Google DeepMind의 논문이며 DALL-E에 사용되었다고 유명한 논문이다.
Abstract
supervision 없이 유용한 representation을 학습하는 것은 머신러닝에서 매우 중요한 문제이고 이 논문에서는 심플하고 강력한 generative model이 discrete representation을 학습하도록 한다.
그래서 VQ(vector quantised) 라는 단어를 사용한 것이다.
VQ-VAE는 기존 VAE와 다음과 같은 점에서 차이가 있다.
1.
prior은 static하지 않고(정규분포 등으로 정의되지 않고) 학습된다.
2.
discrete latent representation을 학습하기 위해 vector quantisation (VQ)라는 아이디어를 사용한다.
이는 posterior collapse라는 VAE의 고질적 문제를 해결한다.
이렇게 학습된 representations를 autoregressive prior과 짝지어서 고퀄리티의 이미지/비디오/스피치 등을 생성할 수 있도록 한다.
Introduction
continuous한 latent representation이 AE 및 VAE에서 잘 사용되어 왔으나, 현실세계의 대부분의 데이터(이미지/오디오/언어 등)는 이산적인 형태이다.
따라서 latent representation은 연속적일 필요가 없다. 어떠한 수로 표현되기만 하면 된다.
이산적인 표현을 통해 데이터의 특정한 local 영역이나 noise에 집중하기보다는 feature만을 성공적으로 모델링할 수 있도록 한다.
그러나 이산적인 representation은 backpropagation이 되지 않아 딥러닝에 적합하지 않다고 여겨져 왔다.
이를 해결하기 위한 concrete softmax / gumbel softmax 등의 방식이 연구되었었다. VQ-VAE에서는 decoder의 gradient를 바로 전달하는 간단한 방식으로 이를 해결하였다.
VQ-VAE
VQ-VAE의 전체적인 flow는 다음과 같다

그림에서 보이듯 마치 auto encoder + codebook의 형태를 가진다
quantized vector
CNN encoder를 거져 나온 는 code book 내의 벡터들과 거리를 연산해 거리가 가장 가까운 벡터를 인덱싱을 통해 선택한다. 이는 식 (1), (2)와 같이 표현할 수 있다.


는 번째 code book vector이다.
argmin 연산은 미분 불가능한 연산이다. 그러나 decoder의 gradient를 바로 전달해 주는 것으로 backpropagation이 가능하도록 했다. 즉 argmin연산에서 선택된 벡터의 gradient는 1로, 선택되지 않은 벡터의 gradient는 0으로 적용한 것이다.
위와 같은 과정으로 만드렁진 quantized vector는 decoder의 input이 되어 decoder는 이를 기반으로 input을 복원하는 방식으로 학습된다.
이렇게 제한된 vector set이 어떻게 decoder로 들어가 엄청나게 많은 이미지의 다양한 특성을 복원할 수 있는 걸까?
이는 만약 인코더가 하나의 벡터만을 output 삼는다면 문제가되겠지만, 실제 VQ-VAE에서는 32x32 grid와 같은 일련의 벡터를 생성하기에 문제가 되지 않는다.
이미지의 경우 vector의 32x32 grid를 출력하는데, 만약 코드북 내에 10개의 vector가 있다면 의 경우의 수가 생긴다. ⇒ 일정한 코드북 내 벡터수를 가지고 엄청나게 많은 경우의 데이터 포인트를 생성할 수 있음.
⇒ 디코더의 구성 가능한 데이터 포인트가 기하급수적으로 늘어난다
code book learning
code book이 어떻게 학습되는지에 대한 설명이다.
codebook vectors도 encoder / decoder 처럼 gradient descent를 통해서 학습이 된다. 코드를 보면 nn.Embedding을 통해 구성되어 있다.
이 학습에서는 양방향 문제가 존재한다.
codebook 의 vectors가 encoder의 output과 유사해야함  encoder의 output이 codebook vectors와 유사해야함
encoder의 output이 codebook vectors와 유사해야함
encoder의 output이 codebook vectors와 유사해야함이 문제는 다음 loss function으로 해결 가능하다

sg 연산자 : stop gradient. forward 시에는 identity(항등)으로 정의되고 편미분이 0이 되도록하면서 피연산자를 업데이트 되지 않는 상수로 제한한다.
first term : reconstruction loss. decoder가 optimize한다. 코드를 보면 MSE Loss를 통해 구현되었다.
second term : 선택된 code book vector가 encoder의 output에 최대한 가깝도록 한다. encoder가 optimize한다. ⇒ 이 term은 오직 코드북 업데이트에만 적용되기 때문에 에 sg 연산자가 쓰였다.
third term : second term과 유사해 보이는데, code book vector에 sg연산자가 쓰였다. encoder의 output을 codebook vectors에 가깝게 만드는 second term과 반대의 문제를 해결하고자 하는 term이기 때문이다. commitment loss라고 한다.
세번재 term의 중요도는 라는 하이퍼 파라미터를 통해 튜닝된다.
second and third term은 quantized vector output from the model에 의해 average된다.
Prior Distribution
일단 VQ-VAE가 한번 학습이 되면, training 시 사용된 uniform prior은 버릴 수 있다. 그리고 새로운 updated prior 을 latents를 통해 학습한다.
만약 discrete codes의 분포를 정확히 나타내는 prior을 학습한다면 이 prior을 sampling하고 sample을 decoder에 넣어줌으로써 분포로부터 새로운 데이터를 생성할 수 있다.
예를 들어 encoder가 각 데이터포인트에서 latent codes 의 sequence를 출력한다면 prior 학습을 위해 autoregressive model을 사용한다.
⇒ autoregressive model을 통해 시퀀스 내의 이전 latent code로부터 다음 latent code를 예측하는 방식으로 학습한다.
오디오로 예시를 들면, 이 접근은 encoder가 다음 latent가 오디오의 다음 section을 나타내도록 구성되어있다고 가정하는 것이다. convolution을 통해 encoding했다면 이러한 특성이 예측된다.
이미지의 경우에는 latent 32x32 grids를 1d로 펼쳐서 시퀀스가 왼쪽 상단 → 우측 하단으로 이동하도록 하여 autoregressive learning을 수행한다.
Experiments
encoder 구조 : stride 2, window size 4의 strided conv 2개, 2개의 3x3 residual block(ReLU+3x3+ReLU+1x1)
decoder 구조 : 2개의 3x3 residual blocks, 2개의 transposed convs with stride 2 and window size 4
ADAM optimizer with learning rate 2e-4, 250,000 steps training, batch size 128
이미지의 경우 128x128x3의 이미지를 32x32x3으로 복원하는 식으로 학습을 했다. discrete space 크기 k=512로 지정했고 powerful prior로써 PixelCNN을 사용했다.

discretised 32x32x1 latent space에서 PixelCNN을 학습했다.

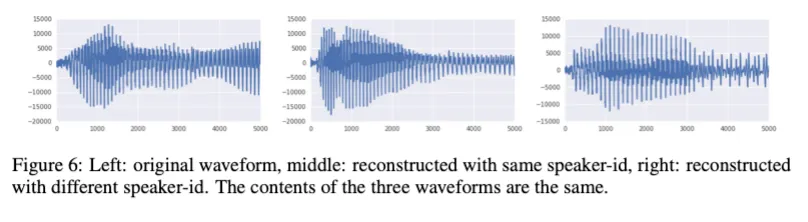
오디오의 경우 WaveNet의 디코더와 유사한 dilated conv구조로 VQ-VAE를 학습시켰다.
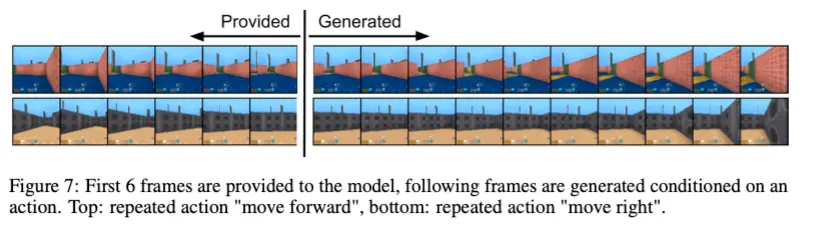
비디오의 경우 DeepMind Lab환경에서 주어진 action sequence를 조건으로 주어 학습시켰다.