의 residual block이 있다.
각 conv 레이어는 바로 spatial Batch Normalization 과 ReLU가 따라온다는것을 명심
위에서 아래순으로 4개의 conv 레이어들
128, 32, 32, 128 : kernel 수
3x3, 1x1, 3x3, 1x1 : kernel size
첫 conv 레이어의 아웃풋은 skip connection 된 후 element-wise 로 마지막 conv 레이어 아웃풋에 더해진다

Architecture of the feature decoding module.
두개의 인접한 스케일로부터의 정보를 fusing하기 위해 디자인됐다.
두 fusion schemes 가 테스트 됐다
1.
두 스케일에서의 피쳐 concatenation
2.
element-wise sum of them
두가지 모두 비슷한 denosing 성능을 얻었다. 그래서 우리는 첫번째 방식을 선택했다. 두 스케일에서 다른 채널의 feature representations를 얻기 위함이다.
왼쪽의 feature encoding module과 유사한 아키텍쳐를 사용
Feature Downsampling & Upsampling
Downsampling 연산은 점진적으로 뒤따라오는 conv kernel들의 receptive field를 늘리고 피쳐맵 사이즈를 줄여 computational cost를 줄이기 위해 여러번 적용된다.
더 큰 receptive field는 kernel들이 denoising을 위한 더 큰 공간적 context를 포함하게 해준다
2를 downsampling 및 upsampling factor로 사용했다 ( 2배씩 upsampling, downsampling )
그리고 downsampling하는데에 2개의 방식을 사용했다.
1.
stride2로 maxpooling
2.
stride2로 conv 수행
두개 다 비슷한 denoising 성능을 보여 computation efficiency를 위해 두번째 방식을 사용했다.
upsampling 연산은 4x4 kernel의 deconvolution으로 수행되었고, featuremap을 이전 scale과 같은 사이즈로 확장시키는 목적이다
proposed denoising 네트워크의 모든 연산이 spatially invariant(불변)하고, 임의의 크기의 입력 이미지를 처리한다는 장점이 있다.
2.2. When Image Denoising Meets High-Level Vision Tasks
1.
high level vision information으로 가이드를 받아 denoising network의 결과물로 시각적으로 만족할만한 결과를 reconstruct
2.
오직 하나의 high level vision task를 위해 학습된 경우에도 다양한 high-level vision tasks에서 충분히 좋은 accuracy에 도달.
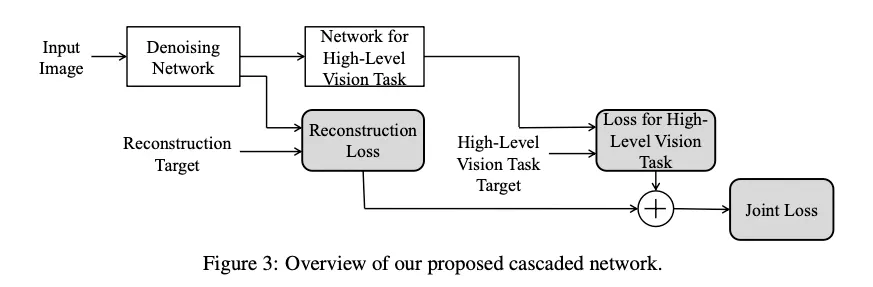
주어진 noisy input에 denoising network가 먼저 적용되고, denoised result가 뒤따라오는 highlevel vision task 위한 네트워크에 feed된다 그리고 high level vision task 결과를 생성한다.
Training Strategy
1.
high-level vision task를 위한 네트워크를 noiseless setting에서 잘 train된 네트워크로 initialize
2.
high-level vision task를 위한 네트워크의 weights를 fixing하면서 두 네트워크의 결합을 end-to-end로 학습시킨다
3.
denoising network의 weights만이 high level vision task network로부터 error backpropagtion으로 업데이트된다. image super resolution에서 perceptual loss를 최소화 하는 것과 유사하다
이런 training starteg를 적용하는 이유는 학습된 denoising network를 다양한 high level vision task에 대한 generality를 잃지 않으면서 충분히 robust하게 만들기 위해서이다
더 자세하게는, 우리의 하나의 high level vision task위해 학습된 denoising module이 다른 high level vision task에 두 네트워크 모두 finetuning없이 바로 플러그인될 수 있게하기 위해서이다
우리의 접근방식은 noisy과 noise-free images에 high-level vision task 네트워크가 일관되게 수행되도록 유지하면서 다양한 high-level task에 노이즈 제거를 적용할 때 train effort를 용이하게 할 뿐만 아니라 노이즈 제거 네트워크가 고품질의 perceptual and semantically faithful result를 도출할 수 있도록 한다.
Loss
denoising network의 reconstruction loss : MSE → 노이즈 없는 이미지와 denoising network통과한 output의 차이
classification network와 segmentation network 의 loss : cross-entropy loss → predicted label 과 ground truth label의 차이
joint loss : 두 loss의 weighted sum
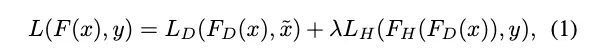
: noisy input image
: noiseless image
: high level vision task의 ground truth label
: denoising네트워크
: high-level vision task 네트워크
: 전체 cascaded network
Experiment
3.1. Image Denoising
제안된 네트워크는 RGB images를 input으로 하고 reconstructed images를 output으로 바로 내놓는다
training에 원본 이미지에 평균이 0인 independent and identically distributed Gaussian noise를 추가한 noisy input을 사용했다
•
[Chen et al,. 2014]와 같이 training set 구성
•
= 0으로 loss 사용 → denoising network만의 성능 확인
•
SGD
•
batchsize 32
•
input patches는 48x48
•
initial learning rate : 10^{-4}, 500,000 iteration 마다 10으로 나눠짐
•
training은 1,500,000 iterations 후 중지
우리의 실험에선 각 noise level 별로 각각 다른 denoising network를 학습시켰다
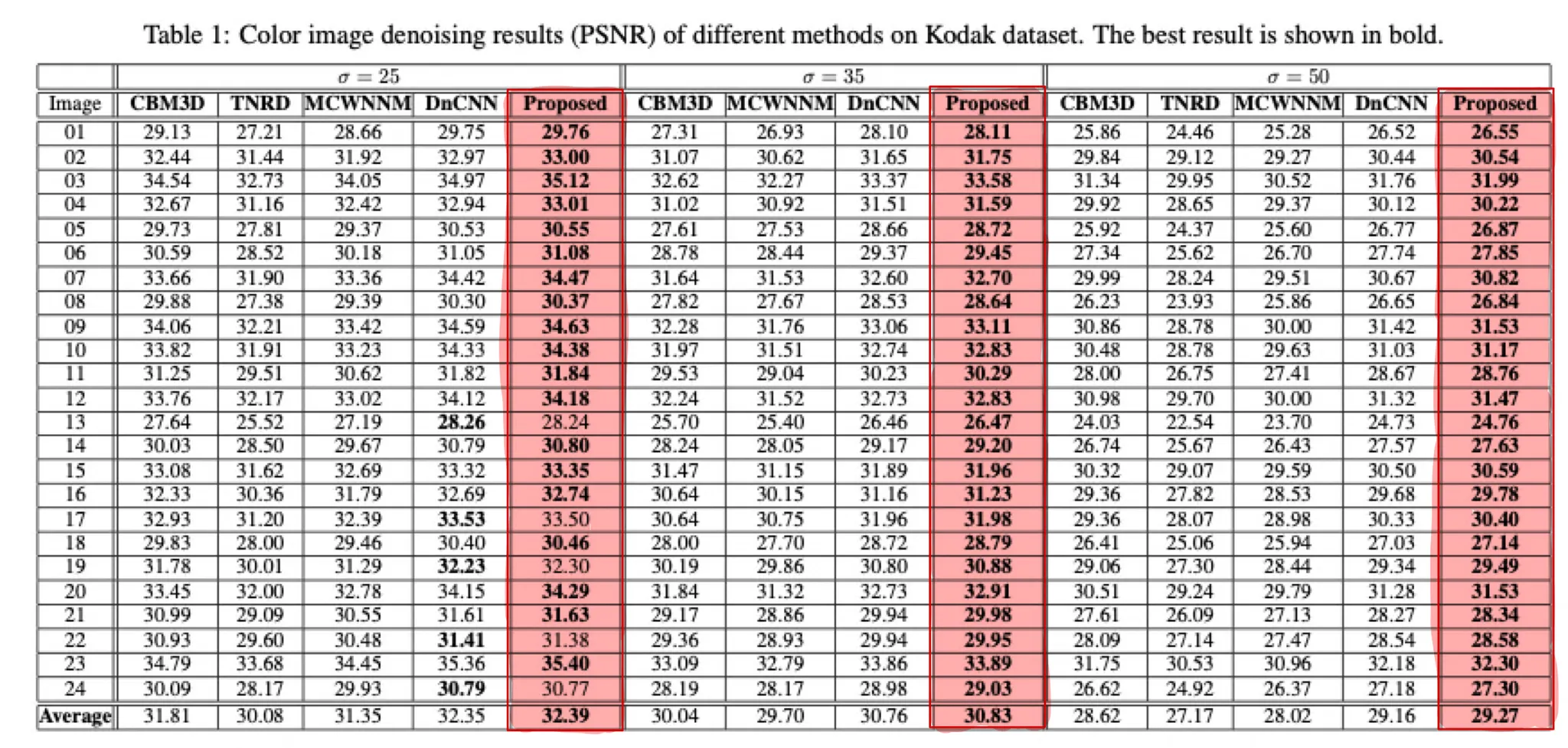
다양한 noise 정도에서, (=25, 35, 50) 다양한 SOTA color image denoising approaches와 비교했다
Kodak dataset( 24 color images )
3.2. When Image Denoising Meets High-level Vision Tasks
두개의 high level vision task 설정 : image classification , image semantic segmentation
image classification :
VGG-16
ILSVRC 2021 dataset
semantic segmentation :
DeepLab-LargeFOV
Pascal VOC2021 dataset
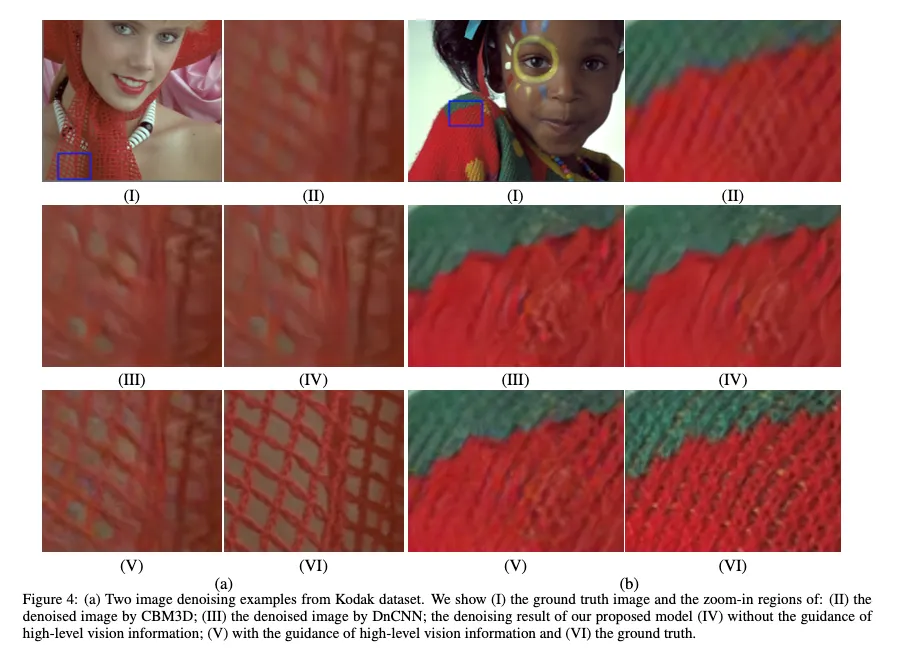
semantic segmentation network의 도움으로 denoising network를 학습시킨다고 해서 더 높은 PSNR이 나온 것은 아니지만 Kodak dataset으로 눈으로 보았을 때 detail 보존이 잘 되고 texture가 더 좋다 ( 5번 사진 )
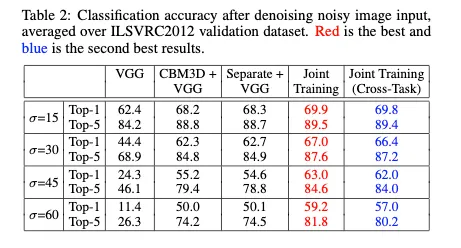
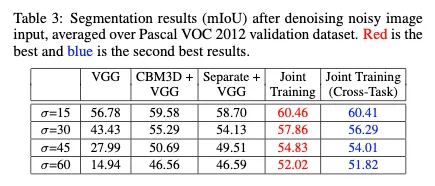
cases :
•
noisy image 곧바로 VGG-16에 넣을 때
•
noisy image를 CBM3D로 넣고 나온 결과를 VGG-16에 넣었을 때
•
denoising network를 lambda를 0으로 해 따로 학습한 후 그 결과를 VGG에 넣어 나온 결과
=45일 때 CBM3D보다 top1성능이 떨어진다
•
논문에서 제안하는 cascade network사용 → 성능 가장 좋다
•
denoising network를 classification network와 연결해 학습 후 semantic segmentation network 연결했을 때의 성능이 Joint Training 성능. Table3에서는 그 반대 ( 성능차이거의 없음)

