이 논문은 어떠한 복원 모델이나 학습 방식에 대한 논문이 아니라 inference에서의 하나의 스킬을 제안하는 논문이다.
Abstract
이미지 복원 태스크에서 보편적으로 GPU memory의 문제로 training은 전체 이미지에서 crop한 patch이미지로, test에서는 전체 이미지로 진행하기 때문에 global operation (e.g. Global average pooling)의 동작이 training시와 inference시에 다르고, 그로 인해 복원 성능이 감소한다는 것이 이 논문이 지적하는 문제점이다.
⇒ train-test inconsistency
이를 줄여서 test-time performance를 향상시키기 위해 Test-time Local Converter ( TLC )라는 단순한 방법을 제안한다. TLC는 inference 시에 global operations를 local의 것으로 전환한다 그로 인해 TLC는 전체 이미지가 아닌 local 영역 내의 features를 aggregate할 수 있다.
이 모듈은 다양한 global modules에 적용할 수 있고 연산량은 크게 늘어나지 않는다.
또한 어떠한 fine-tuning없이 다양한 state-of-the-art 방법들에 바로 적용이 가능하다.
Restomer이라는 모델에 이 방법을 적용했을 떄 GoPro dataset에서 PSNR 32.92 dB → 33.58 dB로 성능이 향상되었다.
Introduction
introduction에서는 여러 SOTA 복원 모델들을 소개하고 복원모델들은 보통 patch들로 학습하고 full-resolution images로 inference하며, 이는 train과 test 모두에서 resize하는 high-level vision tasks와는 다르다고 말한다. low-level vision task에서는 image의 detail 보존을 위해 resize는 기피되는 방식이다.
ex) MPRNet [ MPRNet(CVPR 2021) ]: (256, 256) size의 patch로 학습 → GoPro 데이터셋의 (720, 1280)크기의 야가 7%밖에 되지 않는다.
MPRNet(CVPR 2021) ]: (256, 256) size의 patch로 학습 → GoPro 데이터셋의 (720, 1280)크기의 야가 7%밖에 되지 않는다.
MPRNet(CVPR 2021) ]: (256, 256) size의 patch로 학습 → GoPro 데이터셋의 (720, 1280)크기의 야가 7%밖에 되지 않는다. 이 경우 모델이 오직 이미지의 local part만을 학습하게 되고 full-resolution image의 global clues를 인코딩하기에는 어려울 수 있다. → sub-optimal performance
따라서 이 논문에서는 global information aggregation 을 다시 살펴본다.
이들은 global average pooled features를 분석해 entire-image-based features가 patch-based features와 매우 다르다는 것을 찾아냈다. ( 아래 그래프)
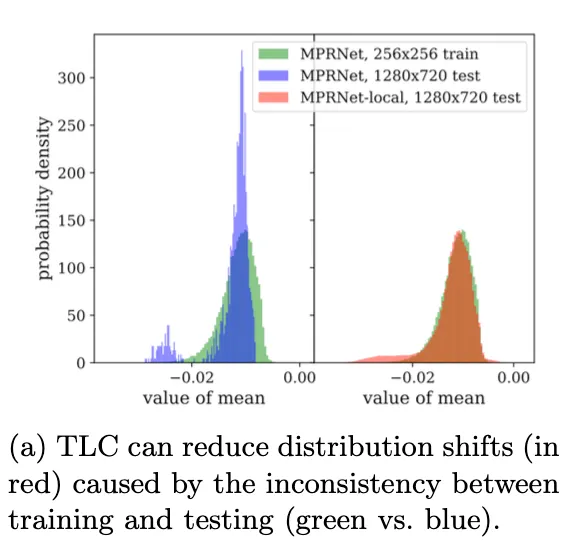
이와 같은 global information의 train시와 test 시의 shift는 모델의 성능에 안좋은 영향을 미친다.
이를 해결하기 위해 Test-Time Local Converter (TLC)를 제안한 것이고 이는 training과 inference 사이의 information aggregation의 차이를 메꿔준다.

TLC 는 single image motion deblurring에서 SOTA 모델들의 성능 향상을 이루었고 contributions는 다음과 같다
1.
training시 global information 에 대한 inconsistency가 복원모델에 안 좋은 영향을 미친다는 것을 지적한 첫 번째 논문이다.
2.
training 시와 inference 시의 분포 이동을 줄이기 위해 Test-time Local Converter (TLC)를 제안하며 이는 feature aggregation의 영역을 test time 시에 global 에서 local로 전환한다. retraining이나 fine-tuning없이 TLC는 다양한 모듈들의 성능을 향상시켰다.
3.
확장 실험으로 TLC는 다양한 state-of-the-art 결과를 향상시켰다.
Analysis and Approach
여기서는 이미지 복원 파이프라인과 그로 인해 발생하는 train-test inconsistency of global information aggregatoin을 분석하고 TLC에 대해 설명한다.
Image Restoration Pipeline
앞에서 계속 설명한 train-test inconsistencies에 대한 이야기이다.
Train-Test Inconsistency of Global Informatio Aggregation
convolution과 같은 local operation과 달리 global operations는 모든 spatia dimensions를 연산하고 그 결과로 global operation은 임의의 입력 해상도에서 global receptive fields를 가지게 된다.
즉 global operation의 receptive field의 범위는 입력 피쳐의 크기로 제한되기 때문에 training과 inference 에서의 다른 동작이 생기게 되는 것이다. → 원본 이미지로부터 크롭된 다양한 영역 / full-resolution images
이 불일치가 모델의 일반화 성능에 영향을 주게 된다. 학습시에 모델은 patch-based features에 의해 최적화되기 때문이다. test시에 레이어는 entire-image-features에서 결과를 inference하기 때문에 이 때의 global information aggregation의 동작을 qualitatively and statistically 분석했다.
Statistical Analysis
MPRNet을 기반으로 분석되었다.
patch 기반일 때와 full-resolution images일 때의 mean statistics를 비교했다.
MPRNet의 두번째 encoder의 첫번째 SE layer에 의해 mean statistics가 집계된 것을 나타낸 것이다.
Fig. 3 (a)의 왼쪽에서 training(green)에서 inference(blue)로 shift했다
복원모델들이 information distribution 의 심한 변화에 적용되는 것은 어렵다. 성능이 저하된다.
Qualitative Analysis
training시와 동일하게 이미지를 패치로 자르고 inference하는 중에 결과를 뽑아내면 Fig. 3 (b)와 같이 불일치 문제가 완화된다.

Fig. 3 (a)
Fig2로 시각적으로 비교했다.

•
(b) : 전체 이미지로 inference : 제대로 복원하지 못함
•
(c) : 패치로 복원하고 붙임 : 좀 더 잘 복원이 되었으나 자른 패치의 경계에 artifacts
•
(d) : TLC 적용 → 복원이 더 잘 됨
Test-time local converter
학습 방식을 바꾸거나 이미지를 crop하는 대신에 TLC는 inference 동안에 feature level에서 information aggregation의 region의 범위를 바꾼다.
Fig. 1 (b)처럼 spatial information aggregation연산을 global에서 local로 바꾼다. 자세하게 말하면 global operation의 input feature 는 크기의 overlapping window로 잘린다. 그리고 information aggregation operation은 각각 overlapping window에 대해 개별적으로 수행된다. 그 결과로 statistics distribution shifts는 TLC에 의해 Fig. 3 (a)와 같이 감소된다.

Efficient Implementation of Information Aggregation
feature layer 의 global information aggregation 은 다음과 같이 공식화될 수 있다. 또한 channel dimension을 고려하지 않았기에 generality를 잃지 않는다.
: how information are calculated
: aggregated information
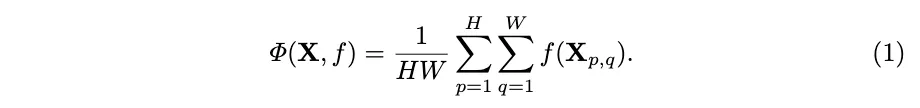
→ complexity
local information aggregation에 대해 각 픽셀은 local window에 대해서 정보를 집계하기 때문에 이는 다음과 같이 공식화 된다
: aggregated local information
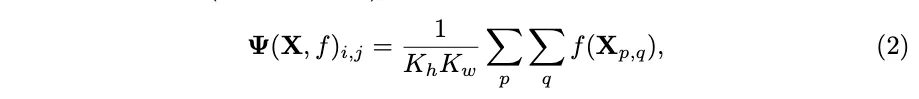
이는 two step으로 적용됐다.
edge case : 가 의 boundary인 경우1.
windows ( size of ) with stride 1을 슬라이딩하여 non-edge case인 각 pixel에 대해 local information을 집계한다.
→ complexity
2.
edge case에 대해 결과의 boundary를 replication으로 padding한다 → complexity \mathcal{O}
→ mean / sum aggregation within local window는 submatrix sum problem으로 간주되어 prefix sum trick으로 이다. 결과적으로 전체 complexity는 로 감소된다. 이는 global information aggregatoin과 같은 복잡도이다. 그래서 TLC는 추가적인 computational bottleneck을 유발하지 않는다.
Extending TLC to Existing Modules
TLC를 기존 모듈에 확장시키기 위해서는 information aggregation 연산을 global에서 local로 바꿔줘야한다.
Squeeze-and-Excitation module과 Instance Normalization 연산을 예시로 들었으나 다른 normalization 모듈들에도 쉽게 적용될 수 있다.
Extending TLC to SE Block

다른점은 기존 SE와 달리 element-wise attention으로 적용된다.
Extending TLC to IN

결과적으로 각 픽셀은 neighbothood에서 normalized된다.
Extending TLC to transposed self-attention
Restormer로 실험 진행했기 때문에 TLC를 transposed self-attention에 적용했다.
그러나 inefficiency와 GPU memory 제한 때문에 TLC in transposed self-attention에서는 1보다 큰 stride를 사용했다.
자세히 보면 transposed self-attention은 overlapping overlapping windows 각각에 독립적으로 적용하고 overlapping된 결과들은 spatial dimension으로 concatenate하면서 겹치는 부분은 averaging했다.
Experiment
TLC를 사용해 향상된 성능을 볼 수 있다.
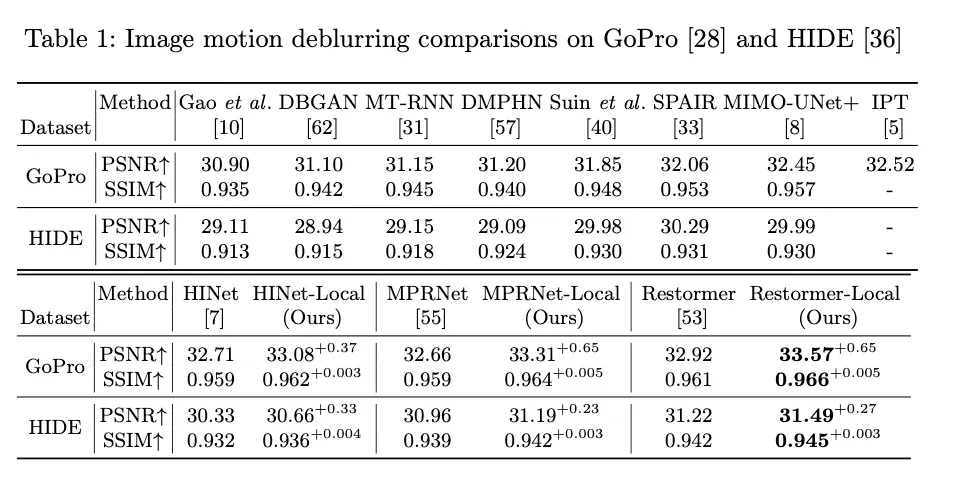
이외 deblurring, denoising, dehazing에서의 높은 성능을 보여주었다,.
