관련논문들
Inception v1 (GoogLeNet)
2014년 IRSVRC 1등한 모델이다.
2012년의 AlexNet보다 12배 가량 적은 파라미터 수를 갖는다.
딥러닝은 망이 깊고, 레이어가 넓을수록 성능이 좋다고 알려져있었는데,
1.
overfitting
2.
gradient vanishing
등의 현실적 문제로 실제로는 그렇지 않았다(학습이 어려웠다) 이를 해결하기 위해 고안한 내용들이 들어있다.
•
Dropout과 같은 경우를 보면 노드들이 Sparse하게 연결되어있어야 성능이 좋다고 한다
→모든 노드에 연결하는 것이 아닌 관련성이 높은 노드들끼리만 연결하는 방법
→ 논문에선 데이터의 확률분포를 아주 큰 신경망으로 표현할 수 있다면, (신경망은 사후분포posterior distribution로 취급 가능) 실제로 높은 상관성을 갖는 출력들과 이 때 활성화되는 망 내의 노드들의 클러스터들의 관계를 분석해 최적의 효율을 갖는 topology(망구성방식)을 구성할 수 있다고 함

•
실제 컴퓨터 연산에 있어서는 연산 matrix가 dense해야 즉, 사용되는 데이터가 uniform distribution을 가져야 쓸데없는 리소스 손실이 적다.
•
전체적으로 망내 연결을 sparse하게 하면서 (Sparsity를 높이면서) 세부적인 행렬 연산은 dense하도록 처리하도록 노력했다 → Inception Module
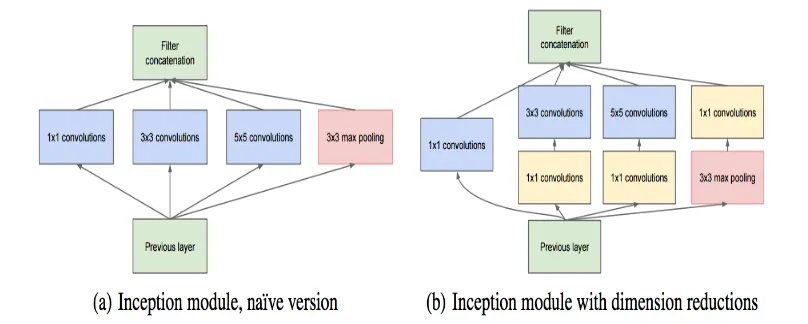
다른 모델은 7x7 등 하나의 Convolution 필터로 진행을 하는데 여기서는 이런 식으로 작은 Conv 레이어 여러 개를 한 층에서 구성하는 형태를 취한다.
•
1x1 conv layer
채널수 조정에 집중하고 다른 레이어들은 공간 정보에 집중( 역할 분담 )
파라미터 수를 줄이는 방법
1x1conv를 단순히 곱 연산이라 생각하고 3x3 conv를 곱의 합으로 생각하면 곱*(곱의 합) 의 형태로 비선형성이 더 더해질 수 있음
또한 곱연산과 같이 생각할 수 있으므로 한 픽셀씩 집중하여 중요한 성분을 강조하는 역할도 할 수 있다
•
(b) 는 개선 모델
◦
사실 5x5 연산도 부담이다. (참고로 Inception v2. 에서는 이걸 3x3 연산 2회로 처리. 이건 뒤에 나온다)
◦
그래서 이 앞에 1x1 Conv 를 붙여 C 를 좀 줄여놓고 연산을 처리한다. (그래도 성능이 괜찮다고 함)
▪
이로 인해 계산량이 많이 줄어든다.
◦
Max-Pooling 의 경우 1x1 이 뒤에 있는 이유
▪
출력 C 의 크기를 맞추기 위해 사용.
▪
Max-Pooling 은 C 크기 조절이 불가능하다.
⇒ Conv연산을 여러개의 작은 필터 사용하는 conv연산의 조합으로 쪼개 정확도는 높이고 컴퓨팅 작업량은 줄였다.
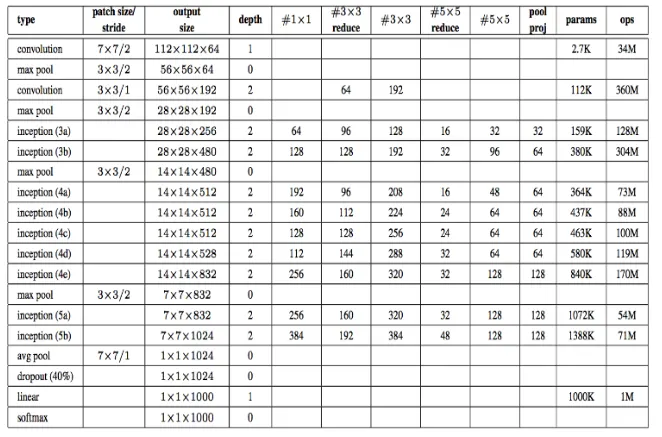
레이어 초반에는 inception 모듈을 사용하지 않는다 그 영역을 stem 영역이라고 한다.
실험적 결과로 초반 레이어에서는 인셉션 모듈의 효과가 크지 않아서 이다.
'’reduce’’ 라고 되어 있는 값은 앞단 1x1 Conv 의 C(channel) 값을 의미한다.

노란색의 softmax영역이 세개 → 세 부분에 Loss 존재 (보조 loss)
추론(inference)시에는 이 노드를 그냥 삭제해버림
→보조 Loss의 경우 v2. v3으로 갈수록 잘 쓰지 않았고 지금도 거의 쓰지 않는다 → 여러 지점에서 backpropagation을 함으로써 gradient간의 충돌이 일어날 수 있기 때문
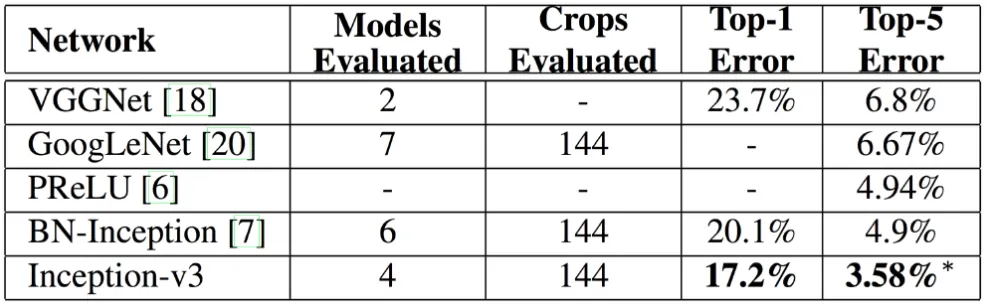
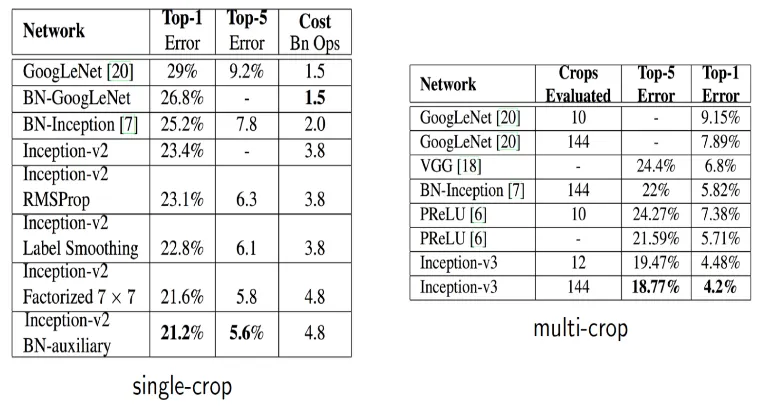
<성능 결과>
inception v2
여기서 Neural Net디자인 원칙은 다음과 같다
1.
Avoid representational bottlenecks, especially early in the network
특히 네트워크 초반에서는 representational bottleneck을 주의
2.
Higher dimensional representations are easier to process locally within a network.
높은 차원의 representation들에서는 네트워크 내에서 지역적으로 처리하기가 더 쉽다
3.
Spatial aggregation can be done over lower dimensinal embeddings without much or any loss in representational power
공간적 집계은 표현력 손실 없이 낮은 차원의 임베딩들에 대해 수행될 수 있다.
4.
Balance the width and depth of the network.
네트워크의 width(채널수) 와 depth(깊이, 레이어 수)의 균형을 맞춰줘야 한다.
v2에서는 5x5 conv연산도 크다고 판단하고 3x3conv 두개로 바꾸어 파라미터는 줄이면서 receptive field를 유지했다
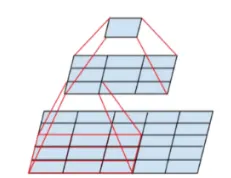
그림으로 보면 이러한 변화가 있다
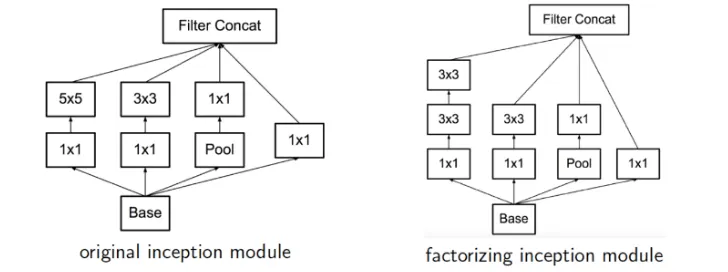
•
변화가 Loss에 영향을 주는가 → 실험의 결과는 성능이 괜찮았다고 한다
•
첫번째 conv 레이어의 activation함수는 무엇으로 해야하는가 → ReLU, Linear 테스트 결과 ReLU가 조금 더 좋았다고 한다.
v2에넌 이와 더불어 비대칭(Asymmetric) Conv 를 사용한 Factorization을 소개한다

연산량을 줄이며 conv를 수행하는 또 하나의 방법이다.
일반적으로 NxN형태로 Conv를 수행하는데 이를 1xN과 Nx1로 구성한다
계산해보면 연산량이 33% 줄어든다고 한다
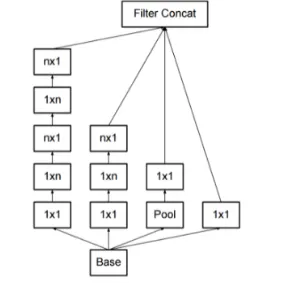
Representational bottleneck
CNN은 maxpooling을 통해 featuremap 의 grid크기를 줄이는데, pooling은 언제나 conv와 함께해야 한다
pooling을 먼저하기 / conv를 먼저하기 ⇒ 어떤 것이 더 효율적일까
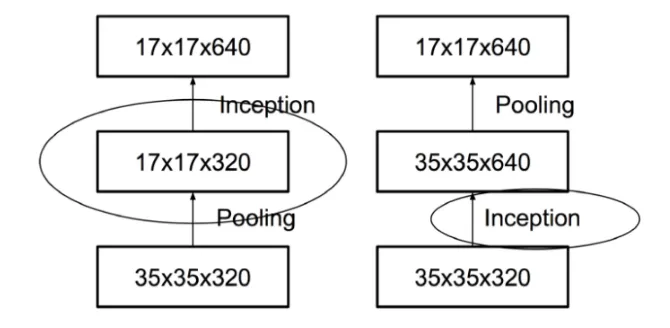
왼쪽 : pooling먼저, 오른쪽: conv먼저
Pooling을 먼저하면 Representational bottleneck 이 발생( 정보가 손실된 상태에서 conv를 진행하게됨)
ex) (d,d,k) → (d/2, d/2, k)의 conv 연산( 그림에서 d=35, k=320)
연산수를 계산해보면
pooling + stride1 conv 연산 (2k개 필터 ) :
stride1 conv 연산 (2k개 필터 ) + pooling :
연산량은 pooling을 먼저 할 때가 더 작긴하지만 Representational bolleneck발생
conv를 먼저하면 정보손실은 적으나 연산량이 4배이다
연산량을 낮추면서 Representation Bottleneck 을 없애는 구조를 고민

•
두개를 병렬로 수행한 뒤 합치는 것. (먼저 오른쪽 그림을 보자)
•
이러면 연산량은 좀 줄이면서 Conv 레이어를 통해 Representational Bottleneck을 줄인다.
•
이걸 적용해 변환한 모델이 왼쪽
⇒ inception v2
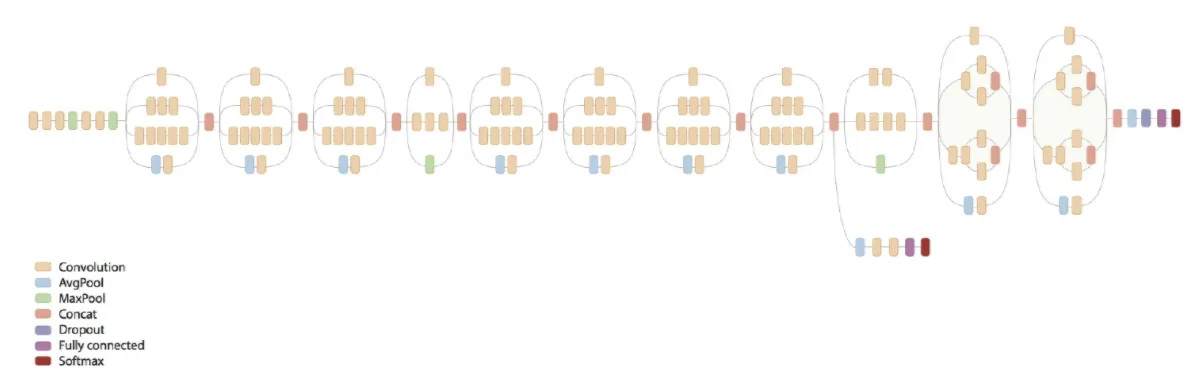
•
잘 보면 레이어 앞단은 기존 conv 레이어와 다를 바 없다. (stem 레이어)
•
중간부터 앞서 설명한 기본 inception 레이어 들이 등장한다.
•
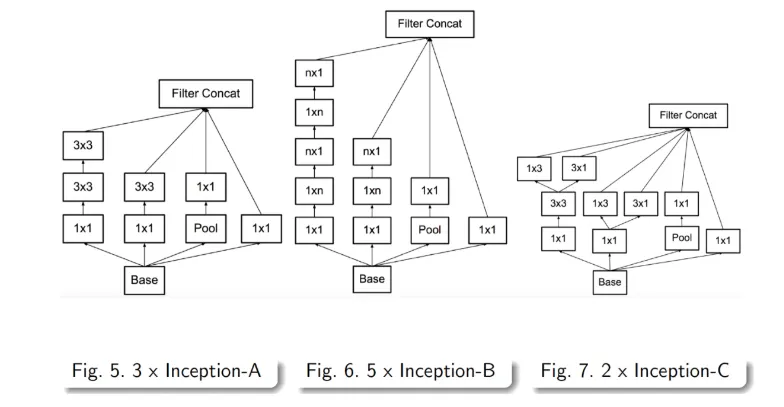
중간 아래에는 figure 5, 6, 7 라고 표기되어 이것은 앞서 설명한 여러 기법들을 차례차레 적용한 것이다.
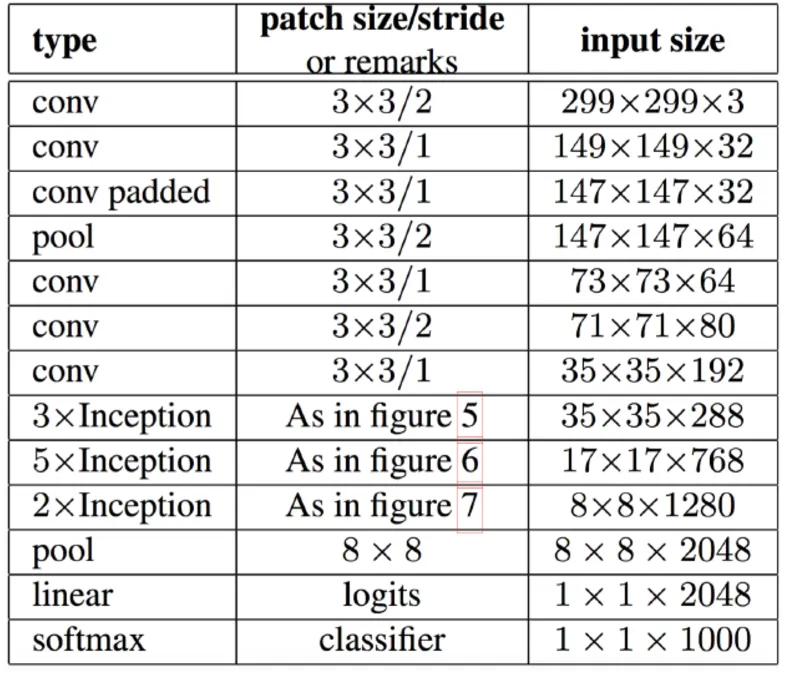
Inception V3
•
Inception.v3는 Inception.v2 를 만들고 나서 이를 이용해 이것 저것 수정해보다가 결과가 더 좋은 것들을 묶어 판올림한 것이다.
•
따라서 모델 구조는 바뀌지 않는다. 그래서 Inception.v2 그 구조도를 그대로 Inception.v3 라 생각해도 된다.
◦
RMSProp : Optimizer를 바꾼거다.
◦
Label Smoothing Target 값을 one-hot encoding을 사용하는 것이 아니라,값이 0 인 레이블에 대해서도 아주 작은 값 e 를 배분하고 정답은 대충 로 값을 반영하는 것이다.
◦
Factorized 7-7 맨 앞단 conv 7x7 레이어를 (3x3)-(3x3) 2 레이어로 Factorization 한 것이라고 한다.
◦
BN-auxiliary마지막 Fully Conntected 레이어에 Batch Normalization(BN)을 적용한다.