Introduction
최근 연구들의 주된 연구들의 네트워크에서 중요한 요소들은 : depth, width, cardinality(group conv)
( 2018년임을 주의 )
2018년임을 주의 )
2018년임을 주의 )LeNet의 Residual style Network→ 더 깊고 풍부한 representation
VGGNet : 같은 shape의 블록 쌓기 → fair results
ResNet : skip connection을 통해 같은 thopology의 residual blocks를 쌓음
GoogleNet : width 또한 모델의 성능향상에 중요한 요소임을 보여줌
[6]에서는 ResNet에서 width를 증가시키고, 28 레이어에 width를 증가시킨 모델이 1001레이어의 ResNet보다 뛰어남을 보여줌
Xception, ResNeXt : cardinality 증가 →파라미터의 증가 없이 다른 두 요소 ( width , depth )보다 stronger representation을 보여줌
우리는 다른 방면으로 접근 : attention
attention : 어디에 집중해야하느냐를 알려줄 뿐 아니라 representation of interests를 향상시킴
따라서 new network module CBAM을 소개
convolution 연산 은 cross-channel과 공간 정보를 함께 혼합하여 유익한 feature을 추출하기 때문에, channel과 spatial axes라는 두 가지 주요 차원에서 의미 있는 feature을 강조하기 위해 모듈을 채택합니다.
무시할만한 작은 연산량으로 채널 / 공간에 대한 attention map을 생성해 input featuremap에 곱함으로써 모델이 어디에 집중해야하는지 정보를 제공해준다!
Related Works
...
Convolutional Block Attention Module
전체적 플로우를 간단히 그림으로 나타내면 다음과 같다

간단히 식으로 나타내면

: element-wise multiplication
multiplication 동안에는 attention values are bradcasted(copied) : 즉 Cx1x1의 channel attention 을 input featuremap에 곱해주기 위해 CxHxW로 값을 복사해준다는 뜻. 각 채널은 모두 같은 값을 갖고 있을 것이다
(1xHxW의 spatial attention의 경우에도 마찬가지. 이 때는 채널방향으로 복사해줄 것이다)
Channel Attention Module
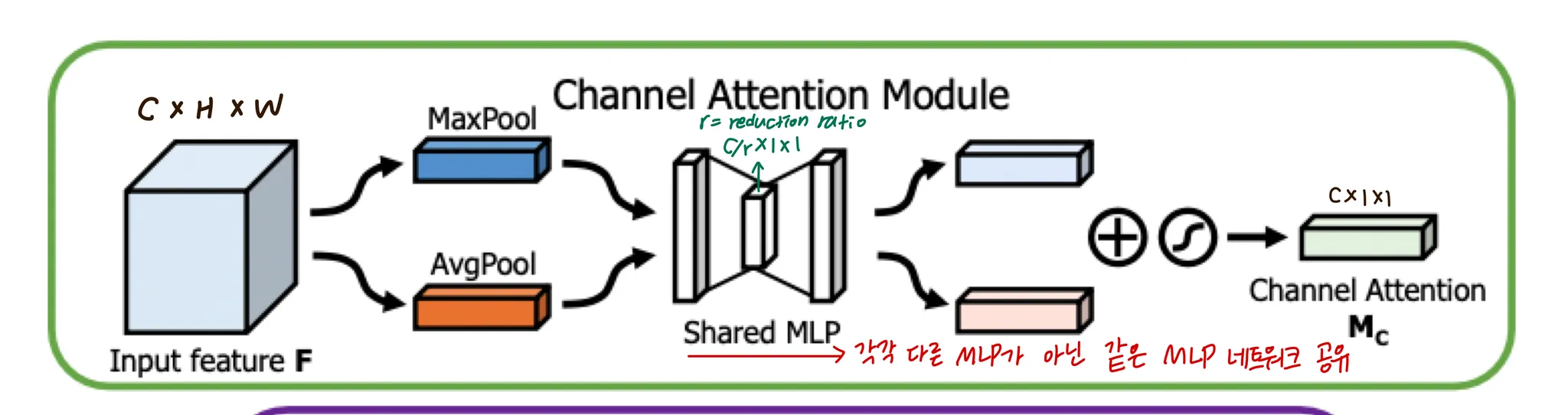

average pooling과 maxpooling으로 두개의 다른 spatial context description 를 뽑아내고, 각각 공유되는 하나의 MLP를 거친다음 더해진 후 sigmoid function을 거쳐 channel attention 가 된다
는 element-wise summation 이다
MLP의 hidden layer는 1개로,
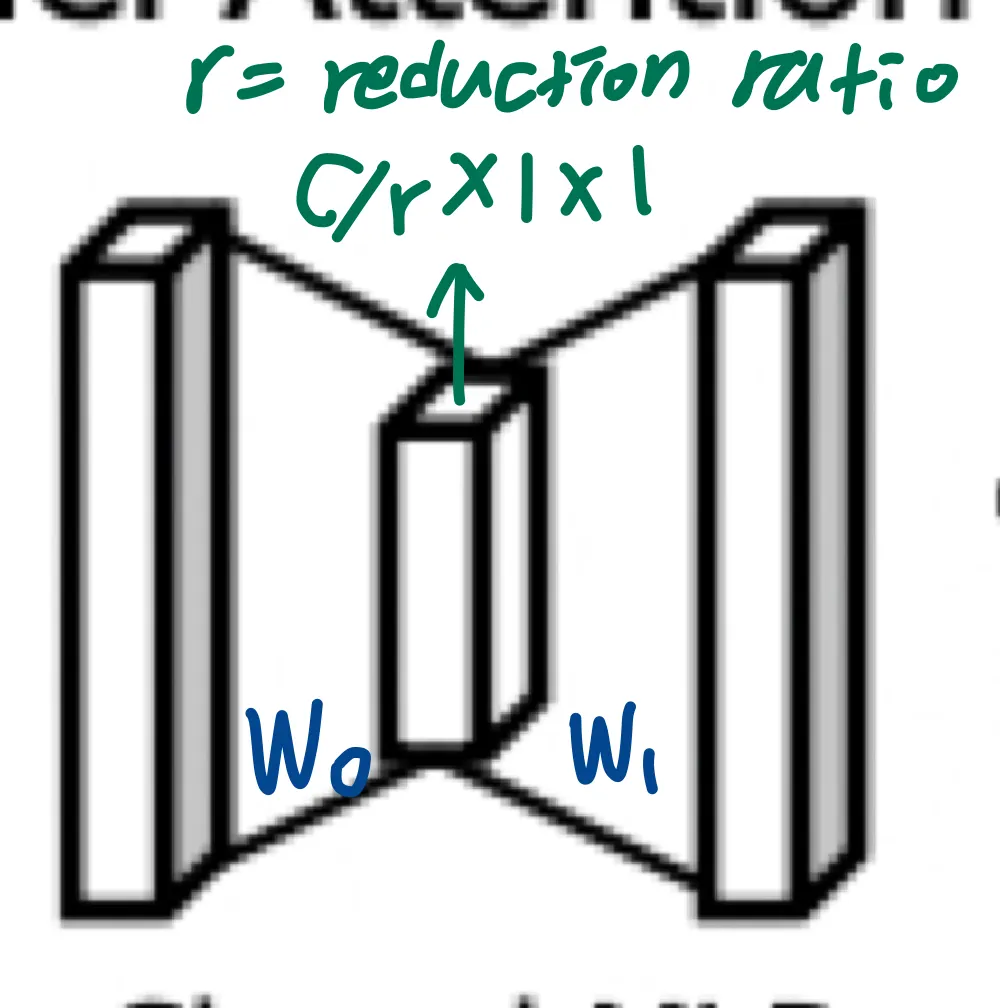
이후에는 ReLU activation이 있다.
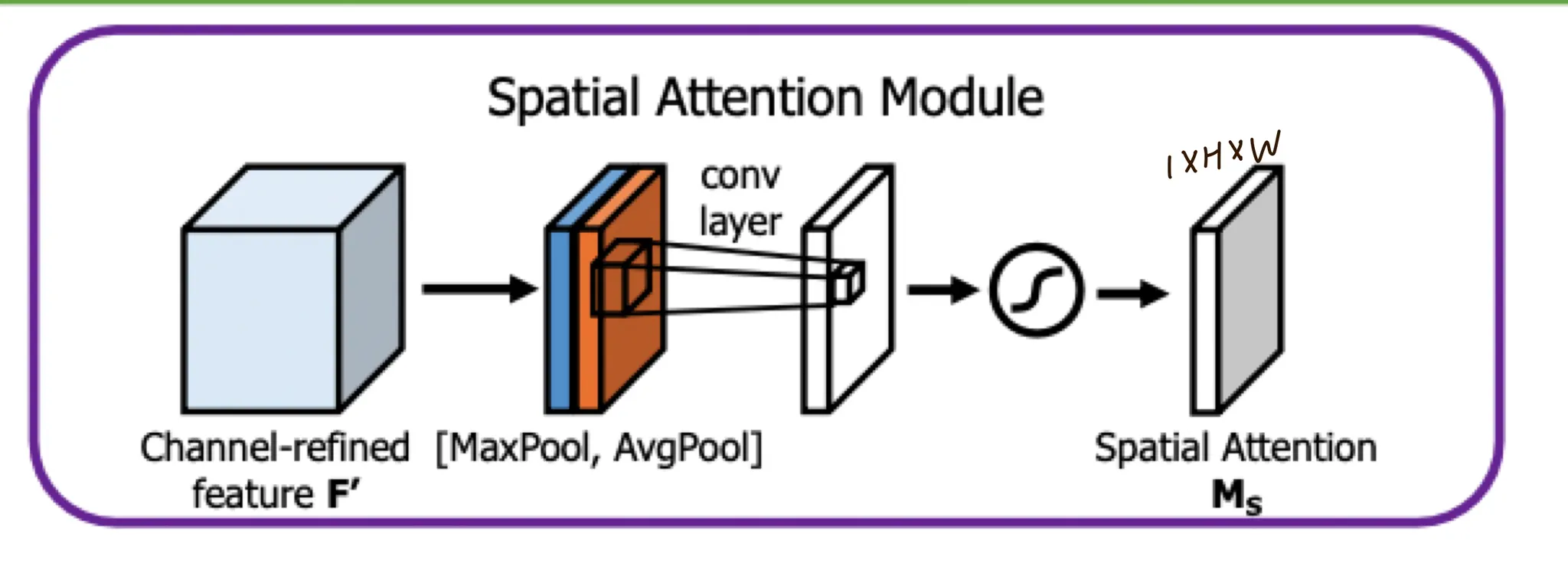
Spatial Attention Module
피쳐간의 inter-spatial relationship을 통해 spatial attention map을 생성한다
이를 위해 채널방향으로 average pooling / max pooling을 진행하고 (채널방향) concatenate한다
여기에 7x7 conv연산으로 spatial attention map을 생성한다
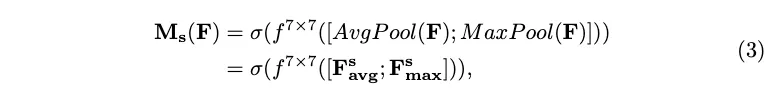
ResBlock에 이를 적용한 그림은 다음과 같다
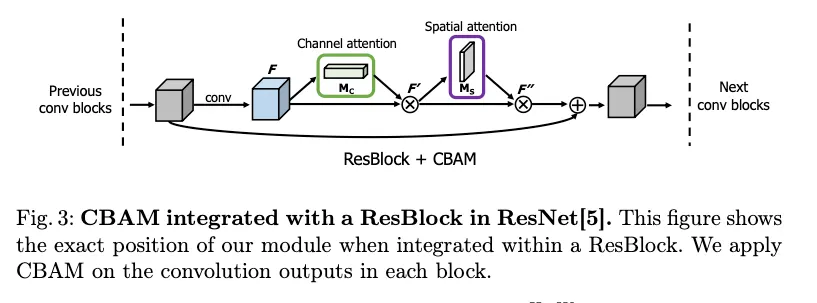
convolution을 거친 피쳐맵에 CBAM을 적용하고, shortcut을 더한다
