
Abstract
DeblurGAN-v2라는 single image motion deblur를 위한 새로운 end-to-end GAN을 제시하며, 이는 최첨단 디블러링 효율성, 품 및 유연성을 상당히 향상시킵니다.
DeblurGAN- v2는 double-scale discriminator가 있는 relativistic conditional GAN을 기반으로 한다.
처음으로, 우리는 DeblurGAN-v2 Generator의 핵심 빌딩 블록으로 Feature pyramid network(FPN)을 deblurring에 도입했습니다.
그것은 성능과 효율성 사이의 균형을 탐색하기 위해 다양한 백본으로 유연하게 작동할 수 있다.
sophisticated 백본(예: Inception-ResNet-v2)의 플러그인은 최첨단 디블러링으로 이어질 수 있다.
한편, 가벼운 백본(예: MobileNet 및 그 변형 )을 통해 DeblurGAN-v2는 가장 가까운 경쟁사보다 10-100배 빠르게 도달하며, 최첨단 결과를 유지하면서 실시간 비디오 블러를 제거함을 의미한다.
우리는 DeblurGAN-v2가 deblurring 품질과 효율성 측면에서 여러 인기 있는 벤치마크에서 매우 경쟁력 있는 성과를 얻는다는 것을 보여줍니다. 게다가, 우리는 일반적인 이미지 복원 작업에도 효과적이라는 것을 보여준다.
Introduction
사람이 들고 찍는 카메라 / 움직이는 객체 찍은 low frame rate videos
real world blurs : unknown, spatially varying blur kernels, further complicated by noise or other artifacts
GAN의 여러 복원분야에서의 뛰어난 성능
v1성능 좋앗음
v2에서 deblurring 뛰어난 성능과 함께 효율적인 inference 에 집중
innovations
•
Framework Level
◦
새로운 cGAN framework

◦
generator로 FPN 적용 - 원래 detection에서 사용되던 것으로, image restoration에 적용한 것은 처음
FPN
◦
discriminator로는
▪
내부에 least-square loss가 적용된 relativistic discriminator
▪
global (image) 와 local(patch)를 모두 평가하는 두 열이 있는 relativistic discriminator
채택
•
Backbone Level
◦
위의 프레임워크는 Generator backbone에 구애받지 않지만, 선택은 deblurring quality과 효율성에 영향을 미칠 것이다.
◦
SOTA deblurring quality를 뒤쫓기 위해 정교한 Inception-ResNet-v2backbone을 적용해봤다
◦
더 효율적이기 위해 MobileNet을 적용하고 더 나아가 그것의 depth-wise separable convolutions로 ( MobileNet-DSC) 변형을 생성했다 → extremely compact in size, fast in inference
•
Experiment Level
◦
광범위한 실험 수행
◦
세개의 유명한 벤치마크로 SOTA performance보여줌. PSNR, SSIM, perceptual quality
◦
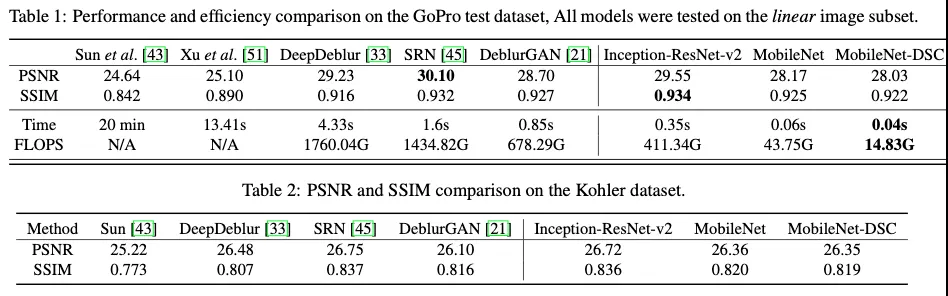
효율성면에서 MobileNet-DSC를 적용한 DeblurGANv2는 DeblurGAN보다 11배 빠르고 [33(DeepDeblur), 45(SRN_Deblur)]보다는 100배 빠르며 모델사이즈는 4MB밖에 되지 않는다. → 실시간 비디오 deblurring의 가능성을 보여준다
◦
우리는 또한 실제 흐릿한 이미지에 대한 deblurrng subjective 연구를 제시합니다.
◦
마지막으로, 우리는 extra flexibility로 일반적인 이미지 복원에서 모델의 잠재력을 보여줍니다.
Related work
2.1. Image Deblurring
2.2. GAN
latent code 뿐 아니라 observed image도 input으로 함께 받는 cGAN
D → fake 0, real 1
mode-collapse나 gradient vanishing/explosion때문에 최적화가 어려운 GAN 의 일반적인 Loss ( MinMaxLoss)
vanishing gradients를 고치고 학습을 안정화시키기 위해 Least Squares GANs discriminator가 smoother and non-saturating gradient를 제공하기 위한 loss를 제안했다.
⇒ log type loss는 빠르게 saturate한다 왜냐면 x와 decision boundary 사이의 거리를 고려하지 않기 때문이다. 대조적으로 L2 Loss는 그 distance에 대해 비례하는 gradient를 제공하므로 boundary에서 더 멀리 떨어진 fake samples는 더 큰 penalties를 받는다
제안된 loss function은 Pearson divergence 또한 최소화한다. 그리고 그것은 training stability를 더 낫게 한다.
LSGAN의 objective function
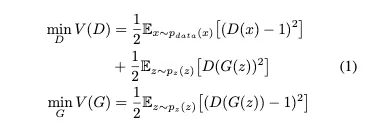
간단하게 LSGAN의 목적은 ( g가 근사하는 분포, data 분포의 합)와 사이의 Pearson divergence를 최소화 하는 것. 궁극적으로는 기존의 GAN의 방향과 동일하다
GAN의 또 다른 관련 발전은 Relativistic GAN
relativistic discriminator는 주어진 real data가 얼마나 randomly sampled fake data보다 realistic한지 확률을 측정
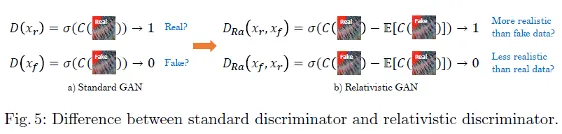
mini batch에 포함된 데이터의 절반이 fake라는 priori knowledge를 설명할 수 있음
relativistic discriminators는 DeblurGAN v1에 쓰였던 WGAN-GP를 포함한 다른 GAN과 비교해 학습에 있어 더 안정적이고 계산적으로도 효율적이라는 것을 보여준다.
3. DeblurGAN-v2-architecture
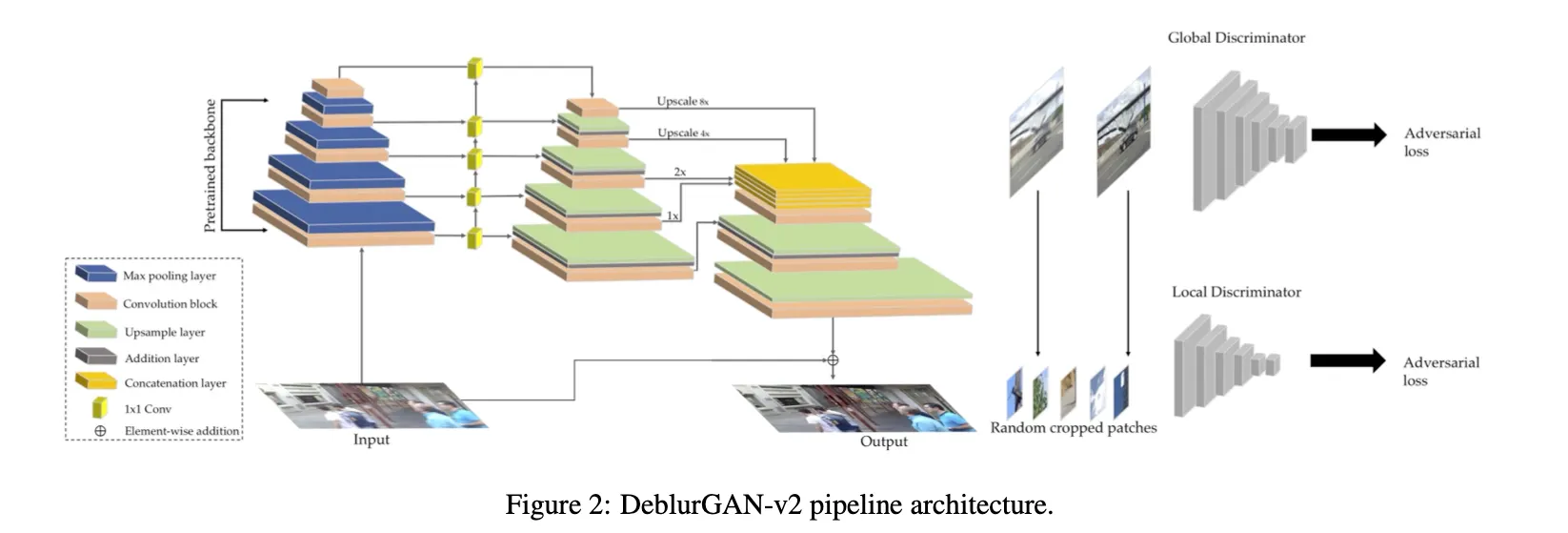

(blurred image) → G → ( sharp iimage )
3.1. Feature Pyramid Deblurring
deblurring 혹은 다른 task들을 위한 CNN들은 대부분 ResNet-like 구조
대부분의 SOTA 방법들은 다른 level의 blurs를 다루고, 다른 scale의 input image pyramid 로 multi-stream CNNs를 이용했다
이는 시간과 메모리가 많이 필요함
FPN을 image deblurring(더 일반적으로는 restoration, enhancement)에 사용하는 아이디어를 소개하며, 처음 시도로 알고있다
이 새로운 접근을 여러 scale의 features를 결합하기위한 lighter weight alternative 로 다룬다
FPN은 원래 detection을 위해 디자인됐다
여러개의 피쳐맵레이어를 생성한다. 다른 semantics를 encode하고 더 좋은 퀄리티의 정보를 포함한.

FPN

우리의 아키텍쳐는 FPN 백본을 포함한다. 다른 스케일의 5개의 마지막 피쳐맵을 그로부터 가져온다
그 피쳐들은 나중에 1/4 input size로 업샘플되고 다른 levels에서 semantic information을 포함한 하나의 텐서로 합쳐진다(concatenated)
우리는 추가적으로 두개의 업샘플링 그리고 conv 레이어들을 추가한다 네트워크 끝에→ 원래 사이즈로 복원하고 artifacts를 줄이기 위해
input에서 output으로의 direct skip connection도 적용해 학습이 residue에 집중할 수 있도록 함
input image들은 [-1 1]로 normalize된다.
또한 tanh activation layer를 통해 output도 같은 range로 보존한다.
multi-scale feature aggregation 기능 외에도, FPN은 정확도와 속도 사이의 균형을 맞춥니다: 실험 부분을 참조하십시오.
3.2. Choice of Backbones : Trade-off between Performance and Efficiency
new FPN-embeded architecture은 feature extractor 백본 선택에 관대하다
default로 ImageNet-pretrained backbones를 사용해 더 semantic-related features를 뽑아냈다
하나의 옵션으로 Inception-ResNet-v2를 사용했다
또한 SE-ResNeXt같은 백본들도 비슷하게 효과적이었다
효율적인 복원 모델의 요구는 최근 모바일 온디바이스 이미지 향상의 일반적인 필요성으로 인해 점점 더 많은 관심을 끌었다.
이 방향의 예로 삼기위해 MobileNet v2 백본을 하나의 옵션으로 선택
depthwise separable conv로 전체네트워크를 대체해 시도했고 이는 MobileNet-DSC로 표시. 매우 가볍고 효율적인 image deblurring
3.3. Double-Scale RaGAN-LS Discriminator
LSGAN의 cost function에 relativistic “wrapping”을 적용해 새로운 RaGAN-LS loss를 적용했다
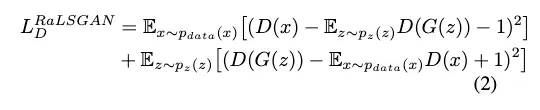
G에 대해 이 식을 최적화시키는 방향으로 학습된다
WGAN-GP objective를 사용하는 것보다 학습을 특히 더 빠르고 더 안정적이게 만들었다.
경험적으로 생성된 결과가 더 높은 perceptual quality를 포함하며 전체적으로 더 sharp한 output을 만들어낸다고 결론지었다
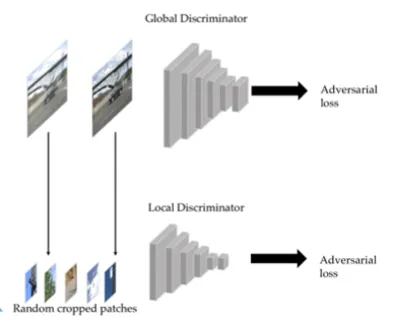
Extending to Both Global and Local Scales
70x70크기의 patch를 다루는 PatchGAN은 더 sharper한 result를 생성한다는 것을 증명했다(full image를 보는 discriminator보다)
parchGAN 아이디어는 DeblurGAN에 적용되었었다
그러나 우리는 매우 non-uniform blurred된 이미지에는 특히 복잡한 객체의 움직임이 포함됐을 경우에는 “global” scales가 여전히 필수다라는 것을 알았다
global and local features모두를 사용하기위해 double-scale discriminator를 제안한다
하나의 local branch( 패치 레벨을 다룸 )과 또 다른 global branch( full input image를 받는 )로 이뤄져있다
Overall Loss Function
이미지 복원 GAN을 학습시키기 위해, training단계에서 어떠한 metric으로 복원된이미지와 원래 이미지를 비교해야 한다.
하나의 보통의 옵션은 pixel-space loss 이다. ( L1 distance혹은 L2 distance )
이것을 사용하는 것은 oversmoothened pixel space output을 야기하는 경향이 잇다.
perceptual distance를 “content” loss로 사용하는 것을 제안
L2에 비교하여 VGG19의 conv3_3 featuremap에서 유클리디안 loss를 계싼
우리는 이 prior wisdoms를 통합
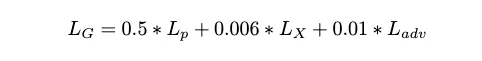
: global and local discriminator losses를 포함
: MSE loss - color와 texture 왜곡을 보정하는 것을 돕는다
좀 더 이해하기 위해 코드를 살펴봤다
train.py에서
self.criterionG, criterionD = get_loss(self.config['model'])
이렇게 loss를 가져오고,
저 get_loss함수는 return content_loss, disc_loss
논문대로라면
content_loss는 PerceptualLoss클래스로 정의되고,
이 클래스의 get_loss함수는 ( 클래스 함수 )
loss = fake와 real의 vgg19 conv3_3에서의 featuremap 출력끼리의 MSELoss()결과
return 0.006 * torch.mean(loss) + 0.5 * nn.MSELoss()(fake, real)
이후 train.py Trainer 클래스의 _run_epoch함수에서
loss_content = self.criterionG(outputs, targets)
loss_adv = self.adv_trainer.loss_g(outputs, targets)
loss_G = loss_content + self.adv_lambda * loss_adv
이렇게되면서 논문의 식과 같아진다
self.adv_trainer = self._get_adversarial_trainer(self.config['model']['d_name'], netD, criterionD)
double_gan이 default -> return GANFactory.create_model('DoubleGAN', net_d, criterion_d)
DoubleGAN의 loss_g함수는
return (self.criterion.get_g_loss(self.patch_d, pred, gt) + self.full_criterion.get_g_loss(self.full_d, pred,gt)) / 2
RelativisticDiscLoss에서 get_g_loss는
errG = (torch.mean((self.pred_real - torch.mean(self.fake_pool.query()) + 1) ** 2) +
torch.mean((self.pred_fake - torch.mean(self.real_pool.query()) - 1) ** 2)) / 2
return errG
로 real과 fake의 Least Square error를 반환한다.
loss_G는 이렇게 논문의 식과 같아진다!
disc_loss는 논문대로라면 RelativisticDiscLossLS() 클래스로 정의되어야한다
이후 Trainer 클래스 _update_d 함수에서
loss_D = self.adv_lambda * self.adv_trainer.loss_d(outputs, targets)
DoubleGAN의 loss_d함수는
return (self.criterion(self.patch_d, pred, gt) + self.full_criterion(self.full_d, pred, gt)) / 2
patch_d로 정의된 patch discriminatorsms RelativisticDiscLossLS로 들어가 patch_d의 예측을 기반으로
self.loss_D = (torch.mean((self.pred_real - torch.mean(self.fake_pool.query()) - 1) ** 2) +
torch.mean((self.pred_fake - torch.mean(self.real_pool.query()) + 1) ** 2)) / 2
return self.loss_D
이렇게 patch D에서의 least square error
그리고 full discriminator도
self.full_criterion = copy.deepcopy(criterion)
이기 때문에 같은 값이지만 full image를 보는 full D에서의 예측값을 기반으로 계산한 값을 반환한다.
그래서 결국에
loss_D는 adv_lambda라는 작은 값 (default 0.001)이 곱해진 patchD와 fullD의 LS loss값의 합을 return하게되며
이는 논문의 설명과 같다
Python
복사
3.4. Training Datasets

4. Experimental evaluation
4.1. Implementation Details
•
Tesla-P100
•
150epoch lr 10e-4, 그 후 150epoch 동안은 lr이 linear하게 10e-7까지 줄어듬
•
3epoch동안 backbone freeze 후에 모든 weight unfreeze해서 다시 training
•
unpretrained 부분은 random gaussian 으로 초기화
•
수렴까지 5일걸림
•
모델은 모두 convolutional이라서 사이즈가 다른 이미지에 적용가능합니다

Subjective Evaluation on Lai Dataset
Lai dataset은 서로 다른 퀄리티와 해상도의 현실세계의 블러된 이미지들이 모여있어서 이 real images는 clean/sharp 부분이 없다. 따라서 full-reference quantitiv evaluation 이 불가능하다.
실제 이미지들에서 성능을 비교하기 위해 다음 subjective survey를 수행했다.
점수를 매기기 위해 Bradly-Terry model을 적용했다고 한다





