Abstract
dynamic scene deblurring에서 딥러닝 알고리즘은 많은 발전이 있었으나 여전히 여러 challenges가 존재한다
1.
blur의 다른 영역들에서의 degree와 scale이 큰 범위에서 꽤 다양성을 갖는다 ( 모든 영역에서 블러의 특성이 다르다 )
그러나 전통적인 input pyramid와 downscaling-upscaling은 한정되고 유연하지 않은 perceptual variouness를 갖도록 디자인됐다.
2.
nonlocal block은 image enhancement task에서 효과적임이 증명됐지만 큰 computation and memory cost가 든다.
따라서 light-weight globally analyzing module 을 제안하며 이름을 Light Global Context Refinement ( LGCR ) 로 한다. 매우 낮은 cost로 더 나은 performance를 보여준다
더해서, Perceptual Variousness Block (PVB)와 PVB pilling strategy를 제안한다.
PVB strategy : PVB를 반복해서 사용함으로 전체 방법이 풍부한 reception field spectrum을 갖게 다양한 degree와 scale의 블러를 알 수 있도록 한다
다양한 벤치마크에서의 포괄적인 실험결과와 assesment metrics는 이 방식이 좋은 성능을 달성했고 새로운 SOTA 를 달성했음을 보여준다.
Introduction
dinamic scene의 blur input에 대한 latent sharp image의 복원은 컴퓨터비전에서 오랫동안 중요한 task였다
하나의 이미지에 대한 딥러닝방식은 주목할만한 성공이 있었다.
1.
Nah et al. [20] : 3 scale에서의 input pyramid 사용해 coarse-to-fine 으로 복원
2.
Tao et al. [30] : convLSTM을 적용해 multi scale, weight sharing방식으로 coarse-to-fine 방식 제안
3.
최근 SOTA 방식들도 deblurring task에서 CNN의 가능성을 보여줌
가장 큰 어려운 점은 blur pattern의 degree와 scale이 넓은 범위에서 매우 다르다는 것이다. : 이 논문이 중점적으로 생각한 점
더 최근의 방식들은 다른 handcrafted strategies에 집중해 넓은 범위의 blur scale 다양성에 대응했다 .
[25]( SRN-Deblur ) : weight sharing을 활용한 recurrent network
[34] (CVPR 2019): multi patch 방식으로 multi scale information 을 추출
[22] (ECCV 2020): multi temporal idea로 이미지를 hard to easy로 점진적 복원
multi scale, multi patch, multi temporal 방식 : 모델의 perceptual scale variousness를 오직 limited times로 증가시킨다.
e.g. 오직 두개의 스케일 혹은 5가지 temporal intervals 만이 고려된다
다시 말해서, information flow에서 얻어진 마지막 reception fields는 오직 한정된 횟수로 augment된다.
하지만 blur의 degree는 상대적으로 넓은 범위로 상당한 variation 을 갖는다.
그러므로 이것들은 불연속적이고 수작업적인 전략이며, 넓게 분포된 복잡한 blur pattern을 충분히 인지할 능력이 있는 CNN에 만족스럽지 않다. ( CNN의 잠재적인 능력을 충분히 발휘하지 못하게 함 )
그리고 lower cost의 non-localized neural operation은 deblurring에서 중요하게 요구된다.
CNN 디자인은 localized filtering 연산에 기반하였으나 한번에 하나의 local neighborhood를 처리한다. 이는 넓은 범위를 고려하거나 전체 이미지를 self reference해야하는 image segmentation이나 pose estimation, severe motion blur 복원에는 적합하지 않다.
[28] 에서 제안된 nonlocal 은 완벽하고 클래식하지만 expensive solution.
최근에는 tensor canonical-polyadic decomposition theory에 영감을 받아 Chen et al.[2] 는 tensor generation module과 tensor reconstruction module ( TGM + TRM - T+T) 를 제안했다
TGM + TRM ( T + T ): global information 을 계산하면서 high-rank difficulty를 tackling. 하지만 이는 high-level semantic reasoning에 좋지만 detail recovery에는 좋지 않다. 그리고 1-rank tensor의 non-linearity는 충분하지 않다. 즉, 1rank tensors의 global context는 잘 학습되고 활용되지 않는다
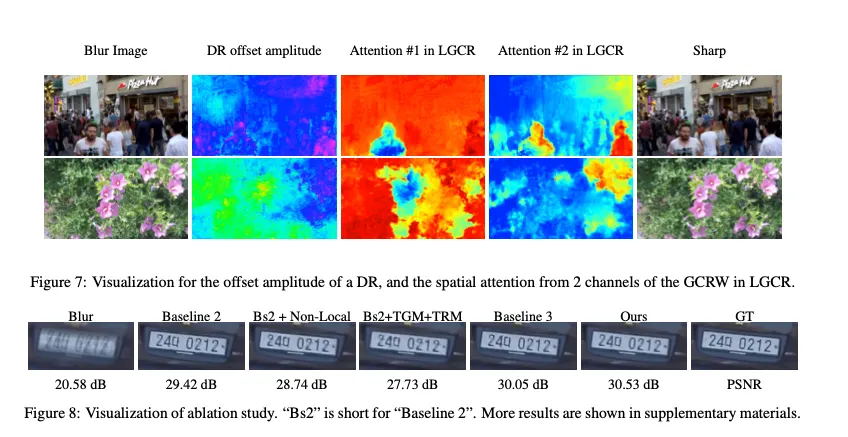
T+T
이 논문에서, 우리는 위에 언급된 부족함들을 연구했다. 그리고 SimpleNet이라는 방법을 제안했다.
•
Light Global Context refinement ( LGCR ) : light-weight non localized module
: pixel wise reasoning 대신 global detail을 풍부하게 하기 위함, nonlocal module보다 적은 cost가 듬. Nonlocal 과 T+T 보다 더 나은 성능을 보여줌 ( detail enhancement에서 )
•
Perceptual Variousness Block ( PVB ) : 넓은 reception spectrum 으로 풍부한 adaptive multi-scale reception ability 제공. 전통적인 “ multi “ methodology와 다름
•
단순한 encoder-decoder 구조로 robust하고 effective한 deblur network
•
Go-Pro, RealBlur-J, RWBI benchmark에서 실험
Related Work
method

Light Global Context Refinement (LGCR)
어렵거나 large scale인 blur pattern → long range dependencies가 중요
 detail enrichment 를 위해 설계되었다. ( T+T는 semantic pixel reasoning 을 위해 설계 )
detail enrichment 를 위해 설계되었다. ( T+T는 semantic pixel reasoning 을 위해 설계 )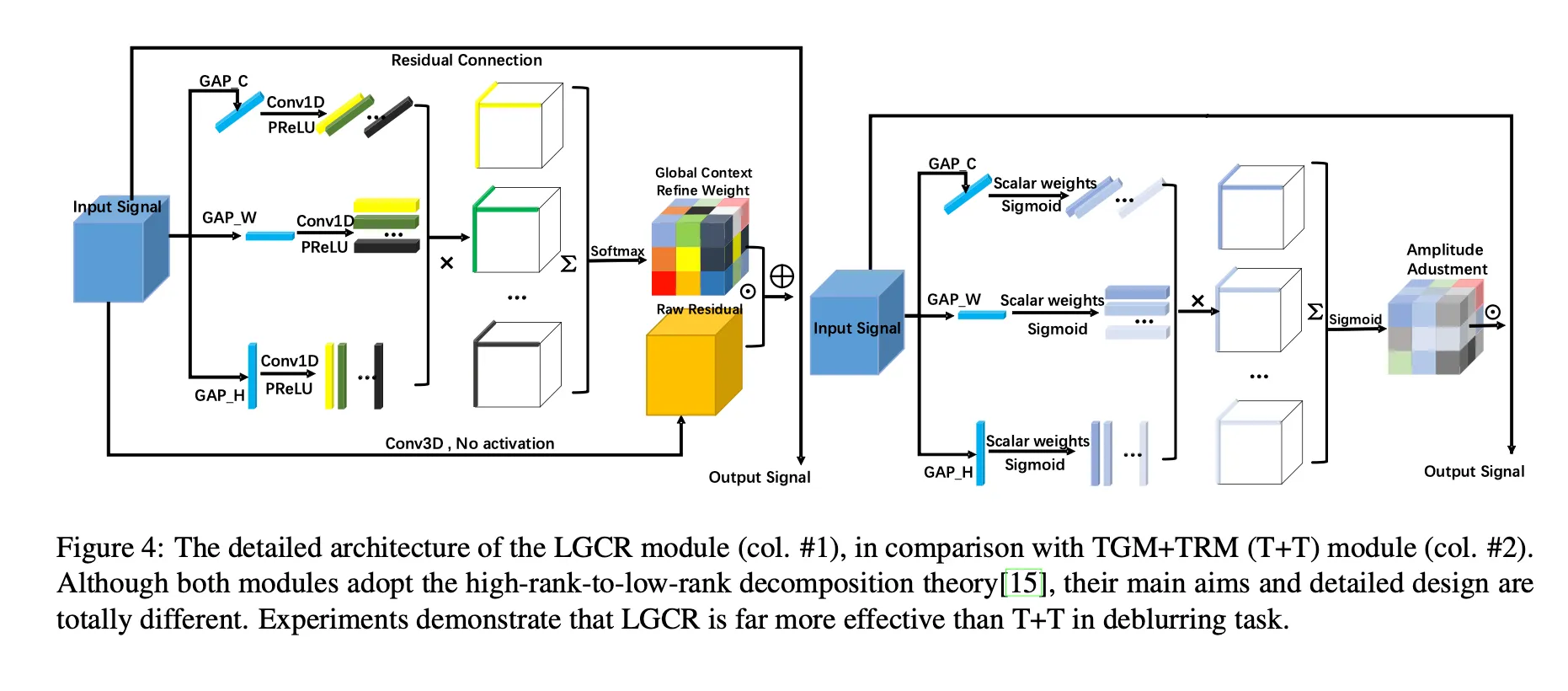
tensor decomposition theory를 따라., tensor는 그것의 low-rank principal components의 linear combination으로 표현될 수 있다.
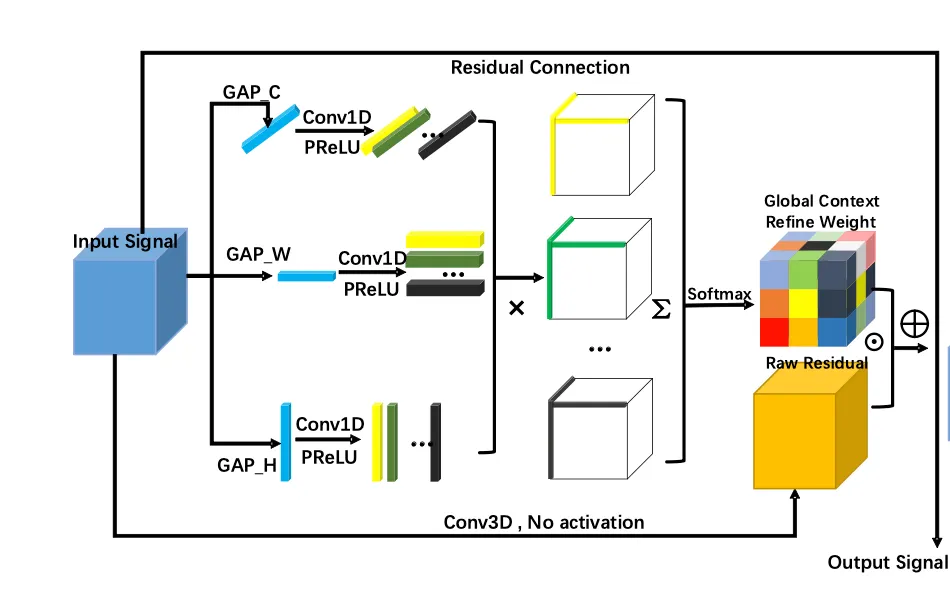
LGCR
input tensor
CP tensor reconstruction rank ( 더해지는 외적들의 수 )
axes based pooled vectors → 이 세 벡터를 기반으로 Conv1D를 통해 r개의 벡터를 만들어낸다.
이렇게 해서 만들어진 r개의 조합들의 외적을 더해 softmax를 거쳐 global context refine weight()가 구해지고
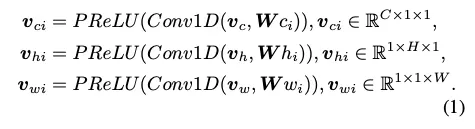
Conv1D의 kernel size는 1x3이다

이를 input signal에 conv3D를 거친 Raw Residual 에 곱해주게 된다. 마지막에 input signal을 더해주는 residual connection도 주어진다.
conv3D의 kernel size는 3x3x3이다.


LGCR | T+T | |
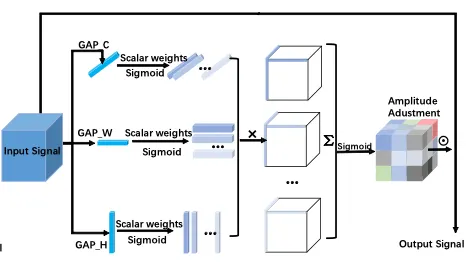
목적 | enrich feature details. input에 detail을 더함 | perform pixel semantic reasoning. global amplitude adjustment weight를 input에 곱해 positive semantic pixels를 tune-up하고 negative ones는 suppress |
detail | Raw Residual을 사용해 GAP로 잃는 정보를 보완할 수 있다 | GAP로 인한 정보 손실을 무시한다 |
conv 사용 | (1x3) 커널의 Conv1D를 사용한다. 따라서 LGCR의 context fragments의 non linearity가 T+T의 것보다 더 낫고, 이는 reconstructed high-rank tensor’s representation ability에 필수적이다
( 실험적으로도 성능이 좋음을 보여줌 ) | 3xr 개의 스칼라값을 곱한다 |
Perceptual Variousness Block ( PVB )

blur pattern의 매우 다양한 degrees와 scales에 대응하기 위한 모듈이다
앞에서도 반복하듯 기존의 multi scale 방식의 fixed & inflexible함과 제한된 횟수로만 augment됨을 해결한다.
모든 scale에서 PVB 모듈을 적용하는 PVB piiling strategy도 소개한다
SimpleNet은 네트워크의 reception scales와 perceptual ability의 다양성을 매우 풍부하게 한다
dilation 1, 2, 3의 3x3 conv layer와 하나의 3x3 Deformable conv를 병렬로 수행해 concat하고

이를 3x3 Deformable conv layer에 통과시켜 fuse 시킨다.

마지막엔 residual connection
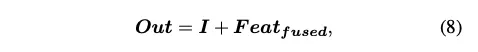
3개의 다른 고정된 reception field를 갖는 conv 레이어들은 PVB의 reception range의 다양성을 보장하고
Deformable conv는 learnable한 reception range를 제공해준다. → flexible reception supplement
그러므로 PVB의 perceptual range는 커지고 flexible해지며 합리적으로 풍부하다
⇒ large distribution scales의 다양한 blur patterns에 적응하고 인식할 수 있다
이를 여러번 적용하면 ( PVB pilling strategy ) diversity of network’s reception scales and perceptual ability를 매우 넓게 할 수 있고 이는 deblurring에 매우 유리하다!
Deformable ResBlock ( DR )


degree of the blur pattern → considerable variation
특정 패턴을 복원하기 위해 필요한 pixels는 어떠한 distorted spatial distribution으로 irregulary하게 위치해 있다.
deformable convolution이 flexible한 spatial sampling point를 가지고 있고, 네트워크가 학습할 수 있다.
이 모듛은 irregularly distributed blur patterns를 포착하고 네트워크가 인식한 perception scales도 풍부하게 한다.
따라서 DR을 모든 decoder의 PVB 뒤에 넣었다.
SimpleNet
아키텍쳐는 간단한 auto-encoder의 형태에 기반했으며 6개의 ResBlocks, 6개의 PVBs, 3개의 DRs, 하나의 LGCR이 존재한다
이 블록들은 residual 방식에 기반했다
Optimization and implementation
loss : L1 Loss
ADAM Optimizer ( )
batch size : 8
learning rate : 1e-4, 630k iterations마다 decay. decay rate는
total 2200k iterations
CP Tensor decomposition rank r = 64
GoPro benchmark로 training
Experiments
Ubuntu 16.04
Intel i7-7700k, 32GB RAM , GTX 1080 Ti
PSNR / SSIM 은 MATLAB R 2019 b으 ㅣ함수로 계산